Discover -> change index pattern에서 대시보드를 만들 index설정 ->show dates에서 적절한 date범위 조절
Visualization -> create visualization ->시각화하고싶은 방법선택(ex:수직바차트,파이차트) -> data index 를 선택한다> 보이고 싶은 조건에 맞추어 구성
Dashboard -> create dashboard -> create new버튼으로 visualization 새로 생성 or add 버튼눌러서 만들어둔 visualization들 중 선택
Visualization 구성방법
데이터 시각화를 시작하려면 사이드 탐색 메뉴에서 시각화 를 클릭합니다.
시각화 툴을 사용하여 데이터를 다양한 방식으로 볼 수 있습니다.
Pie chart를 사용하여 데이터를 살펴보도록 하겠습니다.
시작하려면 시각화 목록에서 Pie 를 클릭합니다. 기본 검색은 모든 문서에 대해 일치 여부를 비교합니다. 처음에는 하나의 "슬라이스"가 전체 파이를 보여줍니다.
차트에 표시할 슬라이스를 나누려면 Elasticsearch Bucket 집계를 사용합니다. 예를 들어 포트번호 분포를 파이차트로 나눠서 볼수있습니다. 각 포트번호별로 슬라이스하기 위해 다음을 수행합니다.
Aggregation을 선택합니다 개수로 분포를 나누기위해서는 Terms를 사용합니다.
필드 목록에서 포트번호 필드를 선택합니다.
Order 부분에서 Metric:Count를 사용하여 Count를 선택합니다 (개수를 기준으로 삼기 때문)
Order에서 오름차순과 내림차순을 선택해주고 바차트에 보여줄 개수를 고릅니다. 만약 Descending : 5로 선택하면 큰수에서 작은수로 내림차순으로 5개의 프로토콜이 보여지게 됩니다.
만약 뚫린 파이차트가 싫다면 OPtions - Donut부분을 선택해제 해주면 꽉찬 동그라미모양의 파이차트가 됩니다. 또 파이차트옆 내림차순으로 포트번호5개리스트 위치를 바꾸고 싶다면 Legend position - bottom으로 상하좌우 위치를 선택해주면 됩니다.
내림차순이나 오름차순이 아니라 직접 범위를 지정한 버킷을 지정해주고싶다면,
분할 슬라이스 버킷 유형을 클릭합니다.
집계 목록에서 범위 를 선택합니다.
필드 목록에서 해당필드를 선택합니다.
범위 추가로 범위를 직접 지정해줍니다.
.이번엔 Vertical Bar을 사용하여 데이터를 살펴보도록 하겠습니다.(Pie chart의 슬라이스 = x axis 으로 조건을 나누는부분은 동일합니다)
새로 만들기 를 클릭하고 'Vertical Bar’를 선택합니다.
Index 패턴을 선택합니다. 아직 어떤 버킷도 정의하지 않았으므로 커다란 하나의 바가 나타나 총 문서 수를 표시합니다.
Metric 집계의 y-axis에서 개수가 디폴트로 지정되어 있습니다. 만약 Max, Average, Min등 갯수가아닌 기준으로 바차트를 보이고싶다면 선택해줍니다. 예시에서는 count를 선택하였습니다.
X축을 설정해주기위해서는 Bucket -> X-axis을 선택한다음 agrregation에서 Terms을 선택해줍니다. 파이차트와 바차트에서는 주로 갯수를 보기위해 많이쓰이므로 대부분 Terms를 사용합니다.
앞서 보았던 파이차트와 동일하게 Order by, Order를 지정해줍니다. (만약 갯수가 아니라 알파벳순으로 나열하고싶다면 order by: Alphabetical로 설정해줍니다.
만약 , 바차트에서 두가지 필드를 보고싶다면 , 예를들어 목적지 포트번호를 내림차순으로 5개가 있는데 80번포트번호의 attatckType 구성을 보고싶다면
Buckets 에서 추가버튼클릭 -> Split series -> Terms -> AccidentType필드선택 -> order by: count-> 내림차순 으로 원하는 갯수 지정해주면 됩니다.
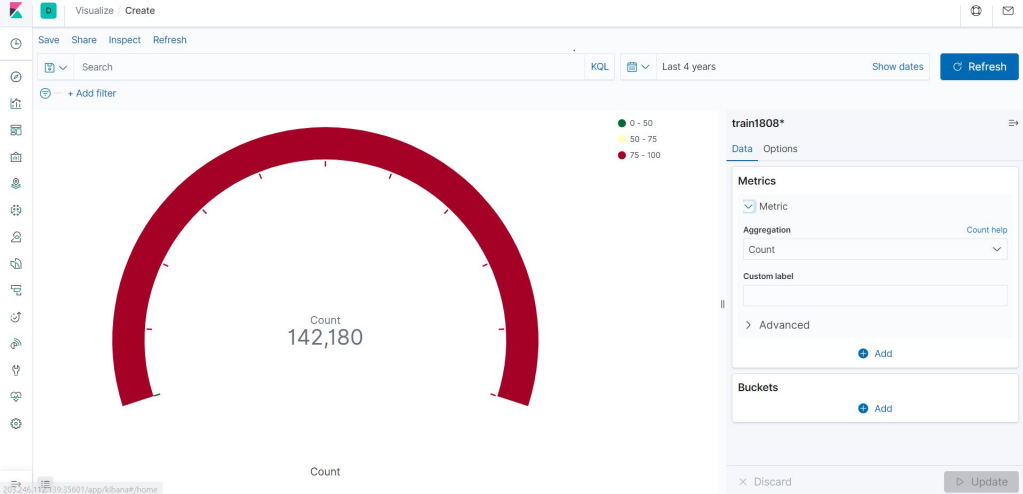
.데이터 총갯수나, 필드값에서 가장많은 값을 단편적으로 알고싶다면 gauge를 활용합니다.
생성하기를 누르면 디폴트로 해당 index의 총 데이터 갯수가 나타나게 됩니다.
이것은 데이터의 총 개수나 퍼센테이지를 나타내는데 주로 쓰입니다. 만약, 간단하게 어떤 필드값이 가장 많은지 단편적으로 보고싶다면
Metric -> aggregtaion : Max로 설정해준다음
필드를 선택합니다 (attackType)
옵션에서 Range를 설정해줍니다.
또 각 필드별로 퍼센티지를 보고싶다면
Metric -> aggregtaion : Max로 설정해준다음
필드를 선택합니다 (attackType)
옵션에서 Range를 설정해줍니다.
Buckets 에서 agrregtaion: Terms 선택
필드는 같은것으로 선택 (attackType)
Order by 의 size개수를 변경하여 보여질 Guage 갯수를 지정
Tag Cloud는 가장 많은 필드들을 추려 보여줍니다.
Metrics : count
Buckets에서 Tag를 추가
Aggregation을 terms로 지정해준다음 필드를 선택
가장많은 5가지 내용을 보고싶다면 Descending : 5를 선택
Line 과 Area는 채워져있나 안채워있나의 차이로 생긴것이 매우 흡사합니다. (Line 옵션- Metric -Char type 에서 area로 변경해주면 Area와 Line의 차이가 거의 없습니다.Timestamp별로 데이터 입력 흐름을 볼때 , 전체적인 붆포도를 볼떄 주로 쓰입니다.
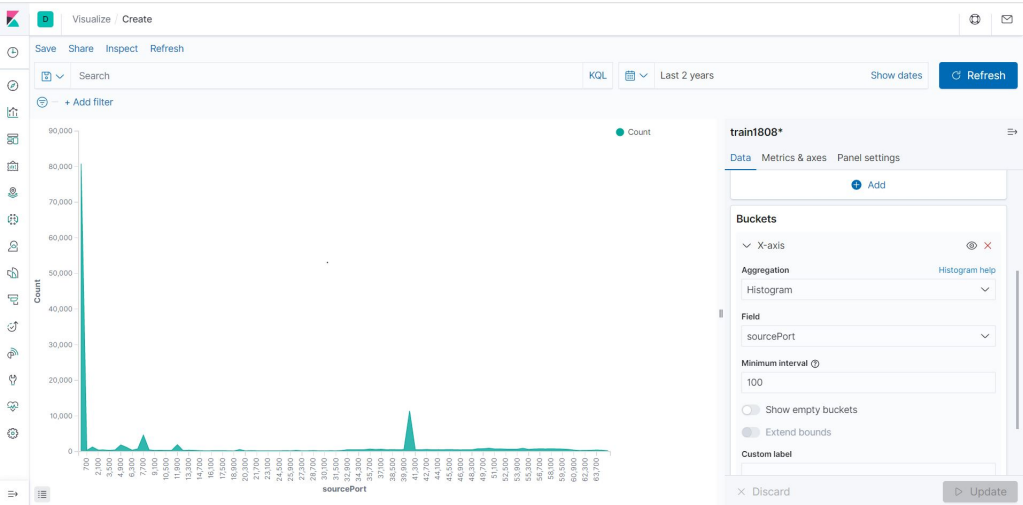
Area에서 전체적인 분포도를 살펴보고 싶다면
Metrics : count
Buckets에서 x-axis추가
Histogram선택
필드선택 ( sourcePort)
interval을 적절히 설정
Line에서 Timestamp별로 발생한 이벤트의 수를 시간대별로 보고싶다면
Metrics : count
Buckets 의 x-axis 누르고 aggregation : Date Histogram선택
필드는 @timestamp로 지정
Minimum interval은 데일리,위클리 적절한것으로 선택.
Lined에서 실시간 음원차트처럼 만들수도 있다. 실시간 input되는 데이터중 attackType이 0,1인경우를 나누어서 보입니다. (attackType은 가짓수가 적지만 가짓수가 많을경우 range말고 내림차순으로해도 괜찮습니다.)
from . import views
from django.urls import path
from django.contrib import admin
urlpatterns = [
path('Logout/',views.Logout),
]
views.py에 추가해줄것.
from django.contrib.auth import authenticate
from django.shortcuts import render
from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
from django.contrib.auth import logout
from django.shortcuts import redirect
from django.contrib.auth.models import User
from django.contrib.auth import login
def Logout(request):
logout(request)
return render(request, 'mainapp/Login.html')
def Login(request):
if request.method == 'POST':
id = request.POST.get('userid','')
pw = request.POST.get('userpw', '')
result = authenticate(username=id, password=pw)
if result :
print("로그인 성공!")
login(request, result)
return render(request, 'mainapp/index.html')
else:
print("실패")
return render(request, 'mainapp/Login.html')
return render(request, 'mainapp/Login.html')
views.py에서 에러나면 저것들을 import해주자.
from django.contrib.auth import authenticate
from django.shortcuts import render
from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
from django.contrib.auth import logout
from django.shortcuts import redirect
from django.contrib.auth.models import User
from django.contrib.auth import login
와디즈 상품 하나하나 클릭해보는 방식으로 열고닫고 방식으로 제목+내용+카테고리 긁어오기 (상품30개만)
와디즈가 무한 스크롤 방식이라 총 상품개수를 알수 없음. -> 클릭은 하지 않고 해당 카테고리 상품리스트를 훝는 방식으로 제목+ 상품url 긁어와서 전체 상품 리스트를 만듬(총몇개인가 확인)
스크롤을 바닥까지 끌어온다음(30초) 1번 방식으로 하나하나 클릭했다 뒤로갔다 반복하면서 전체 긁어오기 --> (치명적인 문제점 발생 )미친듯이 느리다
속도개선 -> (((((((((((( IP 차단당함 )))))))))))))) (ip 우회전에는 120개쯤 긁어오면 귀신같이 연결이 끊어졌는데 ip우회 후에는 300-500개쯤 긁어오면 끊겼다...)
IP우회 + 멀티프로세서 사용 + (2)에서 만든 상품리스트 url을 리스트로 불러와 차례차례 접근 +속도 개선조건들 추가
time.sleep()을 0.3초로 빨리 하면 빨리 긁어오는데 미처 못긁어온 결측치 데이터가 많이지고(3000개중 1000개 title,body 군데군데 누락) 1분정도로 하면 놓치는 데이터가 현저히 줄어드는대신 속도가 많이 느려진다... 누락된데이터를 다시 모아서 마지막으로 한번더 돌려준다.
import time
wadiz_body=[]
wadiz_title=[]
wadiz_category=[]
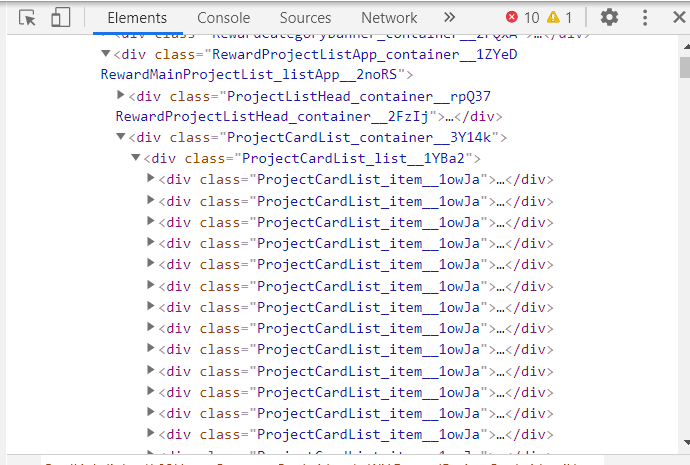
table = driver.find_element_by_class_name('ProjectCardList_container__3Y14k') #상품들을 포함하는 껍데기 클래스(위사진참조)
rows = table.find_elements_by_class_name("ProjectCardList_item__1owJa") # 열 하나=상품하나 (위사진참조)
#똑같은 클래스네임가진 열들 줄줄이 많이존재(위사진참조)
for i in range(1,31): #30번만 실행
table = driver.find_element_by_class_name('ProjectCardList_container__3Y14k') #표 전체
rows = table.find_elements_by_class_name("ProjectCardList_item__1owJa")
rows = table.find_elements_by_class_name("ProjectCardList_item__1owJa")[i]
rows.click()
time.sleep(3)
# 본문내용 긁어서 list인 wadiz_body에 집어넣기
#https://stackoverflow.com/questions/49900117/python-selenium-list-object-has-no-attribute-text-error?noredirect=1&lq=1
body = driver.find_elements_by_xpath(f'//*[@id="introdetails"]/div') #본문내용 xpath, 마우스 우클릭 copy-xpath복사
for value in body: #body가 <P></P>형태로 굉장히 줄줄이 있어서 for문으로 해결
#print(value.text)
wadiz_body.append(value.text) #리스트에 줄줄이 집어넣기
# 제목내용 긁어서 wadiz_title에 집어넣기
title = driver.find_element_by_xpath(f'//*[@id="container"]/div[3]/h2/a') #제목 xpath
wadiz_title.append(title.text)
#카테고리 긁어서 wadiz_category에 집어넣기
category = driver.find_element_by_xpath(f'//*[@id="container"]/div[3]/p') #카테고리 Xpath
wadiz_category.append(category.text)
time.sleep(2)
button = driver.find_element_by_class_name('back-btn')
button.click()
time.sleep(2)
timesleep(3)으로 했더니 너무 느려서 0.3이나 0.2정도 해주는것이 적당하다.
import pandas as pd
import numpy as np
df1=pd.DataFrame({'title':wadiz_title,'body':wadiz_body,'category':wadiz_category})
# wadiz_title, wadiz_body, wadiz_category이렇게 3개의 열을 가진 표를 dataFrame으로 만든다
df1
table = driver.find_element_by_class_name('ProjectCardList_container__3Y14k') #표 전체
rows = table.find_elements_by_class_name("ProjectCardList_item__1owJa")[5]
#똑같은 클래스 이름 가진 열들중 6번째 열, 즉 6번째 상품 클릭
rows.click()
import time
try:
for i in range(1000000000000):
button = driver.find_element_by_xpath(f'//*[@id="main-app"]/div[2]/div/div[5]/div[2]/div[2]/div/button') #더보기버튼 xpath
time.sleep(0.3)
driver.execute_script("arguments[0].click();", button) #click()으로 에러가나서 써줌
except :
button = driver.find_element_by_class_name
button.click()
#다된거같은데 끝이안나면 그냥 중지눌러주면 된다
table = driver.find_element_by_class_name('ProjectCardList_container__3Y14k') #표 전체
rows = table.find_elements_by_class_name("ProjectCardList_item__1owJa")
for index, value in enumerate(rows): #enumerate는 리스트가 있는 경우 순서와 리스트의 값을 전달하는 기능
title=value.find_element_by_class_name("CommonCard_title__1oKJY")
wadiz_title.append(title.text)
url=value.find_element_by_class_name("CardLink_link__1k83H")
url1=value.get_attribute('href')
wadiz_url.append(url1)
time.sleep(0.3)
import pandas as pd
import numpy as np
df1=pd.DataFrame({'title':wadiz_title}) # 열이름을 title로 해주고 표형식으로 보기좋게 만듬
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
for i in range(1):
chrome_options = Options()
chrome_options.add_argument("--proxy-server=socks5://127.0.0.1:9150")
driver = webdriver.Chrome(executable_path=' 내 PATH ', options=chrome_options)
driver.get('웹사이트')
(2)에서 받아와 저장해둔 url.csv를 다시 불러와서 리스트로 만들어준다.
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
data = pd.read_csv("./wadiz_title_url_f.csv")
data2=data['url']
one = data2.values.tolist()
# one이라는 이름의 url 리스트 생성완료 / one 치고 실행해보면 리스트안에 url들 잘들어갔나 확인가능하다
len(one) #3000여개가 나온다
#이부분은 한꺼번에가 아닌 나눠서 크롤링하려고 만들었다.
#네트워크 상태에 따라서 120개 긁고 멈출때도 있고 500여개 긁고 멈춘일이 매우 다반사라서
#구간을 정해놓고 긁어오기를 시도한다. 중간에 끊기면 Two 리스트 구간만 바꿔서 다시 시도해주면 된다
#중간중간 끊어서 실행해주면 봇으로 의심받아서 차단당할 확률도 줄어든다
two=[]
two=one[464:900]
import requests
import time
from multiprocessing import Pool # Pool import하기
def mul():
for i in two :
driver.get(i)
time.sleep(0.4)
# 본문내용
#https://stackoverflow.com/questions/49900117/python-selenium-list-object-has-no-attribute-text-error?noredirect=1&lq=1
body = driver.find_elements_by_xpath(f'//*[@id="introdetails"]/div')
for value in body:
#print(value.text)
wbody.append(value.text)
# 제목
title = driver.find_element_by_xpath(f'//*[@id="container"]/div[3]/h2/a')
wtitle.append(title.text)
#카테고리
#category = driver.find_element_by_xpath(f'//*[@id="container"]/div[3]/p')
#wadiz_category.append(category.text)
url = driver.current_url
wurl.append(url)
if __name__=='__main__':
pool = Pool(processes=32) # 32개의 프로세스를 사용합니다.
pool.map(mul()) # mul 함수를 넣어줍시다.
len(wurl)
len(wbody)
len(wtitle)
#세명령어로 3개숫자가 같은지 확인 -> 숫자가 같지않으면 표가 만들어지지않음
# csv파일로 저장저장~
import pandas as pd
import numpy as np
import csv
df1=pd.DataFrame({'title':wtitle,'body':wbody,'url':wurl})
df1.to_csv("wadiz_1.csv", mode='w',encoding='utf-8-sig')
5. 결측치데이터 모아서 다시 돌려주기
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
data1 = pd.read_csv("./wadiz_1.csv")
data2 = pd.read_csv("./wadiz_2.csv")
data3 = pd.read_csv("./wadiz_3.csv")
data4 = pd.read_csv("./wadiz_4.csv")