- 이건 300ms 마다 모든 항목 저장
nvidia-smi -lms 300 -f ./Data.csv --format=csv --query-gpu=timestamp,driver_version,count,name,serial,uuid,pci.bus_id,pci.domain,pci.bus,pci.device,pci.device_id,pci.sub_device_id,pcie.link.gen.current,pcie.link.gen.max,pcie.link.width.current,pcie.link.width.max,index,display_mode,display_active,persistence_mode,accounting.mode,accounting.buffer_size,driver_model.current,driver_model.pending,vbios_version,inforom.img,inforom.oem,inforom.ecc,inforom.pwr,gom.current,gom.pending,fan.speed,pstate,clocks_throttle_reasons.supported,clocks_throttle_reasons.active,clocks_throttle_reasons.gpu_idle,clocks_throttle_reasons.applications_clocks_setting,clocks_throttle_reasons.sw_power_cap,clocks_throttle_reasons.hw_slowdown,memory.total,memory.used,memory.free,compute_mode,utilization.gpu,utilization.memory,ecc.mode.current,ecc.mode.pending,ecc.errors.corrected.volatile.device_memory,ecc.errors.corrected.volatile.register_file,ecc.errors.corrected.volatile.l1_cache,ecc.errors.corrected.volatile.l2_cache,ecc.errors.corrected.volatile.texture_memory,ecc.errors.corrected.volatile.total,ecc.errors.corrected.aggregate.device_memory,ecc.errors.corrected.aggregate.register_file,ecc.errors.corrected.aggregate.l1_cache,ecc.errors.corrected.aggregate.l2_cache,ecc.errors.corrected.aggregate.texture_memory,ecc.errors.corrected.aggregate.total,ecc.errors.uncorrected.volatile.device_memory,ecc.errors.uncorrected.volatile.register_file,ecc.errors.uncorrected.volatile.l1_cache,ecc.errors.uncorrected.volatile.l2_cache,ecc.errors.uncorrected.volatile.texture_memory,ecc.errors.uncorrected.volatile.total,ecc.errors.uncorrected.aggregate.device_memory,ecc.errors.uncorrected.aggregate.register_file,ecc.errors.uncorrected.aggregate.l1_cache,ecc.errors.uncorrected.aggregate.l2_cache,ecc.errors.uncorrected.aggregate.texture_memory,ecc.errors.uncorrected.aggregate.total,retired_pages.single_bit_ecc.count,retired_pages.double_bit.count,retired_pages.pending,temperature.gpu,power.management,power.draw,power.limit,power.default_limit,power.min_limit,power.max_limit,clocks.current.graphics,clocks.current.sm,clocks.current.memory,clocks.applications.graphics,clocks.applications.memory,clocks.default_applications.graphics,clocks.default_applications.memory,clocks.max.graphics,clocks.max.sm,clocks.max.memory
더보기
nvidia-smi -lms 300 -f ./Data.csv --format=csv --query-gpu=timestamp,driver_version,count,name,serial,uuid,pci.bus_id,pci.domain,pci.bus,pci.device,pci.device_id,pci.sub_device_id,pcie.link.gen.current,pcie.link.gen.max,pcie.link.width.current,pcie.link.width.max,index,display_mode,display_active,persistence_mode,accounting.mode,accounting.buffer_size,driver_model.current,driver_model.pending,vbios_version,inforom.img,inforom.oem,inforom.ecc,inforom.pwr,gom.current,gom.pending,fan.speed,pstate,clocks_throttle_reasons.supported,clocks_throttle_reasons.active,clocks_throttle_reasons.gpu_idle,clocks_throttle_reasons.applications_clocks_setting,clocks_throttle_reasons.sw_power_cap,clocks_throttle_reasons.hw_slowdown,memory.total,memory.used,memory.free,compute_mode,utilization.gpu,utilization.memory,ecc.mode.current,ecc.mode.pending,ecc.errors.corrected.volatile.device_memory,ecc.errors.corrected.volatile.register_file,ecc.errors.corrected.volatile.l1_cache,ecc.errors.corrected.volatile.l2_cache,ecc.errors.corrected.volatile.texture_memory,ecc.errors.corrected.volatile.total,ecc.errors.corrected.aggregate.device_memory,ecc.errors.corrected.aggregate.register_file,ecc.errors.corrected.aggregate.l1_cache,ecc.errors.corrected.aggregate.l2_cache,ecc.errors.corrected.aggregate.texture_memory,ecc.errors.corrected.aggregate.total,ecc.errors.uncorrected.volatile.device_memory,ecc.errors.uncorrected.volatile.register_file,ecc.errors.uncorrected.volatile.l1_cache,ecc.errors.uncorrected.volatile.l2_cache,ecc.errors.uncorrected.volatile.texture_memory,ecc.errors.uncorrected.volatile.total,ecc.errors.uncorrected.aggregate.device_memory,ecc.errors.uncorrected.aggregate.register_file,ecc.errors.uncorrected.aggregate.l1_cache,ecc.errors.uncorrected.aggregate.l2_cache,ecc.errors.uncorrected.aggregate.texture_memory,ecc.errors.uncorrected.aggregate.total,retired_pages.single_bit_ecc.count,retired_pages.double_bit.count,retired_pages.pending,temperature.gpu,power.management,power.draw,power.limit,power.default_limit,power.min_limit,power.max_limit,clocks.current.graphics,clocks.current.sm,clocks.current.memory,clocks.applications.graphics,clocks.applications.memory,clocks.default_applications.graphics,clocks.default_applications.memory,clocks.max.graphics,clocks.max.sm,clocks.max.memory
- 이건 1초마다 모든항목 저장
nvidia-smi -l 1 -f ./Data.csv --format=csv --query-gpu=timestamp,driver_version,count,name,serial,uuid,pci.bus_id,pci.domain,pci.bus,pci.device,pci.device_id,pci.sub_device_id,pcie.link.gen.current,pcie.link.gen.max,pcie.link.width.current,pcie.link.width.max,index,display_mode,display_active,persistence_mode,accounting.mode,accounting.buffer_size,driver_model.current,driver_model.pending,vbios_version,inforom.img,inforom.oem,inforom.ecc,inforom.pwr,gom.current,gom.pending,fan.speed,pstate,clocks_throttle_reasons.supported,clocks_throttle_reasons.active,clocks_throttle_reasons.gpu_idle,clocks_throttle_reasons.applications_clocks_setting,clocks_throttle_reasons.sw_power_cap,clocks_throttle_reasons.hw_slowdown,memory.total,memory.used,memory.free,compute_mode,utilization.gpu,utilization.memory,ecc.mode.current,ecc.mode.pending,ecc.errors.corrected.volatile.device_memory,ecc.errors.corrected.volatile.register_file,ecc.errors.corrected.volatile.l1_cache,ecc.errors.corrected.volatile.l2_cache,ecc.errors.corrected.volatile.texture_memory,ecc.errors.corrected.volatile.total,ecc.errors.corrected.aggregate.device_memory,ecc.errors.corrected.aggregate.register_file,ecc.errors.corrected.aggregate.l1_cache,ecc.errors.corrected.aggregate.l2_cache,ecc.errors.corrected.aggregate.texture_memory,ecc.errors.corrected.aggregate.total,ecc.errors.uncorrected.volatile.device_memory,ecc.errors.uncorrected.volatile.register_file,ecc.errors.uncorrected.volatile.l1_cache,ecc.errors.uncorrected.volatile.l2_cache,ecc.errors.uncorrected.volatile.texture_memory,ecc.errors.uncorrected.volatile.total,ecc.errors.uncorrected.aggregate.device_memory,ecc.errors.uncorrected.aggregate.register_file,ecc.errors.uncorrected.aggregate.l1_cache,ecc.errors.uncorrected.aggregate.l2_cache,ecc.errors.uncorrected.aggregate.texture_memory,ecc.errors.uncorrected.aggregate.total,retired_pages.single_bit_ecc.count,retired_pages.double_bit.count,retired_pages.pending,temperature.gpu,power.management,power.draw,power.limit,power.default_limit,power.min_limit,power.max_limit,clocks.current.graphics,clocks.current.sm,clocks.current.memory,clocks.applications.graphics,clocks.applications.memory,clocks.default_applications.graphics,clocks.default_applications.memory,clocks.max.graphics,clocks.max.sm,clocks.max.memory
더보기
nvidia-smi -l 1 -f ./Data.csv --format=csv --query-gpu=timestamp,driver_version,count,name,serial,uuid,pci.bus_id,pci.domain,pci.bus,pci.device,pci.device_id,pci.sub_device_id,pcie.link.gen.current,pcie.link.gen.max,pcie.link.width.current,pcie.link.width.max,index,display_mode,display_active,persistence_mode,accounting.mode,accounting.buffer_size,driver_model.current,driver_model.pending,vbios_version,inforom.img,inforom.oem,inforom.ecc,inforom.pwr,gom.current,gom.pending,fan.speed,pstate,clocks_throttle_reasons.supported,clocks_throttle_reasons.active,clocks_throttle_reasons.gpu_idle,clocks_throttle_reasons.applications_clocks_setting,clocks_throttle_reasons.sw_power_cap,clocks_throttle_reasons.hw_slowdown,memory.total,memory.used,memory.free,compute_mode,utilization.gpu,utilization.memory,ecc.mode.current,ecc.mode.pending,ecc.errors.corrected.volatile.device_memory,ecc.errors.corrected.volatile.register_file,ecc.errors.corrected.volatile.l1_cache,ecc.errors.corrected.volatile.l2_cache,ecc.errors.corrected.volatile.texture_memory,ecc.errors.corrected.volatile.total,ecc.errors.corrected.aggregate.device_memory,ecc.errors.corrected.aggregate.register_file,ecc.errors.corrected.aggregate.l1_cache,ecc.errors.corrected.aggregate.l2_cache,ecc.errors.corrected.aggregate.texture_memory,ecc.errors.corrected.aggregate.total,ecc.errors.uncorrected.volatile.device_memory,ecc.errors.uncorrected.volatile.register_file,ecc.errors.uncorrected.volatile.l1_cache,ecc.errors.uncorrected.volatile.l2_cache,ecc.errors.uncorrected.volatile.texture_memory,ecc.errors.uncorrected.volatile.total,ecc.errors.uncorrected.aggregate.device_memory,ecc.errors.uncorrected.aggregate.register_file,ecc.errors.uncorrected.aggregate.l1_cache,ecc.errors.uncorrected.aggregate.l2_cache,ecc.errors.uncorrected.aggregate.texture_memory,ecc.errors.uncorrected.aggregate.total,retired_pages.single_bit_ecc.count,retired_pages.double_bit.count,retired_pages.pending,temperature.gpu,power.management,power.draw,power.limit,power.default_limit,power.min_limit,power.max_limit,clocks.current.graphics,clocks.current.sm,clocks.current.memory,clocks.applications.graphics,clocks.applications.memory,clocks.default_applications.graphics,clocks.default_applications.memory,clocks.max.graphics,clocks.max.sm,clocks.max.memory




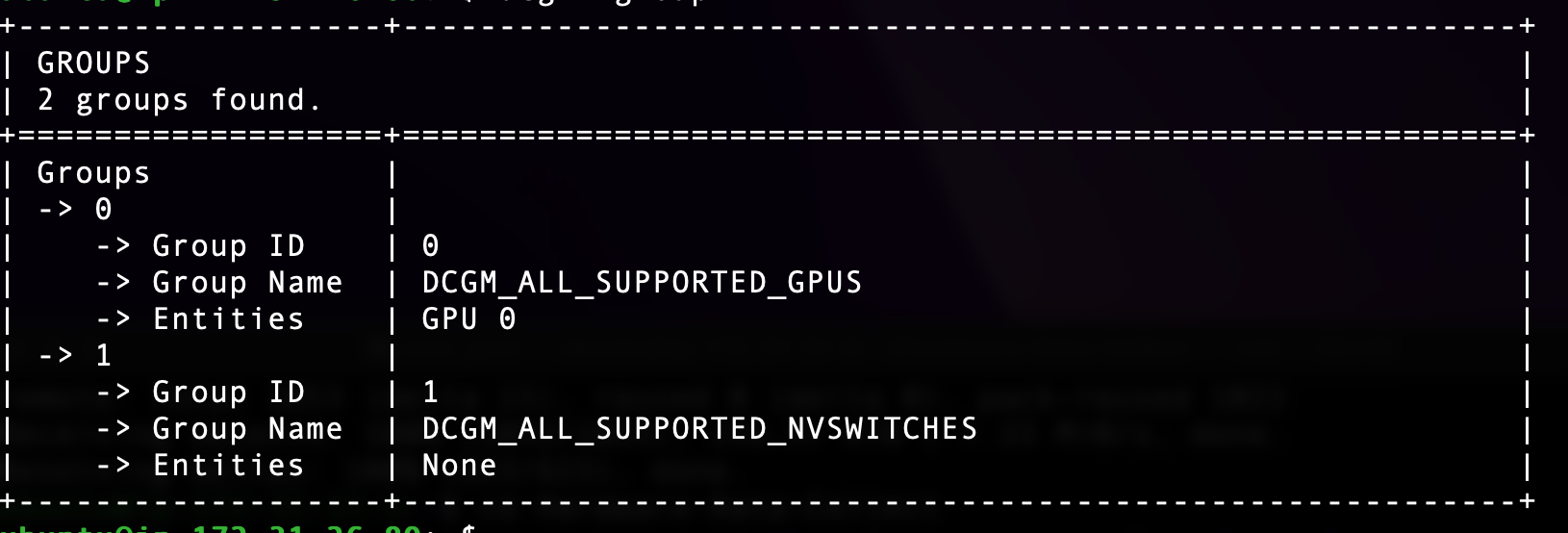
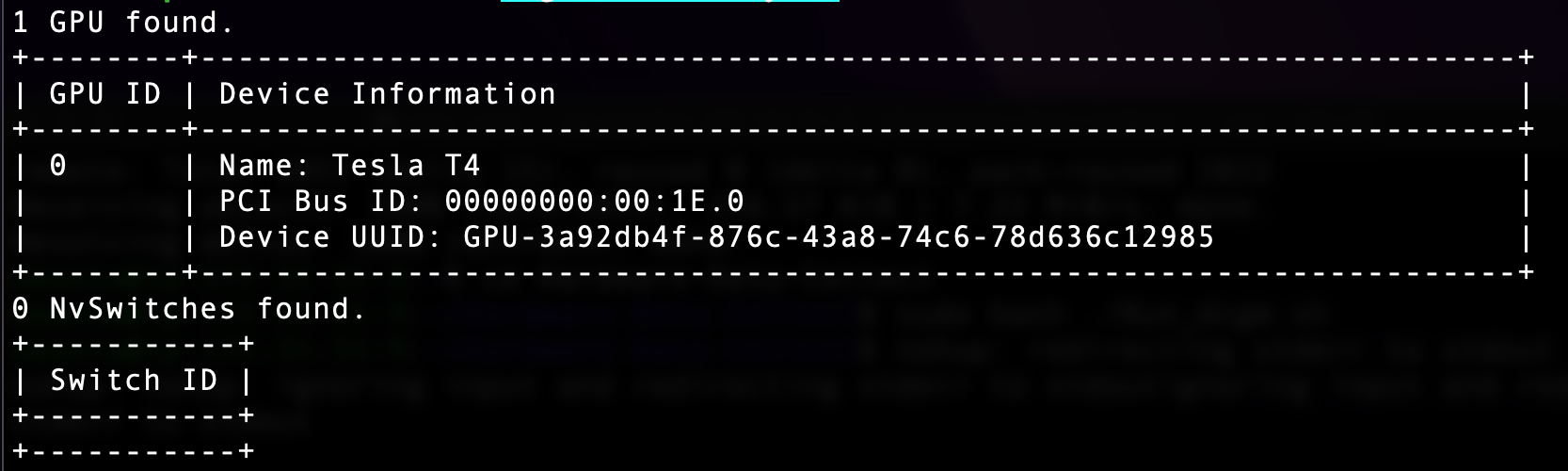
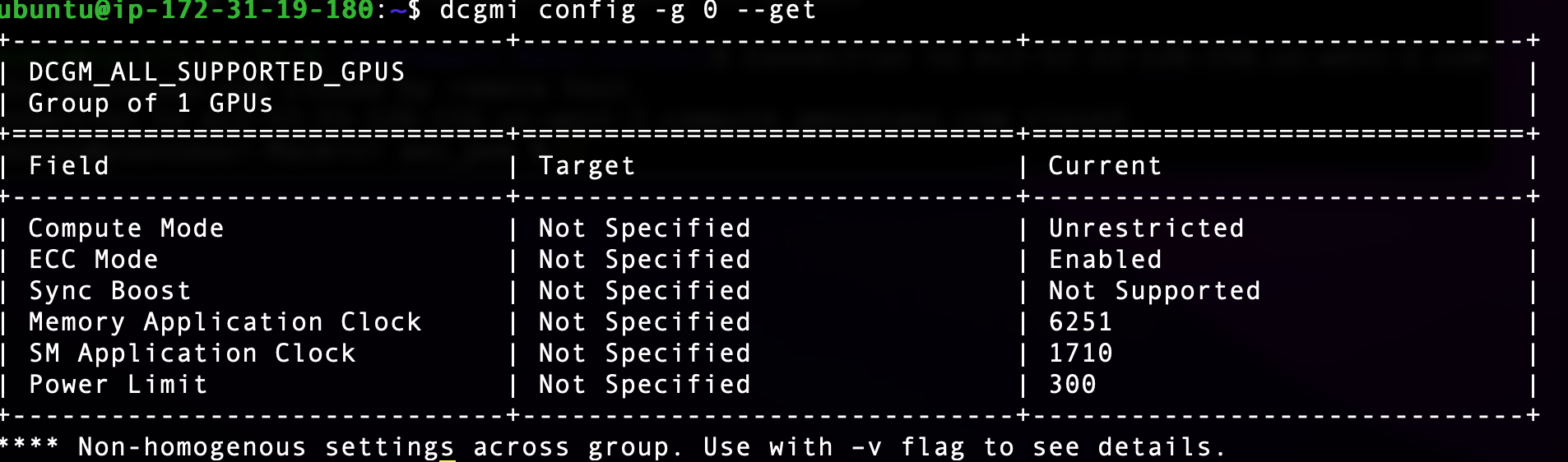
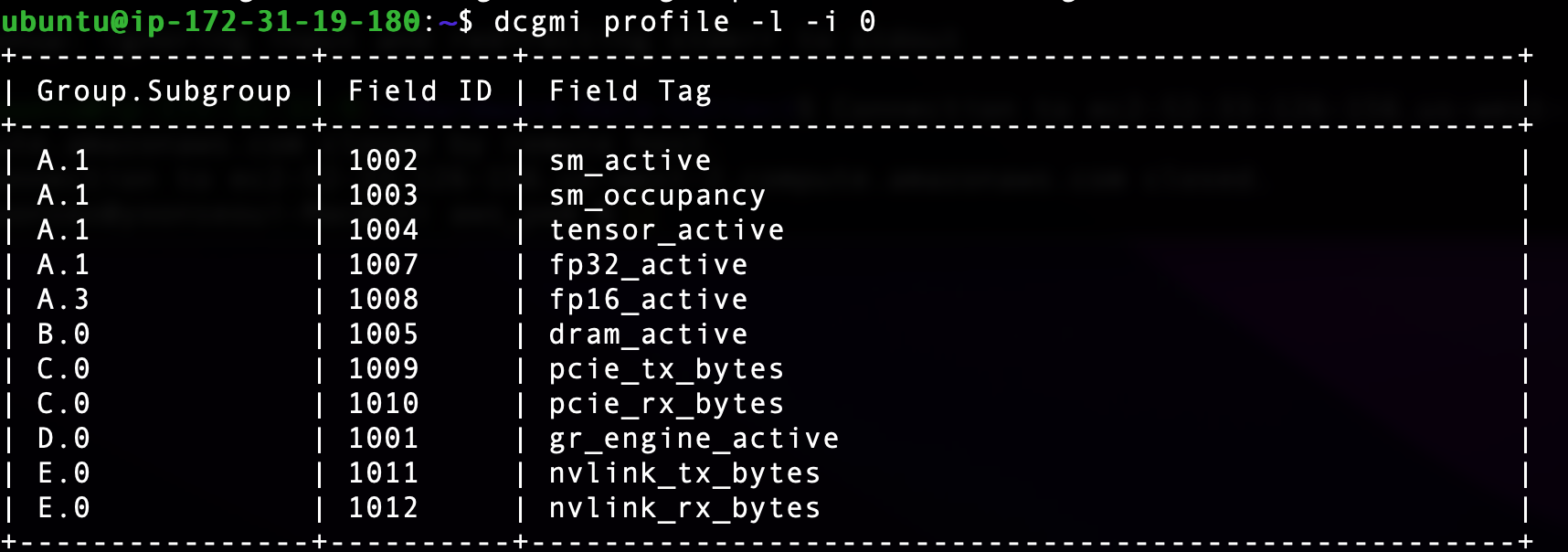
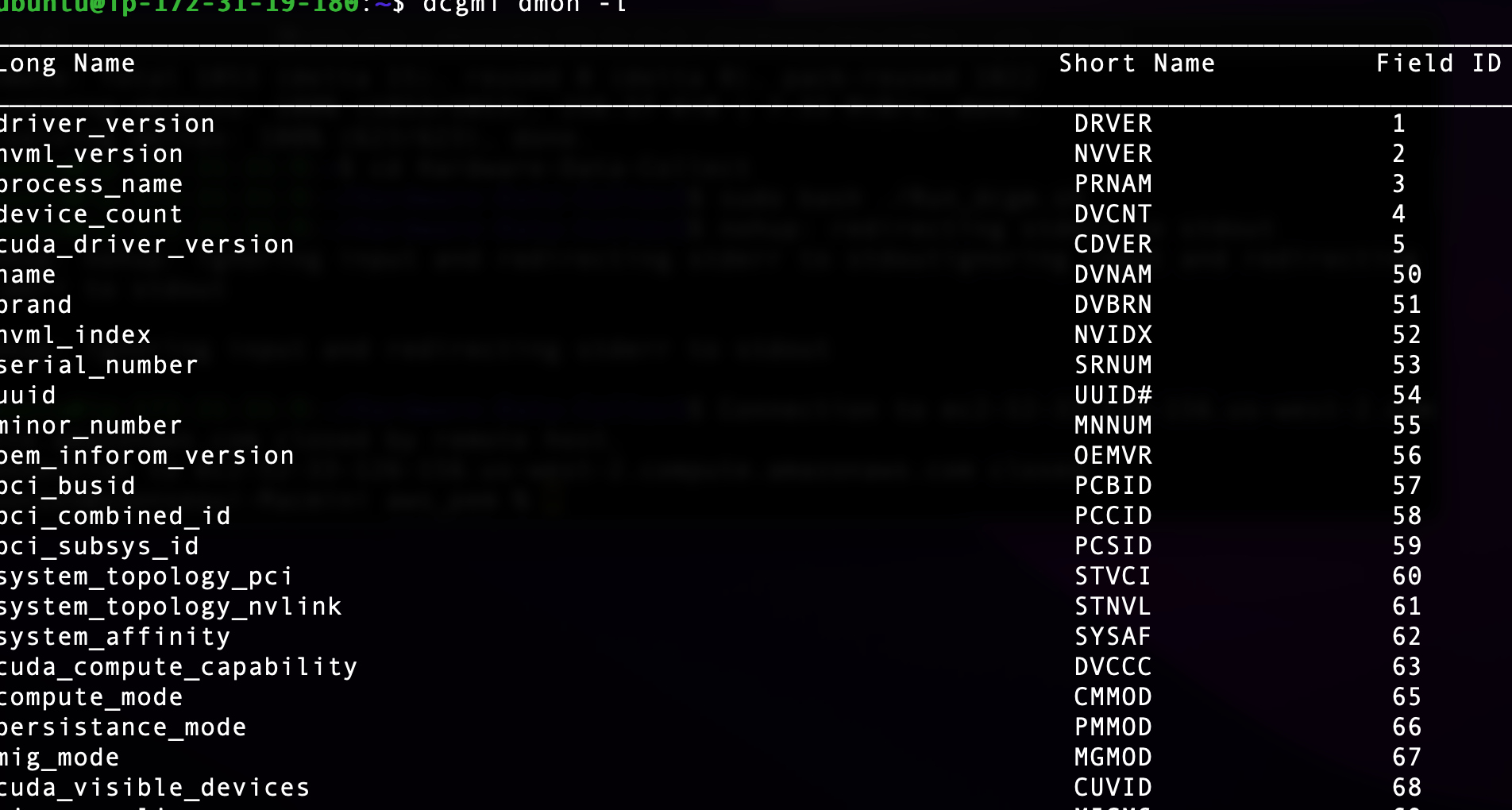
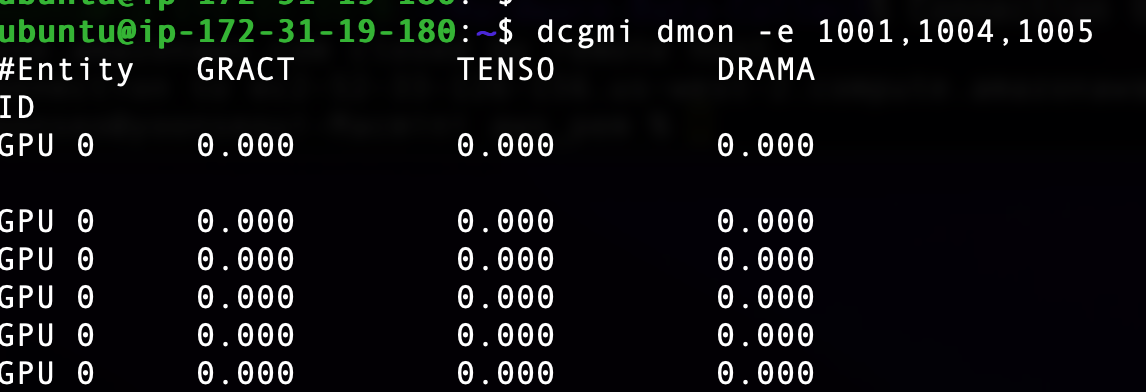
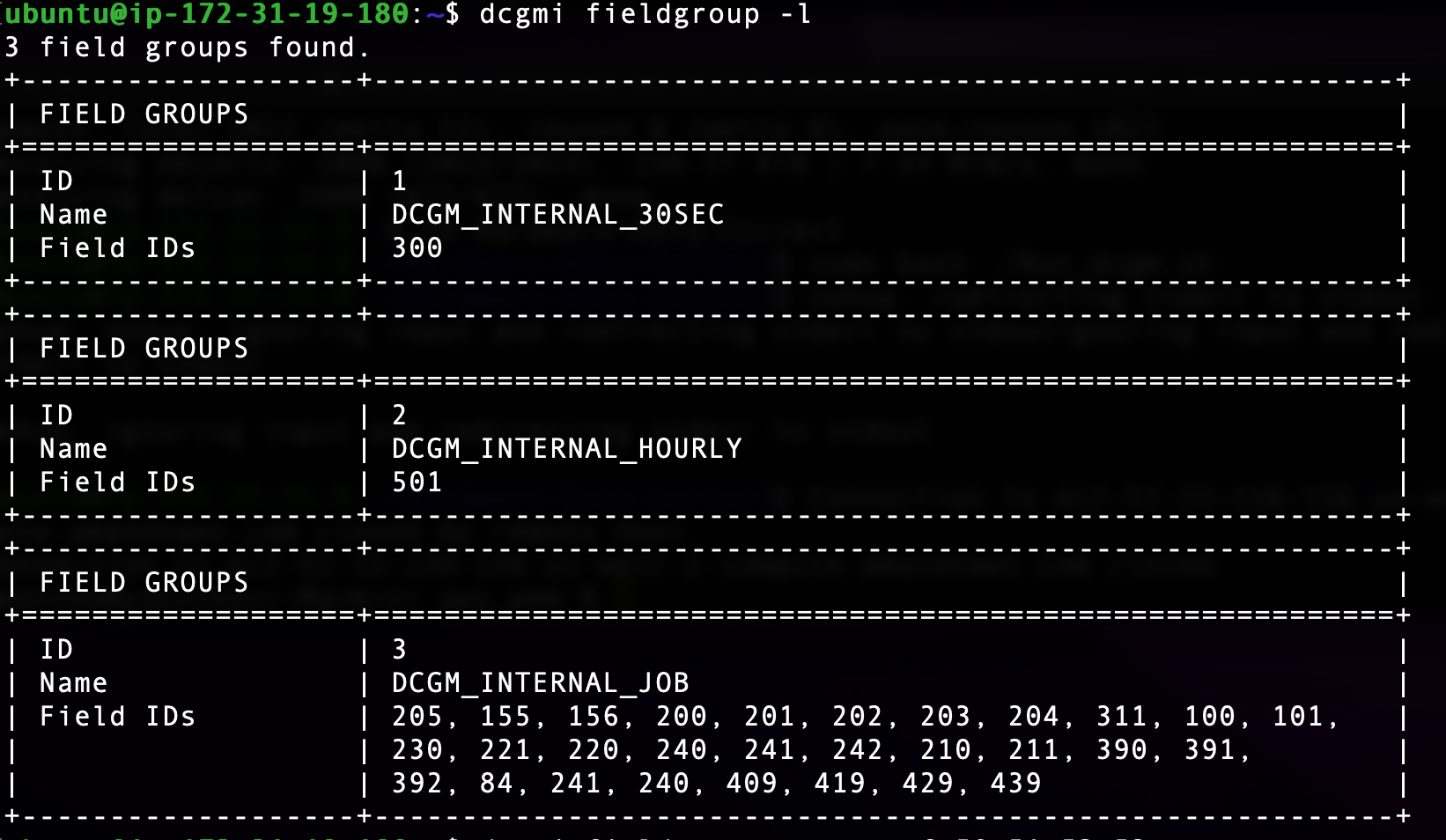
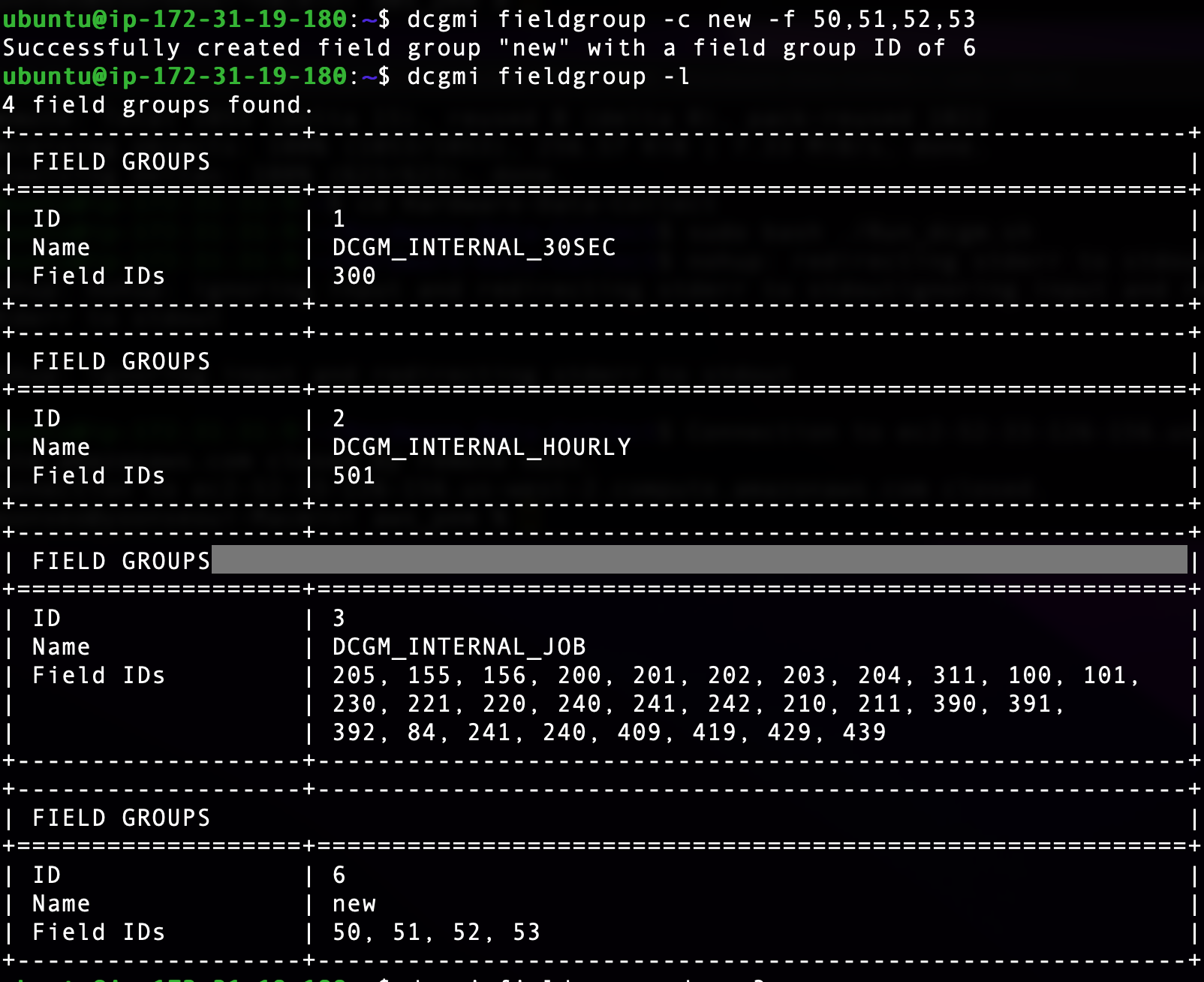
















Uploaded by Notion2Tistory v1.1.0