LLMs for tabular data generation (Tabular 데이터를보완하는새로운방법론을탐구-뉴데이터를생성해서활용)
tabular데이터를보완하는새로운방법론을탐구
Llm을활용해서새로운tabular데이터를생성하고활용할 수 있는방법들을연구
한마디로llm을활용해서데이터를생성해서활용한다!
Borisovetal. (2023b)은 원본 tabular 데이터의 특성을 가진 합성 샘플을 생성하기 위해 GReaT11 (Generation of RealisticTabular data)를 제안. GReaT 데이터 파이프라인은 문장 직렬화 방법을 사용하여 tabular 데이터를 의미 있는 텍스트로 변환하는 텍스트 인코딩 단계와 관련. 이후에는 GPT-2 또는 GPT-2 distill 모델을 미세 조정하는 과정이 이어짐.
REaLTabFormer (Solatorio & Dupriez, 2023)은 GReaT를 확장하여 비관계형 및 관계형 타블러 데이터를 생성
등등....
++ figure4 참조
이러한합성데이터의평가방법 4가지
저차원통계: 열별밀도와 열 간의상관관계를평가하여개별열의분포와 열 간의관계를파악 (열별데이터분포를살펴봄으로써다양성과일관성을평가한다. 예를들면열값이균일하게분포되어있는지확인가능. 또 상관관계를통해서음의상관관계이니지직선적인상관관계인지등등파악가능)
Table and Conversation QA = QA인데테이블만사용하는게아니라다른형식의정보들도같이사용하여대화를 진행
Table Classification =테이블을종류별로분류하는것
Text2SQL = sql생성
Table NLG = 원본테이블에대한설명을생성
Table NLI = 테이블안의관계에대해분석(2019에 많이팔린상품은무엇)
Domain Specific = 영역별로특화. 항공업계는 AIT-QA (Katsis et al., 2022)를 사용하는것을권장, 금융관련테이블질문답변작업에는 TAT-QA (Zhu et al., 2021a)를 사용하는것을추천. 대략적으로업계별로추천하는것이다르다는것으로이해
Pretraining = 테이블+영어문맥설명으로프리트레이닝하면테이블이해해 더 좋은결과를볼수있다라고 함
General ability of LLMs in QA
Numerical QA = 수학추론을필요로하는질문(American Express의평균거래 별 결제량은얼마입니까?)
Text2SQL = Liu et al. (2023c)은 세 가지유형의키워드를식별하는질문매처를설계: 1) 열 이름과관련된용어, 2) 제한과관련된구절(예: "상위 10개"), 3) 알고리즘또는모듈키워드.
Impact of model size on performance=WebTableQuestions에서 6.7B 대 175B GPT-3 모델을비교할 때, 작은모델은 더 큰 모델의점수의절반만달성
Finetuning or No finetuning? LLMs(>70B 파라미터)를 파인튜닝하는것에는매우제한적인연구가진행
QA 관련 논문들
Chain-of-command (CoC)-사용자입력을 중간명령작업의 순서열로 변환
Deng et al. (2022b)는 QA 작업을 세 가지 하위 작업으로 분할
불확실성을 명확히 하기 위해 질문을 할 것인지를 결정하는 Clarification Need Prediction (CNP)
명확히 하기 위해 질문을 생성하는 Clarification Question Generation (CQG)
질문에 대한 명확히가 필요하지 않은 경우 바로 답변을 생성하는 Conversational Question Answering (CQA)
검색능력도 중요함. 검색능력은 아래와같이 두가지 유형으로 나뉨
질문과 관련된 정보를 찾기 ( 예를들어 무슨열의 무슨행의 값을 구해줘(
추가정보와 예제를 얻는것
데이터 메인테이블 관련
Zhao et al. (2023d)는 최상위-n개의 가장 관련성이 높은 문서를 반환하는 검색 모듈 (retriever module)의 성능 향상이 수치적 QA에서 최종 정확도를 일관되게 향상시킨다는 것을 관찰
. Sui et al. (2023c)는 여러 개의 테이블 샘플링 방법 (행과 열)과 토큰 제한 매개변수를 기반으로 한 테이블 패킹을 탐구(질문과 가장 의미적으로 유사한 행을 검색)
Dong et al. (2023)는 SC(Self-consistency, 또다른논문이다)를 사용하여 질문과 관련성에 따라 테이블을 순위 매김하기 위해 ChatGPT를 사용. 그 결과 10개세트의 검색결과를 생성한다음, 가장 자주보이는 세트를 선택. 이때도 SC방법이 사용되었다고함.
cTBLS Sundar & Heck (2023)는 검색된 테이블 정보에 기반한 대화 응답을 검색하고 생성하기 위한 세 단계 아키텍처를 설계함
RoBERTa (Liu et al., 2019)에서 유도된 양방향 인코더 기반의 Dense Table Retrieval (DTR) 모델을 사용해서 연관성이 가장높은 테이블을 식별(인코더만 사용한다)
두 번째 단계에서 트리플릿 손실을 사용하여 행을 순위 매기기 위한 Coarse System State Tracking 시스템을 사용 (??)
마지막으로, GPT-3.5는 그룹화된 지식 원본을 기준으로 한 쿼리와 관련성이 가장 높은 셀을 조건으로 하는 추가 질문에 대한 자연어 응답을 생성
INPUT = 질의 기록, 순위 매김된 지식 원본 및 답변해야 할 질문이 포함된 프롬프트가 입력으로 제공
. Zhao et al. (2023d)은 OpenAI의 Ada Embedding4과 Contriever (Izacard et al., 2022)를 검색기로 사용하고 BM25 (Robertson et al., 1995)를 희소 검색기로 사용. 여기서 말하는 검색기란 가장 관련성이 높은 텍스트랑 테이블을 추출하는데 도움을 주는것. 이 추출된 정보는 질문에 대한 입력 컨텍스트로 제공됩니다.
예제선별관련
Gao et al. (2023)는 1) 무작위로 K개 선택 2) 질문의 유사성을 선택(유사성기준은 유클리드거리같은 사전에 정의된 기준을 사용) 3) 마스킹된 질문 유사성을 선택한다.(=질문과 예제간의 유사성을 평가해서 예제를 선택하는것) 4)대상 SQL 쿼리 s∗와 유사한 k개의 예제를 선택.
Multi-turn tasks
LLM을 반복적으로 호출하는 파이프라인을 설계
3가지 카테고리로 분류된다
(1) 어려운 작업을 처리 가능한 하위 작업으로 분해하기 위해 (너무 복잡한 요청을 작은 여러개 작업으로 나눔)
Suiet al. (2023b)은 하류 테이블 추론을 개선하기 위해 두 단계의 self-augmented prompting approach를 제안. 첫 번째로 프롬프트를 사용하여 LLM에게 테이블에 대한 중간 출력을 생성하도록 요청한 다음, 응답을 두 번째 프롬프트로 통합하여 하류 작업의 최종 답변을 요청한다.
Ye et al.(2023b)은 또한 대량의 테이블을 작은 테이블로 분해하고 복잡한 질문을 텍스트 추론을 위해 단순한 하위 질문들로 변환하도록 LLM에게 안내
Liu 등(2023e)의 경우, 상징적인 CoT 추론 경로를 촉진하기 위해, 모델이 명령을 실행하고 데이터를 처리하며 결과를 검토할 수 있는 Python 셸과 상호작용하도록 허용
(2) 새로운 사용자 입력에 기반하여 모델 출력을 업데이트하기 위해
SParC의 경우, Spider (Yu 등, 2018b)를 기반으로 연이어 따르는 질문을 설계
(3) 특정 제약 조건을 해결하거나 오류를 수정하기 위해
Zhao 등(2023a)은 테이블이 API 입력 제한을 초과하는 경우 다중 턴 프롬프트를 사용하여 이를 해결. 잘못된 부분이 생성되었을 경우 잘못된 경우를 LLM을 되돌려주는 반복적인 과정이 도움이 될수 있다고함.
아웃풋 평가 방식
F1이 일반적이긴함
ROUGE
BLEU
시각화..
한계점과 미래방안
Bias and fairness llm의 내재적인 편향 완화
Hallucination 실제가 아닌값을 생성할 위험 (의료계쪽에서는 치명적)
Numerical representation 숫자는 임베딩이 꼭 필요
Categorical representation 컨텍스트 제한 초과시 데이터 일부가 날라가서 성능에 부정적이어짐. 이를 커버할수있는 인코딩방식이 필요
Standard benchmark 너무 다양하기 때문에 표준화된 벤치마크의 필요성
Model interpretability 데이터 이해능력의 탐구
Easy to use 대부분 데이터 직렬화가 필요해서 모델 엑세스가 쉽지않음. 다른사람들이 사용하기 쉬워야함.(자동전처리나 직렬화를 통합시킨다면 훨씬 쉬울것)
Fine-tuning strategy design llm모델의 적합한 모델과 학습전략
Model grafting 특화된 인코더를 사용해서 비문자 데이터를 매핑..한마디로 텍스트가 아닌 다른 유형의 데이터를 모델이 자체적으로 인코딩할수있다..
LLMs for tabular data generation (Tabular 데이터를보완하는새로운방법론을탐구-뉴데이터를생성해서활용)
tabular데이터를보완하는새로운방법론을탐구
Llm을활용해서새로운tabular데이터를생성하고활용할 수 있는방법들을연구
한마디로llm을활용해서데이터를생성해서활용한다!
Borisovetal. (2023b)은 원본 tabular 데이터의 특성을 가진 합성 샘플을 생성하기 위해 GReaT11 (Generation of RealisticTabular data)를 제안. GReaT 데이터 파이프라인은 문장 직렬화 방법을 사용하여 tabular 데이터를 의미 있는 텍스트로 변환하는 텍스트 인코딩 단계와 관련. 이후에는 GPT-2 또는 GPT-2 distill 모델을 미세 조정하는 과정이 이어짐.
REaLTabFormer (Solatorio & Dupriez, 2023)은 GReaT를 확장하여 비관계형 및 관계형 타블러 데이터를 생성
등등....
++ figure4 참조
이러한합성데이터의평가방법 4가지
저차원통계: 열별밀도와 열 간의상관관계를평가하여개별열의분포와 열 간의관계를파악 (열별데이터분포를살펴봄으로써다양성과일관성을평가한다. 예를들면열값이균일하게분포되어있는지확인가능. 또 상관관계를통해서음의상관관계이니지직선적인상관관계인지등등파악가능)
Table and Conversation QA = QA인데테이블만사용하는게아니라다른형식의정보들도같이사용하여대화를 진행
Table Classification =테이블을종류별로분류하는것
Text2SQL = sql생성
Table NLG = 원본테이블에대한설명을생성
Table NLI = 테이블안의관계에대해분석(2019에 많이팔린상품은무엇)
Domain Specific = 영역별로특화. 항공업계는 AIT-QA (Katsis et al., 2022)를 사용하는것을권장, 금융관련테이블질문답변작업에는 TAT-QA (Zhu et al., 2021a)를 사용하는것을추천. 대략적으로업계별로추천하는것이다르다는것으로이해
Pretraining = 테이블+영어문맥설명으로프리트레이닝하면테이블이해해 더 좋은결과를볼수있다라고 함
General ability of LLMs in QA
Numerical QA = 수학추론을필요로하는질문(American Express의평균거래 별 결제량은얼마입니까?)
Text2SQL = Liu et al. (2023c)은 세 가지유형의키워드를식별하는질문매처를설계: 1) 열 이름과관련된용어, 2) 제한과관련된구절(예: "상위 10개"), 3) 알고리즘또는모듈키워드.
Impact of model size on performance=WebTableQuestions에서 6.7B 대 175B GPT-3 모델을비교할 때, 작은모델은 더 큰 모델의점수의절반만달성
Finetuning or No finetuning? LLMs(>70B 파라미터)를 파인튜닝하는것에는매우제한적인연구가진행
QA 관련 논문들
Chain-of-command (CoC)-사용자입력을 중간명령작업의 순서열로 변환
Deng et al. (2022b)는 QA 작업을 세 가지 하위 작업으로 분할
불확실성을 명확히 하기 위해 질문을 할 것인지를 결정하는 Clarification Need Prediction (CNP)
명확히 하기 위해 질문을 생성하는 Clarification Question Generation (CQG)
질문에 대한 명확히가 필요하지 않은 경우 바로 답변을 생성하는 Conversational Question Answering (CQA)
검색능력도 중요함. 검색능력은 아래와같이 두가지 유형으로 나뉨
질문과 관련된 정보를 찾기 ( 예를들어 무슨열의 무슨행의 값을 구해줘(
추가정보와 예제를 얻는것
데이터 메인테이블 관련
Zhao et al. (2023d)는 최상위-n개의 가장 관련성이 높은 문서를 반환하는 검색 모듈 (retriever module)의 성능 향상이 수치적 QA에서 최종 정확도를 일관되게 향상시킨다는 것을 관찰
. Sui et al. (2023c)는 여러 개의 테이블 샘플링 방법 (행과 열)과 토큰 제한 매개변수를 기반으로 한 테이블 패킹을 탐구(질문과 가장 의미적으로 유사한 행을 검색)
Dong et al. (2023)는 SC(Self-consistency, 또다른논문이다)를 사용하여 질문과 관련성에 따라 테이블을 순위 매김하기 위해 ChatGPT를 사용. 그 결과 10개세트의 검색결과를 생성한다음, 가장 자주보이는 세트를 선택. 이때도 SC방법이 사용되었다고함.
cTBLS Sundar & Heck (2023)는 검색된 테이블 정보에 기반한 대화 응답을 검색하고 생성하기 위한 세 단계 아키텍처를 설계함
RoBERTa (Liu et al., 2019)에서 유도된 양방향 인코더 기반의 Dense Table Retrieval (DTR) 모델을 사용해서 연관성이 가장높은 테이블을 식별(인코더만 사용한다)
두 번째 단계에서 트리플릿 손실을 사용하여 행을 순위 매기기 위한 Coarse System State Tracking 시스템을 사용 (??)
마지막으로, GPT-3.5는 그룹화된 지식 원본을 기준으로 한 쿼리와 관련성이 가장 높은 셀을 조건으로 하는 추가 질문에 대한 자연어 응답을 생성
INPUT = 질의 기록, 순위 매김된 지식 원본 및 답변해야 할 질문이 포함된 프롬프트가 입력으로 제공
. Zhao et al. (2023d)은 OpenAI의 Ada Embedding4과 Contriever (Izacard et al., 2022)를 검색기로 사용하고 BM25 (Robertson et al., 1995)를 희소 검색기로 사용. 여기서 말하는 검색기란 가장 관련성이 높은 텍스트랑 테이블을 추출하는데 도움을 주는것. 이 추출된 정보는 질문에 대한 입력 컨텍스트로 제공됩니다.
예제선별관련
Gao et al. (2023)는 1) 무작위로 K개 선택 2) 질문의 유사성을 선택(유사성기준은 유클리드거리같은 사전에 정의된 기준을 사용) 3) 마스킹된 질문 유사성을 선택한다.(=질문과 예제간의 유사성을 평가해서 예제를 선택하는것) 4)대상 SQL 쿼리 s∗와 유사한 k개의 예제를 선택.
Multi-turn tasks
LLM을 반복적으로 호출하는 파이프라인을 설계
3가지 카테고리로 분류된다
(1) 어려운 작업을 처리 가능한 하위 작업으로 분해하기 위해 (너무 복잡한 요청을 작은 여러개 작업으로 나눔)
Suiet al. (2023b)은 하류 테이블 추론을 개선하기 위해 두 단계의 self-augmented prompting approach를 제안. 첫 번째로 프롬프트를 사용하여 LLM에게 테이블에 대한 중간 출력을 생성하도록 요청한 다음, 응답을 두 번째 프롬프트로 통합하여 하류 작업의 최종 답변을 요청한다.
Ye et al.(2023b)은 또한 대량의 테이블을 작은 테이블로 분해하고 복잡한 질문을 텍스트 추론을 위해 단순한 하위 질문들로 변환하도록 LLM에게 안내
Liu 등(2023e)의 경우, 상징적인 CoT 추론 경로를 촉진하기 위해, 모델이 명령을 실행하고 데이터를 처리하며 결과를 검토할 수 있는 Python 셸과 상호작용하도록 허용
(2) 새로운 사용자 입력에 기반하여 모델 출력을 업데이트하기 위해
SParC의 경우, Spider (Yu 등, 2018b)를 기반으로 연이어 따르는 질문을 설계
(3) 특정 제약 조건을 해결하거나 오류를 수정하기 위해
Zhao 등(2023a)은 테이블이 API 입력 제한을 초과하는 경우 다중 턴 프롬프트를 사용하여 이를 해결. 잘못된 부분이 생성되었을 경우 잘못된 경우를 LLM을 되돌려주는 반복적인 과정이 도움이 될수 있다고함.
아웃풋 평가 방식
F1이 일반적이긴함
ROUGE
BLEU
시각화..
한계점과 미래방안
Bias and fairness llm의 내재적인 편향 완화
Hallucination 실제가 아닌값을 생성할 위험 (의료계쪽에서는 치명적)
Numerical representation 숫자는 임베딩이 꼭 필요
Categorical representation 컨텍스트 제한 초과시 데이터 일부가 날라가서 성능에 부정적이어짐. 이를 커버할수있는 인코딩방식이 필요
Standard benchmark 너무 다양하기 때문에 표준화된 벤치마크의 필요성
Model interpretability 데이터 이해능력의 탐구
Easy to use 대부분 데이터 직렬화가 필요해서 모델 엑세스가 쉽지않음. 다른사람들이 사용하기 쉬워야함.(자동전처리나 직렬화를 통합시킨다면 훨씬 쉬울것)
Fine-tuning strategy design llm모델의 적합한 모델과 학습전략
Model grafting 특화된 인코더를 사용해서 비문자 데이터를 매핑..한마디로 텍스트가 아닌 다른 유형의 데이터를 모델이 자체적으로 인코딩할수있다..
LLMs for tabular data generation (Tabular 데이터를보완하는새로운방법론을탐구-뉴데이터를생성해서활용)
tabular데이터를보완하는새로운방법론을탐구
Llm을활용해서새로운tabular데이터를생성하고활용할 수 있는방법들을연구
한마디로llm을활용해서데이터를생성해서활용한다!
Borisovetal. (2023b)은 원본 tabular 데이터의 특성을 가진 합성 샘플을 생성하기 위해 GReaT11 (Generation of RealisticTabular data)를 제안. GReaT 데이터 파이프라인은 문장 직렬화 방법을 사용하여 tabular 데이터를 의미 있는 텍스트로 변환하는 텍스트 인코딩 단계와 관련. 이후에는 GPT-2 또는 GPT-2 distill 모델을 미세 조정하는 과정이 이어짐.
REaLTabFormer (Solatorio & Dupriez, 2023)은 GReaT를 확장하여 비관계형 및 관계형 타블러 데이터를 생성
등등....
++ figure4 참조
이러한합성데이터의평가방법 4가지
저차원통계: 열별밀도와 열 간의상관관계를평가하여개별열의분포와 열 간의관계를파악 (열별데이터분포를살펴봄으로써다양성과일관성을평가한다. 예를들면열값이균일하게분포되어있는지확인가능. 또 상관관계를통해서음의상관관계이니지직선적인상관관계인지등등파악가능)
Table and Conversation QA = QA인데테이블만사용하는게아니라다른형식의정보들도같이사용하여대화를 진행
Table Classification =테이블을종류별로분류하는것
Text2SQL = sql생성
Table NLG = 원본테이블에대한설명을생성
Table NLI = 테이블안의관계에대해분석(2019에 많이팔린상품은무엇)
Domain Specific = 영역별로특화. 항공업계는 AIT-QA (Katsis et al., 2022)를 사용하는것을권장, 금융관련테이블질문답변작업에는 TAT-QA (Zhu et al., 2021a)를 사용하는것을추천. 대략적으로업계별로추천하는것이다르다는것으로이해
Pretraining = 테이블+영어문맥설명으로프리트레이닝하면테이블이해해 더 좋은결과를볼수있다라고 함
General ability of LLMs in QA
Numerical QA = 수학추론을필요로하는질문(American Express의평균거래 별 결제량은얼마입니까?)
Text2SQL = Liu et al. (2023c)은 세 가지유형의키워드를식별하는질문매처를설계: 1) 열 이름과관련된용어, 2) 제한과관련된구절(예: "상위 10개"), 3) 알고리즘또는모듈키워드.
Impact of model size on performance=WebTableQuestions에서 6.7B 대 175B GPT-3 모델을비교할 때, 작은모델은 더 큰 모델의점수의절반만달성
Finetuning or No finetuning? LLMs(>70B 파라미터)를 파인튜닝하는것에는매우제한적인연구가진행
QA 관련 논문들
Chain-of-command (CoC)-사용자입력을 중간명령작업의 순서열로 변환
Deng et al. (2022b)는 QA 작업을 세 가지 하위 작업으로 분할
불확실성을 명확히 하기 위해 질문을 할 것인지를 결정하는 Clarification Need Prediction (CNP)
명확히 하기 위해 질문을 생성하는 Clarification Question Generation (CQG)
질문에 대한 명확히가 필요하지 않은 경우 바로 답변을 생성하는 Conversational Question Answering (CQA)
검색능력도 중요함. 검색능력은 아래와같이 두가지 유형으로 나뉨
질문과 관련된 정보를 찾기 ( 예를들어 무슨열의 무슨행의 값을 구해줘(
추가정보와 예제를 얻는것
데이터 메인테이블 관련
Zhao et al. (2023d)는 최상위-n개의 가장 관련성이 높은 문서를 반환하는 검색 모듈 (retriever module)의 성능 향상이 수치적 QA에서 최종 정확도를 일관되게 향상시킨다는 것을 관찰
. Sui et al. (2023c)는 여러 개의 테이블 샘플링 방법 (행과 열)과 토큰 제한 매개변수를 기반으로 한 테이블 패킹을 탐구(질문과 가장 의미적으로 유사한 행을 검색)
Dong et al. (2023)는 SC(Self-consistency, 또다른논문이다)를 사용하여 질문과 관련성에 따라 테이블을 순위 매김하기 위해 ChatGPT를 사용. 그 결과 10개세트의 검색결과를 생성한다음, 가장 자주보이는 세트를 선택. 이때도 SC방법이 사용되었다고함.
cTBLS Sundar & Heck (2023)는 검색된 테이블 정보에 기반한 대화 응답을 검색하고 생성하기 위한 세 단계 아키텍처를 설계함
RoBERTa (Liu et al., 2019)에서 유도된 양방향 인코더 기반의 Dense Table Retrieval (DTR) 모델을 사용해서 연관성이 가장높은 테이블을 식별(인코더만 사용한다)
두 번째 단계에서 트리플릿 손실을 사용하여 행을 순위 매기기 위한 Coarse System State Tracking 시스템을 사용 (??)
마지막으로, GPT-3.5는 그룹화된 지식 원본을 기준으로 한 쿼리와 관련성이 가장 높은 셀을 조건으로 하는 추가 질문에 대한 자연어 응답을 생성
INPUT = 질의 기록, 순위 매김된 지식 원본 및 답변해야 할 질문이 포함된 프롬프트가 입력으로 제공
. Zhao et al. (2023d)은 OpenAI의 Ada Embedding4과 Contriever (Izacard et al., 2022)를 검색기로 사용하고 BM25 (Robertson et al., 1995)를 희소 검색기로 사용. 여기서 말하는 검색기란 가장 관련성이 높은 텍스트랑 테이블을 추출하는데 도움을 주는것. 이 추출된 정보는 질문에 대한 입력 컨텍스트로 제공됩니다.
예제선별관련
Gao et al. (2023)는 1) 무작위로 K개 선택 2) 질문의 유사성을 선택(유사성기준은 유클리드거리같은 사전에 정의된 기준을 사용) 3) 마스킹된 질문 유사성을 선택한다.(=질문과 예제간의 유사성을 평가해서 예제를 선택하는것) 4)대상 SQL 쿼리 s∗와 유사한 k개의 예제를 선택.
Multi-turn tasks
LLM을 반복적으로 호출하는 파이프라인을 설계
3가지 카테고리로 분류된다
(1) 어려운 작업을 처리 가능한 하위 작업으로 분해하기 위해 (너무 복잡한 요청을 작은 여러개 작업으로 나눔)
Suiet al. (2023b)은 하류 테이블 추론을 개선하기 위해 두 단계의 self-augmented prompting approach를 제안. 첫 번째로 프롬프트를 사용하여 LLM에게 테이블에 대한 중간 출력을 생성하도록 요청한 다음, 응답을 두 번째 프롬프트로 통합하여 하류 작업의 최종 답변을 요청한다.
Ye et al.(2023b)은 또한 대량의 테이블을 작은 테이블로 분해하고 복잡한 질문을 텍스트 추론을 위해 단순한 하위 질문들로 변환하도록 LLM에게 안내
Liu 등(2023e)의 경우, 상징적인 CoT 추론 경로를 촉진하기 위해, 모델이 명령을 실행하고 데이터를 처리하며 결과를 검토할 수 있는 Python 셸과 상호작용하도록 허용
(2) 새로운 사용자 입력에 기반하여 모델 출력을 업데이트하기 위해
SParC의 경우, Spider (Yu 등, 2018b)를 기반으로 연이어 따르는 질문을 설계
(3) 특정 제약 조건을 해결하거나 오류를 수정하기 위해
Zhao 등(2023a)은 테이블이 API 입력 제한을 초과하는 경우 다중 턴 프롬프트를 사용하여 이를 해결. 잘못된 부분이 생성되었을 경우 잘못된 경우를 LLM을 되돌려주는 반복적인 과정이 도움이 될수 있다고함.
아웃풋 평가 방식
F1이 일반적이긴함
ROUGE
BLEU
시각화..
한계점과 미래방안
Bias and fairness llm의 내재적인 편향 완화
Hallucination 실제가 아닌값을 생성할 위험 (의료계쪽에서는 치명적)
Numerical representation 숫자는 임베딩이 꼭 필요
Categorical representation 컨텍스트 제한 초과시 데이터 일부가 날라가서 성능에 부정적이어짐. 이를 커버할수있는 인코딩방식이 필요
Standard benchmark 너무 다양하기 때문에 표준화된 벤치마크의 필요성
Model interpretability 데이터 이해능력의 탐구
Easy to use 대부분 데이터 직렬화가 필요해서 모델 엑세스가 쉽지않음. 다른사람들이 사용하기 쉬워야함.(자동전처리나 직렬화를 통합시킨다면 훨씬 쉬울것)
Fine-tuning strategy design llm모델의 적합한 모델과 학습전략
Model grafting 특화된 인코더를 사용해서 비문자 데이터를 매핑..한마디로 텍스트가 아닌 다른 유형의 데이터를 모델이 자체적으로 인코딩할수있다
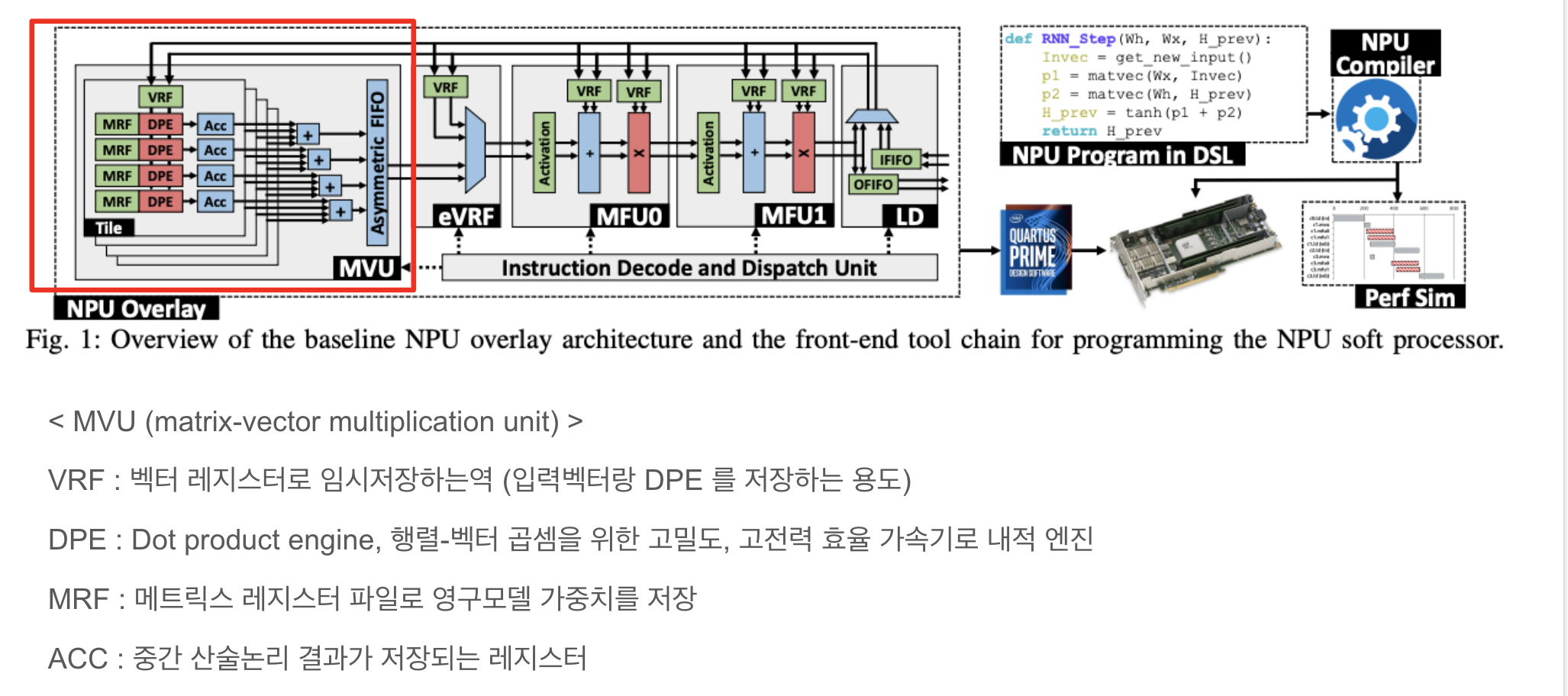
2. Large Language Model for Table Processing: A Survey
텐서 블록에는 3개의 내적 단위가 포함되어 있으며, 각 단위에는 10개의 8×8 승수와 3개의 선택적 누산기(ACC) 가 있음.
** DOT (곱셈) - 벡터끼리의 곱셈을 의미함
** 승수 : 승수란 어떤 수에 다른 수를 나누거나 어떤 식에 다른 식을 곱할 때, 그 나중의 수나 식을 말한다.
** ACC (누산기) : 연산된 결과를 일시적으로 저장해주는 레지스터로 연산의 중심
** 레지스터
레지스터는 비트 패턴을 저장하는 플립플롭 그룹입니다. FPGA의 레지스터에는 클럭, 입력 데이터, 출력 데이터 및 활성화 신호 포트가 있습니다. 클록 주기마다 입력 데이터가 래치되어 내부에 저장되고 출력 데이터가 내부에 저장된 데이터와 일치하도록 업데이트됩니다.
그림 3은 이 모드에서 AI 텐서 블록의 동작을 보여줌
각 주기에 내적 단위를 공급하는 레지스터 뱅크는 점선 상자로 표시됩니다. 3 클럭 사이클 후에 해당 피연산자의 모양과 색상을 사용하여 출력이 생성됩니다.
주황별 :역시 인풋벡터인데 무색 모양은 3개의 내적 단위로 브로드캐스트되는 텐서 블록의 데이터 포트에 대한 입력 벡터입니다.
유색원 : 레지스터 뱅크로 들어온 인풋벡터값
3. baseline 기반으로한 리얼구조
아까 베이스라인 npu 구조 에서 더 발전시킨것이 Stratix 10 NX Npu
** 타일이 왜 두개로 나뉨? (인풋레인이 2개라서)
베이스라인 NPU에서 2개의 타일 및 DPE를 갖는 MVU에 대한 매트릭스-벡터 연산의 매핑을 예제로 들고있다.
DPE는 여러 주기에 걸쳐 입력 벡터의 블록과 행렬 행 블록 간의 내적을 수행
그런 다음 다른 타일에서 해당 DPE의 출력을 줄여 행렬의 다음 행 블록으로 진행하기 전에 최종 결과를 생성
- 대신에 다음그림처럼 여러가지 결과를 저장하기위해 BRAM 기반 누산기(=MVU)를 구현. (BRAM = block ram)
- dual-port RAM. 듀얼 포트 램이므로 한 사이클에 2개의 주소로부터 값을 읽거나 쓰기가 가능
- BRAM 이 여기서 하는일은 기본적으로 스토리지의 역할을 하며 read/write 속도가 매우 빠르다고함/ On-Chip 메모리 ( 메모리가 칩위에 있다는 의미/ 메모리가 칩 위에 있기 때문에 버스(Bus)를 사용하지 않고 바로 메모리에 접근할 수 있다 / BRAM 은 기본적으로 FPGA안에 필요한 정보, data를 저장하는 공간이다 )
*BRAM ? Xilinx FPGA 내부의 SRAM 의 한 종류를 BRAM 이라 부릅니다. (Xilinx FPGA 에는 URAM 도 있습니다.) Intel FPGA 은 BRAM 역할을, Embedded Memory 라고 부르구요.
결과적으로 타일 간 감소를 수행하기 위해 각 타일에서 중앙 가산기 트리로 넓은 버스를 라우팅하면 상당한 라우팅 혼잡이 발생할 수 있습니다
라우팅 혼잡을 완화하기 위해 그림 4c와 같이 각 타일이 이전 타일의 결과를 가져오고 로컬 이진 축소를 수행하고 결과를 다음 타일로 전달하는 데이지 체인 아키텍처를 갖도록 MVU를 재설계합니다. .
이 아키텍처는 각각의 두 개의 연속 타일 사이에 더 짧고 더 지역화된 라우팅을 사용하며 몇 사이클 더 높은 대기 시간을 희생하면서 더 효율적이고 라우팅 친화적인 것으로 밝혀졌다.
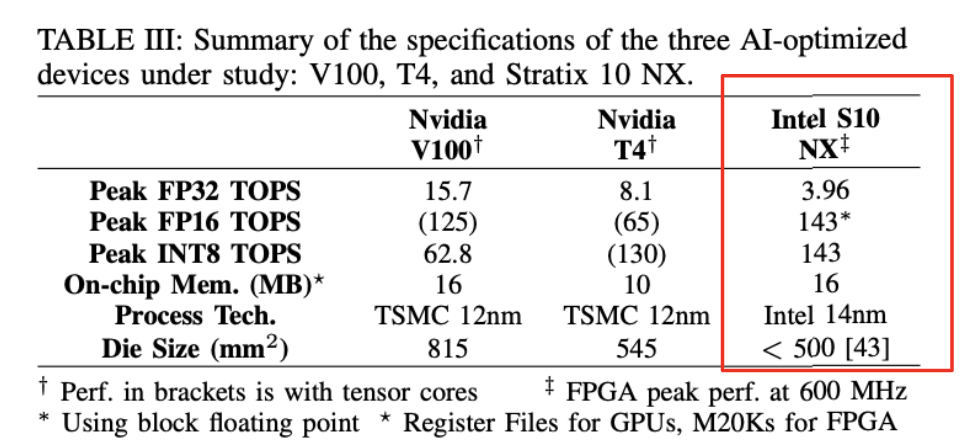
4. 성능비교
** ALM = 해당 제품군의 베이직 빌딩블록
** 빌딩블록 = 컴터를 구성하는 여러가지종류의 기본 회로들을 지칭함
** TOPS = 초당 1조 연산속도 (15TOPS = 1초에 15조번 연산)
**PEAK TOPS 는 MVU 에서만 국한지음
** GEMV = 일반 행렬곱
** GEOMEAN = 기하평균 ( n개 양수값을 모두 곱한다음 n제곱근을 구함)
** 1개의 배치로부터 loss를 계산한 후 Weight와 Bias를 1회 업데이트하는 것을 1 Step이라고 한다.
IBM 왓슨 기계 학습 서비스와 함께 작업 할 수 있습니다. 모델을 훈련, 저장 및 배포하고 API를 사용하여 점수를 매기고 마지막으로 애플리케이션 개발과 통합할 수 있습니다. ibm-watson-machine-learning라이브러리는 데이터 버전 3.5 이상에서 (나중에 IBM 클라우드라고 함) 서비스로 데이터를위한 IBM 클라우드 Pak® (2020 년 9 월 1 일 이후에 생성) V2 인스턴스 계획뿐만 아니라 IBM 클라우드 Pak® 작업 할 수 있습니다. 이전 버전의 IBM Cloud Pak® for Data의 경우 링크에 제공된 라이브러리의 베타 버전을 사용하십시오 .
이 제공된 추정치를가지고 사용자에게 가장 적합한 리소스구성을 제안한다. 즉 사용자가 잡관련 설명만 인풋으로 넣으면, 오프라인 견적 서비스는 아웃풋으로 비용 & 리소스 구성목록을 반환한다.
피처로 플랫폼 하드웨어 특성뿐만 아니라, DL 클러스터와 관련된 피처들도 고려하기위해서 DL 클러스터의 작업로그를 분석했다.
여기서 문제점 : 표1에 나오는 다양한 요소조합을 포함하는 공개 데이터를 찾을수 없었다. → 그래서 이것은 클러스터에서 실행되는 실제 사용자 작업에 대한 런타임 데이터로 보완이 되었다
이것에 그치지않고 클러스터에서 더 많은 작업 추적이 수집될때, 예측모델을 점진적으로 조정하기 위해 오프라인 추정 구성요소는 확장가능한 설계를 가지고 있다. 재교육도 가능하다.
기계 학습 모델에 사용되는 일반적인 성능 메트릭에는 평균 제곱 오류, 평균 절대 오류, 평균 제곱 로그 오류, 중간 절대 오류 및 R-제곱이 포함됩니다. 그러나 런타임 추정을 위한 예측 정확도는 초 단위의 절대 오차로 잘 설명되지 않습니다. 1분이라는 동일한 오류가 10시간 작업에는 작을 수 있지만 2분 작업에는 클 수 있습니다.
현재 모델은 nonlinear regression and machine learning techniques like decision tree, random forest, and gradient boosting.
그림6을 보면 4개의 장기 실행작업의 남은 실행시간을 살펴본다.ㄴ 예측한것과 실제 남은양이 거의같은걸 볼수있다.
온라인 추정은 작업로그에서 읽은 반복시간에 이동평균을 사용하고 남은 런타임을 계산한다.
그림7에서도 100K 반복에 대해 CIFAR10 데이터 세트[12]에서 실행된 Tensorflow ResNet 모델의 예상값과 실제값을 비교해서 보여준다.
잔여 런타임을 구하기위해서 반복 런타임에 지수 가중이동평균을 적용해서 얻는다고한다 ( 10프로안짝의 오류로 싱글!!!!!!!!지피유!!!!!에 대한 우수한 에측을 제공한다고함
B. Offline Runtime Estimation
이미지 분류를 위해 Pytorch 교육 작업을 사용하여 오프라인 런타임 추정을 평가합니다. 다양한 구성으로 옥스포드 꽃 데이터 세트에 대해 여러 이미지 분류기를 훈련하여 작업 추적을 수집했다.그리고나서 한 에포크당 평균시간을 측정
The configurations covered the feature space of network (Alexnet, ResNet18, ResNet50, VGG16); GPU-type (K80, P100, V100); number of learners (1,2,4); batch-size (16, 32, 64, 128, 256); and data-loading threads (0, 1, 2, 4, 8, 16, 32).
여러가지 ML 모델개발 ( 5중교차검증사용, 521개의 데이터 포인트를 416개의 훈련 세트와 105개의 검증 세트로 무작위로 나눔)
y 가 예측한 에포크 레이턴시
I1, ..., I4는 One-Hot의 이진 변수
W는 작업자 수, B는 배치 크기, T는 스레드 수, F는 상대 네트워크 수
GPU 플롭의 경우 K80의 경우 1.87, P100의 경우 5.3, V100의 경우 7.8을 사용 (이는 K40에 대한 GPU 플롭의 비율)
실험적으로 T와 F에 따라 런타임이 감소한다는 것을 관찰했고, 따라서 (2)에서 분모에 T와 F를 추가
그림 8-a 는 선형 모델 2에 대한 테스트 데이터 세트에 대한 상대 오차(예: |y - y~|/y)의 CDF(누적 분포 함수)를 표시
(수정된) 선형 회귀 모델의 성능이 떨어지는 이유 중 하나는 종속 변수가 모델 매개변수의 기능에 대한 복잡한 비선형 종속성을 가질 수 있고 간단한 1차 비선형 항이 이를 포착할 수 없기 때문입니다. 예를 들어, 작업자 수 W는 그림 8b와 같이 Epoch 시간과 비선형 관계를 갖습니다. 이 비선형성을 포착하려면 일반 회귀 모델을 조사해야 합니다.
2) Nonlinear ML Models with One-Hot-Encoding:
여기서는 런타임 추정을 위해 의사결정 트리, 랜덤 포레스트, 그래디언트 부스팅, 심층 신경망(DNN)의 네 가지 ML 모델을 제안!!!!!
피처는 10개 사용 !!!! (OneHot-Encoding을 사용하여 3개의 숫자 변수와 7개의 이진 변수(네트워크 유형용 이진 변수 4개, GPU 유형용 이진 변수 3개)를 포함하여 10개의 독립 변수를 갖습니다)
비선형 ML 모델 하이퍼파라미터 세트는 1. 트리최대깊이 2. 랜덤포레스트 부트스트랩사용여부 3. 그래디언트 부스팅 추정기수,학습률,최대특징수비율 4. DNN 레이어마다 노드개수
표2 보면 바로확 이해갈것
모든 ML 모델은 상대 예측 오류가 상당히 낮습니다(<15%) wow !
3) Nonlinear ML Models with Network Features:
훈련 데이터 세트의 알려진 네트워크에 네트워크 기능이 있는 예측 모델의 성능은 One-HotEncoding을 사용한 것과 거의 동일(표 II 참조).
VII. RELATED WORK
딥러닝 프레임워크별 벤치마크
T. Ben-Nun, M. Besta, S. Huber, A. N. Ziogas, D. Peter, and T. Hoefler, “A modular benchmarking infrastructure for high-performance and reproducible deep learning,” CoRR, vol. abs/1901.10183, 2019. [Online]. Available: http://arxiv.org/abs/1901.10183
지리적으로 분산된 클라우드 지역에 저장된 데이터를 가장 저렴한 비용으로 처리하기위한 클라우드 네이티브 데이터 분석엔진을 제안,4개 지역 공용 클라우드 설정에 대한 의사 결정 지원 쿼리의 경우 비용이 15.1% 감소했다.
INTRODUCTION
보통 지리적으로 가까운 region에서 더 빠르기 때문에 여러 기업에서는 region별로 서비스를 제공한다.
예를들어서 아시아에 저장된 고객리스트, 미국에 저장된 고객 리스트등 흩어진 데이터들을 모아서 분석하기위해 , 다중 regions 에 포함된 데이터들에 대해 분석쿼리를 실행하는것은 비싸고 비효율적
여기서 문제가 발생 : 여러 region에 걸친 데이터들을 모두모아 단일 지역에 복제하기위해 옮겨야하는데 추가적인 전송비용 + 데이터 저장비용이 발생, 또 시간적으로도 매우 많은 시간이 걸림 (ex: 케이프타운 region → 시드니리전으로 1gb 전송하는데 평균5분걸림)
목표 : 비용 최적화
**대역폭과 대기시간을 고려한 네트워크를 통한 작업배치에 대한 연구 관련Suraj Pandey, Adam Barker, Kapil Kumar Gupta, and Rajkumar Buyya. 2010. Minimizing Execution Costs when Using Globally Distributed Cloud Services. In 2010 24th IEEE International Conference on Advanced Information Networking and Applications. 222–229. https://doi.org/10.1109/AINA.2010.30
Tarek Elgamal. 2018. Costless: Optimizing cost of serverless computing through function fusion and placement. In 2018 IEEE/ACM Symposium on Edge Computing (SEC). IEEE, 300–312.
**JCT 최적화 관련Raajay Viswanathan, Ganesh Ananthanarayanan, and Aditya Akella. 2016. CLARINET: WAN-Aware Optimization for Analytics Queries. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16). USENIX Association, Savannah, GA, 435–450. https://www.usenix.org/conference/osdi16/ technical-sessions/presentation/viswanathan
Qifan Pu, Ganesh Ananthanarayanan, Peter Bodik, Srikanth Kandula, Aditya Akella, Paramvir Bahl, and Ion Stoica. 2015. Low Latency Geo-Distributed Data Analytics. SIGCOMM Comput. Commun. Rev. 45, 4 (Aug. 2015), 421–434. https://doi.org/10.1145/2829988.2787505
이러한 문제를 해결하고 목표를 달성하기 위해 살펴보아야할 특징들과 발생가능한 문제점들
region 별로 다른 가격 ( EC2 m5.2xlarge 인스턴스 비용은 버지니아 북부 지역보다 상파울루 지역에서 약 59% 더 비싸다)
region 별로 다른 데이터 전송비용 (아프리카 및 남미와 같은 대륙에서 데이터를 전송하는 경우 AWS의 경우 북미에서 전송하는 비용보다 최대 13배 더 비싸다)
데이터 전송 시간은 region 을 이동할때 10배 이상이며 항상 변동된다.
분석 쿼리를 실행하는 데 몇 시간이 걸리는 것이 일반적이다.
데이터 세트의 크기와 가용성은 언제든지 변경가능
2 SYSTEM ARCHITECTURE
비용최적화라는 목표를 위해, region별로 비용과 성능에 영향을 미치는 모든 요소들을 지속적으로 모니터링하고 주어진 JCT 요구사항에 따라 최대한 비용 효율적인 실행계획을 도출하려고자함 ( = cross-region analytics job 을 가지고 가격 효율적인 plan 을 찾는다 )
Status retriever
각 리전마다 job scheduling 에 대한 필수정보들을 수집하고 제어하는 status retriever가 있다.
이것이하는일은b) 다른 region과 주기적으로 통신하여 네트워크 대역폭내역 수집 (대역폭이 중요한 이유:c) 해당 지역 데이터세트의 metadata 수집
we may want to set a limit on job completion time)
a) api를 통해 각 cloud vendor 로 부터 가격 책정
→ 가장 중요한 parameters 는 region 별 데이터 전송가격과 각 지역별로 컴퓨팅 리소스가격이다.
모든 region의 status retriever 는 p2p 네트워크를 통해 데이터를 동기화해야할 각 지역의 작업 스케쥴러가 결정을 내릴 충분한 정보를 수집해준다.
Job scheduler
Spark SQL 에서 Catalyst optimizer 와 동일한 역할을 함(Spark SQL에서는 Catalyst Optimizer가 최적화를 대신해준다)
소스데이터셋의 메타데이터와 데이터 쿼리를 입력으로 받아서 물리적 실행 계획을 생성
또한 설계에서 계획을 선택할 때 비용과 네트워크 대역폭을 고려.대부분 작업 배치 및 중간 결과가 로컬 I/O 작업 대신 지배적인 요소가 됩니다. (?)
Job manager
Job manager 는 Job scheduler 에 의해 생성된 현재 실행계획과 각 Job에 대한 해당작업상태를 유지, 그리고 다른 region에 execution plan과 다른 job plan을 전파합니다.
각 job manager는 execution plan 에 따라 하나이상의 하위작업을 실행한다
이작업이 완료되면 작업 관리자는 작업 스케쥴러를 호출해서 재평가하고 작업상태와 잠재적인 계획변경을 브로드캐스트한다
변경된 계획으로 인해 작업관리자가 하위작업실행을 중단할수 있다.
Task executor
computes resources로 이루어져있다.
It is built on top of existing cloud offerings to remove the resource constraints of some previous works [12]. Because there is no stable access pattern, and each job requires a different amount of resources, leveraging serverless functions (e.g., AWS Lambda[2]) as the main executor improves resource utilization [14]. Using spot VM instances to run the queries may save cost when incoming workloads can be well predicted.
Transient datastore
하위 작업의 결과는 임시 데이터 저장소에 저장됩니다. 임시 데이터는 나중 단계에서 사용될 수 있으므로 다음 하위 작업으로 전달된 직후에 삭제되지 않습니다. 작업 관리자는 데이터 저장소를 정기적으로 스캔하여 일정 시간이 지나면 실행 계획에서 참조하지 않는 임시 데이터를 식별하고 불필요한 저장 비용을 피하기 위해 제거합니다.
3 PRELIMINARY RESULTS
제안된 시스템의 효율성을 검증하기 위해 AWS에서 실험을 진행
10GB의 TPC-DS[16] 데이터 세트를 생성. 데이터 세트 중 한 region의 Amazon S3 [1] 버킷에 4개의 비교적 작은 테이블을 놓고 4개 region 모두에 큰 테이블을 고르게 배포했습니다.
We simulated Query 7 of TPC-DS test suite in Python programs on EC2 c5d.2xlarge spot instances.
4가지 전략
Aggregation ) 모든 데이터를 비용적은 region으로 몰아넣고 모든 계산수행
In-place ) 데이터이동 X , 각 region 에서 가능한 많은 계산을 수행한다음, 해당 영역 중 하나에서 중간결과를 집계 (지역별로 컴퓨팅 가격이 다르다는걸 고려하지 않음)
Optimized In-place ) 각 region 마다 계산수행하기전에 작은 테이블을 모든 region 에 배포(최적화)(the WAN-usage optimal solution)
Hybrid a+c ) 컴퓨팅및 데이터 전송가격으로 결정 (이게 가장좋은 결과를 도출) - 15프로나 좋아짐 가격만 따지면 가장좋은 방법이됨.
** WAN
WAN 최적화가 중요한 이유?다양한 비즈니스 프로세스가 느린 네트워크의 영향을 받습니다. 직원이 파일에 액세스하는 것과 같은 간단한 작업도 허용할 수 없을 정도로 느려질 수 있습니다. 네트워크가 끌리는 경우 비즈니스 전체 파일 관리자를 로드하는 데 시간이 걸리고 파일을 여는 데 더 오래 걸릴 수 있습니다. 2분의 작은 작업처럼 보이지만 이러한 문제는 빠르게 누적됩니다.
한편 관리자는 비효율적이고 대기 시간이 긴 네트워크 인프라와 싸우는 경우 네트워크를 효과적으로 관리 및 모니터링하고 네트워크 보안을 보장하는 데 어려움을 겪을 수 있습니다. WAN 최적화는 잠재적으로 관리자( 및 해당 소프트웨어 도구) 가 모든 장치와 최종 사용자를 보다 효과적으로 보호 할 수 있도록 합니다 .
기업은 클라우드 컴퓨팅, 애플리케이션 및 웹 포털과 같은 기타 네트워크 전체 기술의 사용 증가로 인해 WAN 설정에 대한 압박을 점점 더 많이 받고 있습니다. 이러한 복잡성과 볼륨을 사전에 관리하지 않으면 네트워크 속도 저하가 주요 문제가 될 수 있으므로 WAN 전반에 걸친 관련 트래픽 증가 는 WAN 최적화를 더욱 중요하게 만듭니다.
WAN 최적화에는 더 많은 대역폭을 수신하기 위해 네트워크의 특정 부분에 우선 순위를 지정하는 작업이 포함됩니다. 예를 들어 중요한 데이터 처리 작업과 관련된 네트워크 부분에 더 많은 처리량과 대역폭을 할당하여 작업이 빨리 완료되도록 할 수 있습니다. 네트워크에 대한 물리적 또는 논리적 변경을 통해 많은 WAN 개선을 달성할 수 있습니다.
먼저 간단히 논문의 개요를 살펴보자면, 요즘 머신러닝은 이기종 리소스를 보유한 전담 작업자가 아니라, 클러스터에서 더많이 훈련이 됩니다. 이떄, 다른워커보다 훨씬 느리게 실행되는 스트래글러는 부정적인 영향을 미칩니다. (오른쪽 그림, 빨간색 화살표) 여기서 스트래글러가 의미하는것은 적은수의 스레드가 주어진 반족을 실행하는데 다른 스레드보다 오래걸릴떄 발생하는 문제를 의미합니다. 모든 스레드는 동기화되어야해서 모든 스레드는 가장 느린 스레드(스트래글러)의 속도로 진행할수밖에 없기 때문입니다. 이 논문의 핵심은 이 샘플 배치의 크기를 적절하게 조정해서 작업자의 부하를 즉각적인 처리기능에 맞게 조정하는것입니다.
이 논문에서는 ML 워크로드의 스트래글러를 제거하기 위해 SEMI Dynamic Load balancing이라는 새로운 방법을 제안합니다. 그리고 이방법을 이용해서 LP_BSP를 구현합니다. 여기서 BSP란 병렬 소프트웨어와 하드웨어 개발의 기준이 되는 모델로 PRAM 모델의 일종입니다.
**Pram ⇒ 공유 메모리르를 사용해서 프로세스간에 병렬 통신을 지원하는 구조입니다.
이 체계에서 빠른 작업자는 각 iteraiton이 끝날때마다 느린 작업자(스트래글러)를 기다려야함으로 스트래글러는 모델의 학습 효율성을 저하시킵니다. 이 기존의 BSP모델의 단점을 보완한것이 LP-BSP 모델입니다.
들어가기 앞서서 이 논문에서 자주 쓰이는 개념들에 대해 간단히 짚고 넘어갑니다. 클러스터는 다음과 같이 두가지 종류로 나뉘는데, 전자의 경우, 전용 클러스터라고 불리며 후자의 경우 비전용 클러스터라고 합니다.
전자는 높은 효율성을 보이지만, 유지관리 비용이 많이 들고 널리 엑세스가 불가함으로 쉐어링이 되지 않는 문제를 가지고있습니다.
후자의 경우, 비전용 클러스터로 앞서 설명한 이기종 하드웨어로 구성되어있으며, cpu 와 gpu의 빠른 발전속도에 맞게 aws같은곳에서 이기종 하드웨어 세트로 모델을 학습시킬수 있습니다. 이 경우 dynamic하게 리소스들이 할당되며, 싸고 용량문제가 비교적 적게 발생합니다.
최근 비전용 클러스터(위에서 설명드린) 에서 주로 모델 훈련이 이루어지는 한편, 더 심각한 스트레글러 문제가 발생합니다. 스트래글러의 경우에도 크게 두가지로 나뉠수가 있는데 비결정론적 스트래글러, 결정론적 스트레글러로 나뉠수가 있습니다.
전자의 경우, os 지터같은 일시적인 장애로 인해 발생하며, 일시적이로 아주 미미합니다
** os jiter: e.g. 백그라운드 데몬 프로레서의 에약 / 비동기 이벤트 처리로 인해 발생하는 간섭
하지만 후자의 경우, 전자에 비해 훨씬 심각하고 오래 지속됩니다. 그리고 이는 앞서 설명드린 비전용 클러스터에서만 발생합니다.
간단히 말하면, 스트래글러는 적은 수의 스레드에서 주어진 반복을 실행해야하는데 다른 스레드보다 오래걸릴때 발생하는 문제입니다 모든 스레드가 동기화되어야해서 각 스레드는 iteraiton마다 가장 느린 스레드의 속도로 진행되어 문제가 발생하는것입니다.
이제 이런 스트래글러를 해결하기위해 과거에 행해졌던 여러가지 시도들에 대해 살펴봅니다.
ASP 방식은 다른 worker를 기다리지 않고 독립적으로 다음 반복을 수행합니다. 이렇게 하면 컴퓨팅 주기를 낭비하지않고 하드웨어적으로 효율이 높습니다. 그런데 가장큰 문제가 global하게 매개변수가 동기화가 제대로 되지않아 부실한 매개변수를 사용하게 될 확률이 높아집니다. 이는 앉은 품질의 업데이트를 만들어내기 때문에 더 많은 Iteraitondl 필요하게되고 결국엔 그렇게 효과적인 스트래글러 해결방법은 아닌듯합니다.
SSP 방식은 앞서 ASP 와 BSP를 섞어놓은 방법입니다. 매개변수 비활성이 특정한 임계값에 도달할때만 스트래글러를 기다려줍니다. 하지만, SSP는 주로 비결정적 스트레글러에만 초점을 맞춘 방법이기 때문에, 결정적 클러스터에 적용할경우 지연이 자주 발생할수 있습니다. ASP 와 BSP가 섞인 방법이기 떄문에 여전히 스트래글러가 발생시 기다려야하는 문제가 남아있고 해결되지 않았습니다.
Redundant execution이라는 방법은, 스트래글러 worker에 여러 복사본을 두어서 먼저 완료된 작업의 결과만 받아들이는 방법입니다. 그런데 이 방법은 차선책일뿐, 일부의 스트래글러만 완화해주지만 최악의 스트래글러의 경우 전혀 도움이 되지 않습니다. 복제본이 모두 느리다면 큰 효과가 없기 때문입니다. 또 복제본을 만들기 때문에 추가적인 리소스를 소비해야 한다는것이 단점입니다.
지금까지의 방법들은 전부 스트래글러가 발생할경우 이를 완화하는 방법들만을 다루었지 스트레글러의 근본원인에 대해 서는 다루지 않았습니다. 애초에 스트레글러가 발생하는것을 방지하면 더 근본적으로 문제를 해결할수 있습니다. 이를 위해서는 로드밸런싱 기술에 의존할 필요가 있습니다. 이 로드밸런싱(부하분산) 은 병렬처리에서의 고전적인 연구주제이며 두가지 (static , dynamic) 방식으로 나뉩니다.
전자는 정적 부하분산방법이고 후자는 동적 부하분산 방법입니다.
정적 부하분산은 라운드 로빈같이 정적인 양을 다루며, 동적 부하분산은 부하가 많은 작업자의 일을 런타임부하가 적은 작업자로 재분배해줍니다
아래 그림은 FLEXRR 이라고 최근의 Dynamic한 load balancing 방법입니다. 주어진 임계값에 대해서 다른 작업자보다 뒤처지면(slow) Fast한 작업자에게 일을 제공합니다
이 논문에서는 이 dynamic load balancing 개념을 사용해서 Sem-dynamic loac balancing이라는 전략을 제공합니다
앞서 말한방법들을 바탕으로 새로운 전략을 내놓았습니다. 각 iteraiton 안에서는 정적으로 부하를 유지하지만, 다른 iteraiton에서는 동적으로 유지합니다. 이게 무슨말이냐 하면, 각 iteraiton의 경계부분에서 각 worker들의 상태를 측정합니다. 요즘에는 iteration의 크기가 아주 작고 iteraiton안에서도 엄청나게 큰 변화가 일어나는것이 아니기 때문에 (위 그래프에서 보면 배치 사이즈별로 iteraion time이 몇초 혹은 0.몇초 대로 굉장히 작음을 알수있습니다) iteraiton 의 경계부분에서 측정해도 충분합니다.
한마디로 iteraiton 전부를 볼필요없이 경계부분만 살펴본다는것입ㄴ디ㅏ
두번쨰로, 각 경계에서 스태글러를 감지해냅니다.
세번쨰로, 각 iteraiton 별 경계에서 스트래글러를 감지해내고 배치크기를 조정해줍니다.
이러한 로드밸런싱 전략을 사용할것이라고 합니다.
이제 앞에서 load balancing 전략을 정해주었으니, 비전용 클러스터에서 효율적인 분산학습을 위해 LB-BSP라는 새로운 방법을 제시합니다. 먼저 모델학습 반복과정에서 iteration이 걸리는 총 시간은 t 이고, 이 t는 tm + tp로 이루어집니다 (위 피피티에 설명)
x 는 배치를 의미합니다. 그런데 정해놓고 보니, cpu와 gpu 클러스터에 각각 다른 문제가 발생합니다. cpu 클러스터에서는 ti와 xi가 선형적으로 증가하는데 ( 배치 사이즈가 커지면 프로세싱 시간인 t도 늘어난다) , Gpu는 비선형적입니다. 그래서 cpu와 gpu를 각각 따로따로 살펴보기로 합니다.
cpu는 gpu같은 가속기가 없기 때문에 다음과같은 상황에서 주로 쓰입니다 ( 피피티 위에 설명)
그리고 앞 피피티에서 말한것처럼 x,v 간에 선형관계를 이루고 있습니다. 그리고 t에서 tp가 99퍼를 차지하고 있기 떄문에 tm은 무시해도 별 영향이 없습니다.
Γ (x) 값이 선형적이기 떄문에 tp와 배치사이즈(x) 는 비례하게됩니다. 그래서 다음 반복에 대해 작업자 배치 크기를 결정하기 위해서는 현재 반복에서 샘플처리속도만 알면됩니다.
그런데 문제가, 샘플처리속도가 항상 일정한것이 아니라 동적으로 달라지기 때문에, NARX라는 방법을 사용합니다
NARX는 RNN의 일종으로 과거속도와 현재속도, cpu및 메모리 사용량같은 과거와 현재값을 모두 받아들이는 방법이라, 보다 좋은 성능을 보인다고 합니다.
위 알고리즘을 간단히 살펴보면, 이전 피피티에서 언급했던 샘플 처리 속도 (v)의 과거 값 / CPU 및 메모리 사용량 (c / m)의 두 구동 리소스의 현재 과거 값들을 받아옴을 확인할수 있습니다.
tp와 해당 함수의 식을 조합해서 v(속도)를 구하고 이 속도를 F (NARX 함수) 에 넣어서 계산해줍니다. 앞 피피티의 연산식을 활용하여 새로운 배치사이즈를 리턴해줍니다.
앞서 cpu 클러스터에 대해 살펴보았고 이번에는 gpu 클러스터에 대한 성능을 특성화 한다음 알고리즘을 제시해주었습니다. 우선 gpu의 성능으로는 앞서 cpu에서는 tm을 무시해주었지만 gpu에서는 무시해주면 안됩니다. gpu에서 계산은 cpu에서보다 훨씬 빠르고 이에따라 통신시간도 무시할수 없어졌습니다.
또 gpu를 수행하기 위한 일련의 준비작업(메모리간에 매개변수 교환, 처리커널 시작..)에도 상당한 오버헤드가 발생하기 떄문에 이 것들도 무시할수 없어졌습니다.
세번쨰로, tesla100 같은 최신의 고급 gpu의 경우 샘플배치가 너무 작아서 일정 크기이상으로 샘플 배치크기를 줄인다면 성능이 확 떨어지게 됩니다.
네번쨰, 각 반복동안 중간겨로가와 매개변수등을 모두 gpu 메모리에 저장해야함으로, 최대 배치크기를 제한해야합니다. (메모리부족을 예방하기위해)
앞 피피티에서 살펴본것들을 바탕으로 다음 알고리즘을 살펴보면
우선 각 iteration에서 가장 느린 작업자를 스트래글러로 지정해주고 가장 빠른 작업자를 리더로 지정해줍니다.
먼저 위 피피티에서 세번쨰문제를 해결하기위해 특정 배치크기 이하로 떨어지는것을 예방해줍니다.
두번쨰로 여전히 스트래글러의 크기가 리더보다 크다면, 리더의 배치크기를 조금 줄여주고, 스트래글러의 배치크기를 조금 늘려주는 방향으로 균형을 잡아갑니다
세번쨰로 반대가 된다면 파인튜닝을 통해 스위치 해줍니다.
*파인튜닝 : 기존에 학습되어져 있는 모델을 기반으로 아키텍쳐를 새로운 목적으로 변형하고 이미 학습된 모델 weights 로 부터 학습을 업데이트하는 방법을 의미합니다.
마지막으로 cpu,gpu별로 결과값을 살펴보면, 그래프 3개짜리에서 보면 (A) 그래디언트 업데이트당 시간의 평균 / worker의 수를 의미합니다. (B)는 통계적 효율성으로 목표하는 정확도에 도달하는데 필요한 업데이트수를 의미합니다. (한마디로 목표한 정확도에 이르기까지 반복하는 iteraion수를 의미합니다.) (c)는 목표정확도에 도달하는데 필요한 전체시간을 보여줍니다.(=목표한 정확도에 도달하는데 필요한 전체 시간)
세개 그래프 값에서 모두 LB-BSP 이 가장 적은 업데이트수와 시간을 가짐을 확인할수 있습니다.
아래그래프 2개를 보면, 마이크로 벤치마크를 실시한것으로 인스턴스 4개만 실시한것을 비교한것입니다. ( 인스턴스 4개를 합쳐준것을 cluster A라고 부릅니다) iteraion 횟수가 점점 늘어날수록 일정한값에 도달함을 알수 있습니다. 또 iteraion 횟수가 점점 늘어날수록 4개 인스턴스 값의 배치 처리시간이 거의 같아져서 straggler 문제가 해결됨을 확인할수 있습니다
cpu에서도 살펴봅니다. 여기선 table B 와 같이 인스턴스들을 합친 cluster-B를 만들어 살펴봅니다.
figure 9 는 cluaster B 에서 서로 다른방식으로 SVM 과 ResNet-32를 훈련할떄의 평균반복시간을 보여줍니다. LB-BSP가 가장 짧은 시간으로 최고의 효율성을 이끌어낼수있음을 확인할수 있습니다.
FIgure 10은 NARX 모델을 사용했을떄의 예측성능을 추가로 평가해준것입니다. 클러스터 B에서 m4.2xlarge 인스턴스 하나에 대한 resnet-32 훈련 프로세스에서 무작위로 iteration을 골라 살펴본것입니다. 이를 통해 NARX가 기존의 방법 뿐만아니라 프로세싱 속도 예측도 잘한다는 추가적인 기능도 확인할수 있습니다.
+)
NARX 그래프에 대한 내용에서 accuracy 라고 잘못 설명했던 부분을 정정합니다.
→ 그래프의 내용은 m4.2xlarge 스턴스 하나에 대한 ResNet-32 훈련 프로세스에서 iteration을 무작위로 선택한 구간으로, LP-BSP의 성능을 나타내기위한 지표라기보다 , NARX의 성능을 더 보여주기위해 추가적으로 진행해준 실험에 대한 표였습니다. (cluster-B 를 사용해서 prediction을 실시해준 결과를 나타낸준것 )
19p Figure 4 그래퍼에서 xo 가 의미하는것은 최대 배치사이즈 제한값입니다. 메모리 부족문제를 방지하기위해서 배치사이즈크기의 최대값을 지정해준것을 의미합니다
<간단 정리>: kubernetes는 클러스터에서 여러 컨테이너를 관리하고 생성하도록 설계된 컨테이너operation플랫폼입니다.그안에서pod가 기본구성요소이며, yaml로 쓰여진description파일을 기반으로pod의 생성과 관리를 요청할수있습니다.이 파일안에 컴퓨팅자원들의 양을 지정해주어 자원관리를 수행합니다. Pod의 컴퓨팅자원 관리정보를 기반으로pod가 배치될node를 결정하는데 이러한 스케쥴링 방식에 따라 효율적인 컴퓨팅 자원활용이 결정됩니다.
스케쥴링 과정은 먼저 사용자가kubetctl create를 명령하고나서pod생성이 실행됩니다. kubecxtl에서API server로부터 구조적정보+메타데이터 스키마를 전달받아pod descripton file을 파싱하여pod정보를 담은podSpec을 생성하고pod생성요청을 보냅니다. Kube-scheduler엣는 빈노드가 있는지 확인하는 역할을 합니다.필터링과 스코어링을 통해 노트를 선택하는 과정을 거칩니다. Kubelet은podspec의 변화가 발생했을 겨웅podSpec을 전달받아서pod에 대한 컴퓨팅자원을 예약합니다.그리고node에서 컨테이너를 실행합니다