Udemy 강의 내용 정리한것
【한글자막】 15일 완성 코스 - Power BI 완벽 부트캠프 | Udemy
- 강의는 POWER BI Desktop 기준으로 진행
- POWER BI Desktop 에서 만든걸 pbix 저장한다음, Fabric Power BI에 올려서 진행하는 방식으로 실습 진행함( Desktop 강의서가 더 많고, Fabric Power Bi에서 제약이 너무 많기 때문 )
- 조직계정외 개인개정으로 Fabric Power BI는 AZURE 무료계정만들기 => Microsoft 계정만들기로 진행가능
- Desktop-> Fabric Power BI 옮기려면 템플릿NONO POWER BI 문서로 저장해야함
- DESKTOP에서 작업한것 save as -> one drive -> 맽밑에 pbix 이름지정 -> save 그런다음에 웹 fabric Power BI드가서 업로드-> 저장한 원드라이브 위치에 드가서 업로드한 파일 선택 하면 정상적으로 (데이터+대시보드)가 업데이트 됨
DAY2 : 데이터 전처리를 POWER BI 안에서 진행할수 있음
1. 데이터 수정은 Home - Transform data 눌러서 진행
- error 종종 뜰땐 텍스트로 바꾼다음 home - replae value 누른다음 NA 값을 없는값으로 만들어주기, 그리고 숫자로 바꿔주면 null로 바뀜
2. column 안에 너무 정보가 많을때 아래 잘 조합해서 쪼개기
- Transform - split colum
- by position 로 0,3,5 이렇게 나눠주면 TX - Montgomery 이게 3개 COLUMN으로 쪼개진다.
- Split Column by Delimiter로 [ - ]를 넣어주면 2개 COLUMN으로 쪼개진다
- Transform - Extract
3. 앞뒤 공백 없애주기 : Column 마우스 우클릭 - Transform - Trim 앞뒤 공백 없애줌, Clean은 탭키 공백들도 없애줌
- 모든 컬럼 대문자로 시작하게 : 마우스 우클릭 - Transform - Capitalize Each Word
4. 소숫점 없애기
- 열 마우스 우클릭 - change type - whole number
5. 열 전체 합같은 연산하기
- Transform - Statistics - SUM
열의 모든값을 합친 값만 output으로 내놓지 활용할거리가 하나도 없다.
6. 모든 열에 모두 100 더해주기, 모든열에 해당하는 값 연산, cm을 인치로 바꾸기 (=단위 변환하기)
- Transform - Standard - Add - 100 ( 모든 열에 100을 더해줌)
- Transform - Standard - Multiply(곱셈) - 0.394(cm에서 인치로 변환하기위해 곱해줌)
29,30 강의 다시듣기
8. 파이차트 주의할점 (앵간하면 비추함)
- 최악의 경우
- 비슷비슷한값들의 경우 비교할때 파이차트를 사용하면 안됨 (심지어 비슷한 비율의 파이차트 두개를 보여준다? 최악)
- 값이 너무 많은경우 비추함(항목이 2,3개일때만 사용하고, 항목이 5개를 초과할경우 절대 쓰지 말라고함) / 값이 너무 많은경우엔 세로 막대그래프를 권장함
- 파이차트를 권장하는 경우 / 사용 권장 방식
- 파이차트는 전체에서 차지하는 비율(퍼센테이지)을 전시할때만 사용하라고 권장함. (총합 100퍼센트를 이루는것만 해당)
- 과반수를 이루는것만 색깔 칠하기 등..
- 파이차트에서 범례 쓰지말고 걍 원위에 항목 표시하기 (한눈에 안들어옴)
- 디테일한 사용 방식
- 범례 표위에 표시하는법 detail labels 에서 설정
DAY3 : 본격적인 시각화 툴 활용
- 두개 데이터 연결하기
- 1. 1개 테이블뒤에 다른 테이블 붙이기
- 2. append queries 로 새 테이블 만들기 (3개이상 연결)
- if ) 연결하려는 두개 테이블의 column 명이 다를경우, a,b를 합쳐서 c를 만들었을경우 걍 a테이블로 돌아가서 컬럼명을 바꾸고 다시 c로 돌아와서 보면 알아서 고쳐져있음 (파워비아이의 장점!)
- 데이터 타입 자동으로 바꾸기 ( 일일히 수동으로 변경하지 않아도 됨)
- Transform - detect data type
DAY4 : 데이터 변환
- 대시보드 필터 기능 (slicer)
- 여러개 선택하고 싶으면 ctrl 누르고 선택하면 됨
- ctrl 없이 여러개 누르고 싶으면 format - selection controls - Multi select with CTRL 활성화를 끄면됨
DAY5 : 대화형 시각화
- 오른쪽 메뉴 필터 slicer (그래프,페이지,전체등 범위선택가능)
- filer on this visul 한정으로 topN기능 사용가능
- 여러페이지에서 동일 필터를 먹이는 방법 (sync slicers)
- 1. slicer 를 복사 붙여넣기한다음 - 동기화하겠습니까? 묻는거에 YES
- 2. slicer를 더블클릭하면 sync slicers 라고 오른쪽에 새로 뜨는 페이지를 클릭해서 어느 페이지에서 보여줄것인지 체크창에 체크표시하면 됨 (동기화와, slicer보임여부를 표시할 수 있음)
- 트리맵 시각화 (tree map)
- 항목이 너무 많아서 막대그래프로 나타내도 스크롤이 줄질 않으면 트리맵을 추천 (위계적인 데이터에 추천)
- 스크롤 없이 한눈에 보기 가능
- 하지만 수치가 표시되는건 아니라 데이터라벨 추가해주면 좋음 format -
- detail 에 서브카테고리 컬럼을 추가해주면, 같은색안에 칸이 나뉘면서 그안의 서브카테고리들을 보여줌
- 드릴스루
- 테이블에서 예를들어 0이상만 보여주고 싶을경우 Filters 에서 자세히 지정해주면 됨
- 드릴스루로 더 자세히 봐줄 column을 지정해주면 드릴스루 메뉴가 뜸
- 말풍선 (마우스 커서 가져다 대면 뜨는거)
- visualizations - build - tooltips에서 column들을 넣어주면 뜸
- visualization - format - tooltip에서 툴팁 포맷도 디테일하게 설정해줄수가 있음 (안뜨게 OFF설정도 가능)
- 사용자 지정 열 ( 예를들어 너비,높이 Column을 가지고 넓이 Column을 새로이 만들어주는 작업을 의미함)
- 데이터 transform - 연산해줄 컬럼을 눌르고 - STANDARD - Multiply (비교적 신기능으로 기존열과 새 열을 곱해서 열의 값을 바꾸어주는 기능)
- 더 복잡한 작업을 해주려면 add column - custom column - M언어를 사용(m언어를 알필요는 없다고함, 인터페이스를 가지고 활용하면됨) - 열 선택해서 곱셈이면 * 이걸로 3개 열을 곱해주면 새로운 열이 생김.
- 데이터양 줄이기 (활성화,비활성화 로드)
- 해당 column이 대시보드에 나타나지 않도록 포함에서 제외하는 작업임.이작업을 하면 그 템플릿 다운받을때 (대시보드+데이터) 용량이 확준다
- 전혀 쓰지않는 테이블이나 column의 경우 이작업을 통해 용량을 덜어냄 (데이터가 너무많으면 성능에 문제생길수있으니까)
- Transform data - 테이블 마우스 우클릭 - enable load 클릭해서 선택해제 (해당 테이블을 사용하는 시각화는 에러가 생길것임)
- 비활성화되면 왼쪽에서 기울인 폰트로 보임
- 참조 VS 중복 (보고서의 성능) 64화
- 일단 기존 테이블을 복제 (마우스 우클릭 - Duplicate)
- 보통 참조용 테이블은 기존 테이블을 참조하게 함
- 63,63 추가로 봐야할 필요가 있음
DAY6 : 고급 시각화
- Sort 방식 변경 (값기준, 월화수목.. 이런순서) + 조건부 열 순서 (66,67강의)
- 1. x축이 monday tuesday... 이럴경우 높은값부터 나타날경우 차례대로 월화수목 이렇게 안뜨는 문제가 있음 (높은값부터, 낮은값부터 정렬되기 때문에 월화수목금토일 이케 안뜸)
- 2. 그래프 맨 오른쪽 [...] - Sort axis - 값이 아니라 다른 기준을 고르면 됨
- 3. 하지만 가나다라, abcd방식으로 정렬되기 떄문에 역시 friday, monday, saturday... 이런식으로 뜨는 문제해결 : transform data - add column - conditional column 여기서 COLUMN 이름적고 OUTPUT 1-7 이케 적으면 순서해결
- 4. 다시 돌아가서 column tools - 새로 더해준 기준대로 sort
- 예측 (선형차트)
- Visualization - analysis 로 들어가면 Predict가 뜬다는데 안뜸. 그래서 그냥 PREDICT 그래프를 선택해줬음. 에러가남...
- 사용자 편의 드릴스루 (아이콘)-
< 추가 방법 >
- MATRIX 에서 interactive 하지않게 만들기
- format - edit interactions - 없음 아이콘 선택하면 interactive하지 않게 표시
'<Cloud> > Azure' 카테고리의 다른 글
| M2 맥북에서 AZURE SQL 실습환경 구축 (Data Studio+adventureworks.bak) (2) | 2024.09.18 |
|---|---|
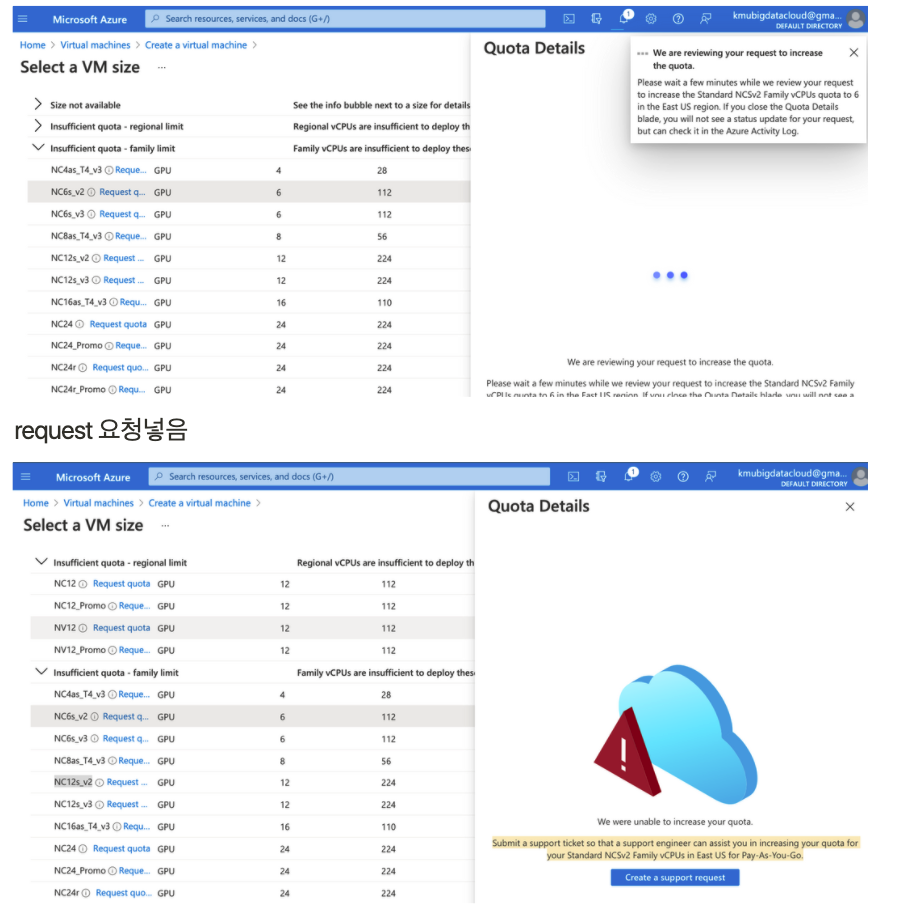
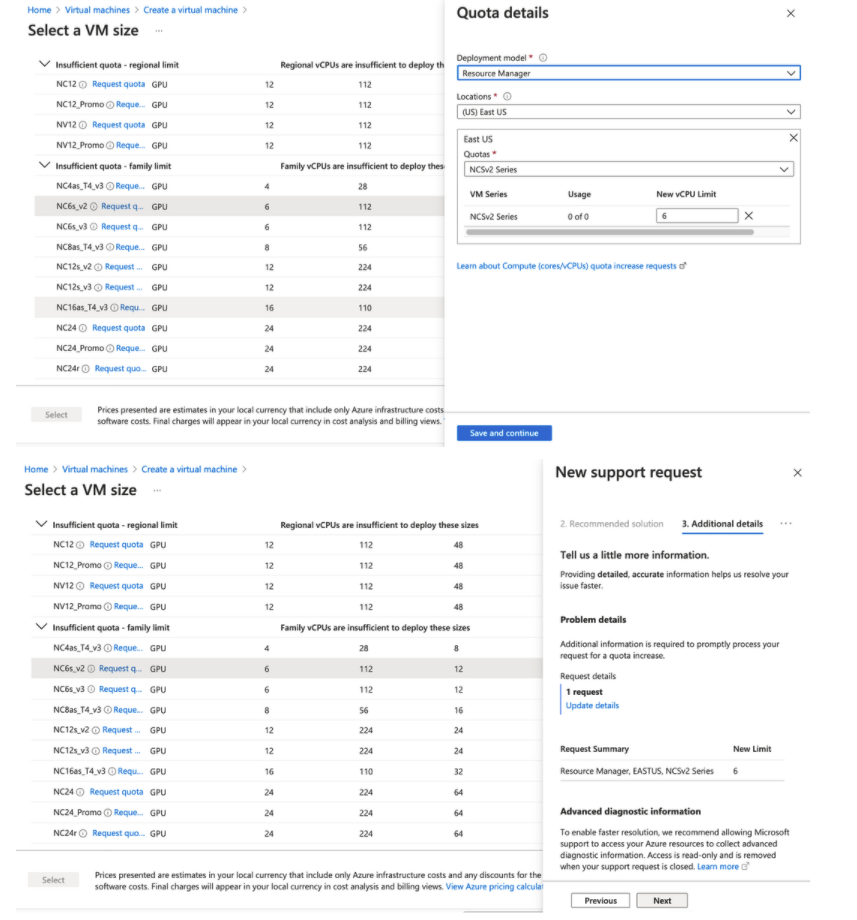
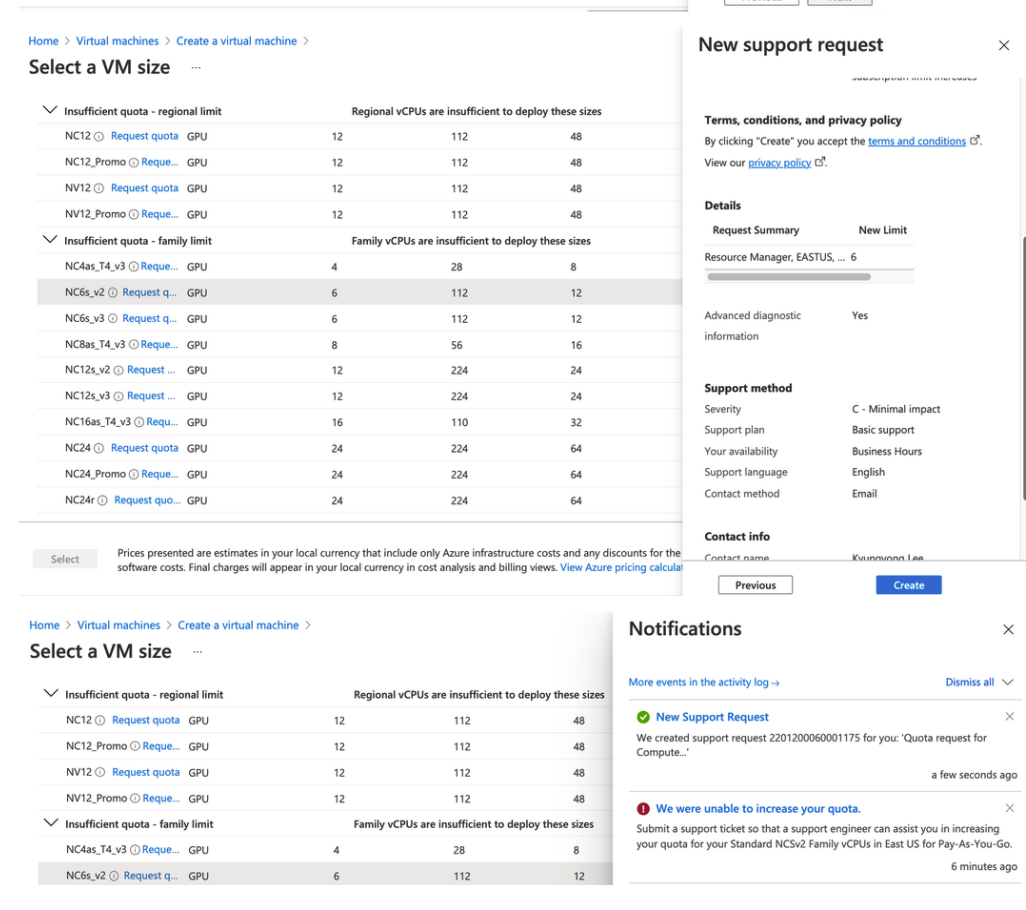
| Azure DSVM에서 사용불가능한 VM 할당량 요청하기(vCPU한도 증가요청) (0) | 2022.01.27 |
| Azure KEY 생성 + 맥북 CLI 연결+이미지검색 (0) | 2022.01.27 |