우선 Bitmap은 카오스게임방식으로 패턴을 나타낸다. 이것은 단순한 숫자를 문자로 변환하여 패턴을 한눈에 살펴볼수 있도록 하는 알고리즘입니다. 하지만 이 알고리즘을 적용하기위해서는 이산 시퀀스형태로 만들어야하는데 우리가 사용하고자 하는 데이터는 시계열 실수 데이터. 이런 시계열 데이터를 이산 시퀀스로 변환해주는것이 바로 SAX알고리즘입니다 SAX 알고리즘은 타임시리즈 실수 데이터를 동일한 크기의 구간으로 나눕니다. 나눈 구간의 평균값을 계산한다음 그 구간을 전부다 그 평균값으로 대체해버리는 방식으로 타임시리즈 데이터를 이산시퀀스로 변환해줍니다. 그리하여 연속된 실수값 타임시리즈값을 → 일정 구간으로 나누어 평균값으로 바꾸어버려 이산시퀀스로 만들고 → 구간별로 baabccbc같은 문자로 패턴을 얻을수 있다. → 얻어낸 문자패턴을 카오스게임에 적용하여 시각화할수 있습니다.
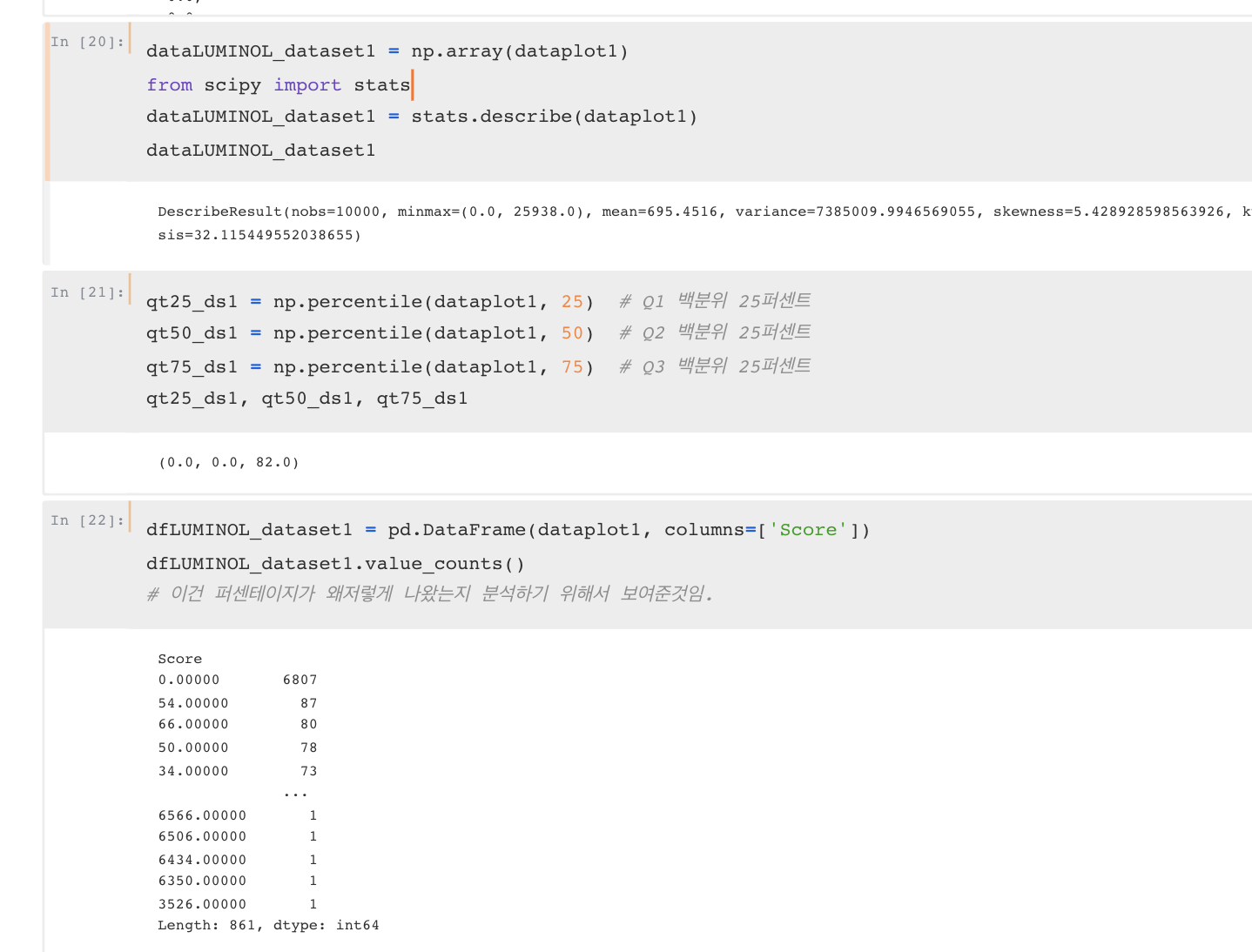
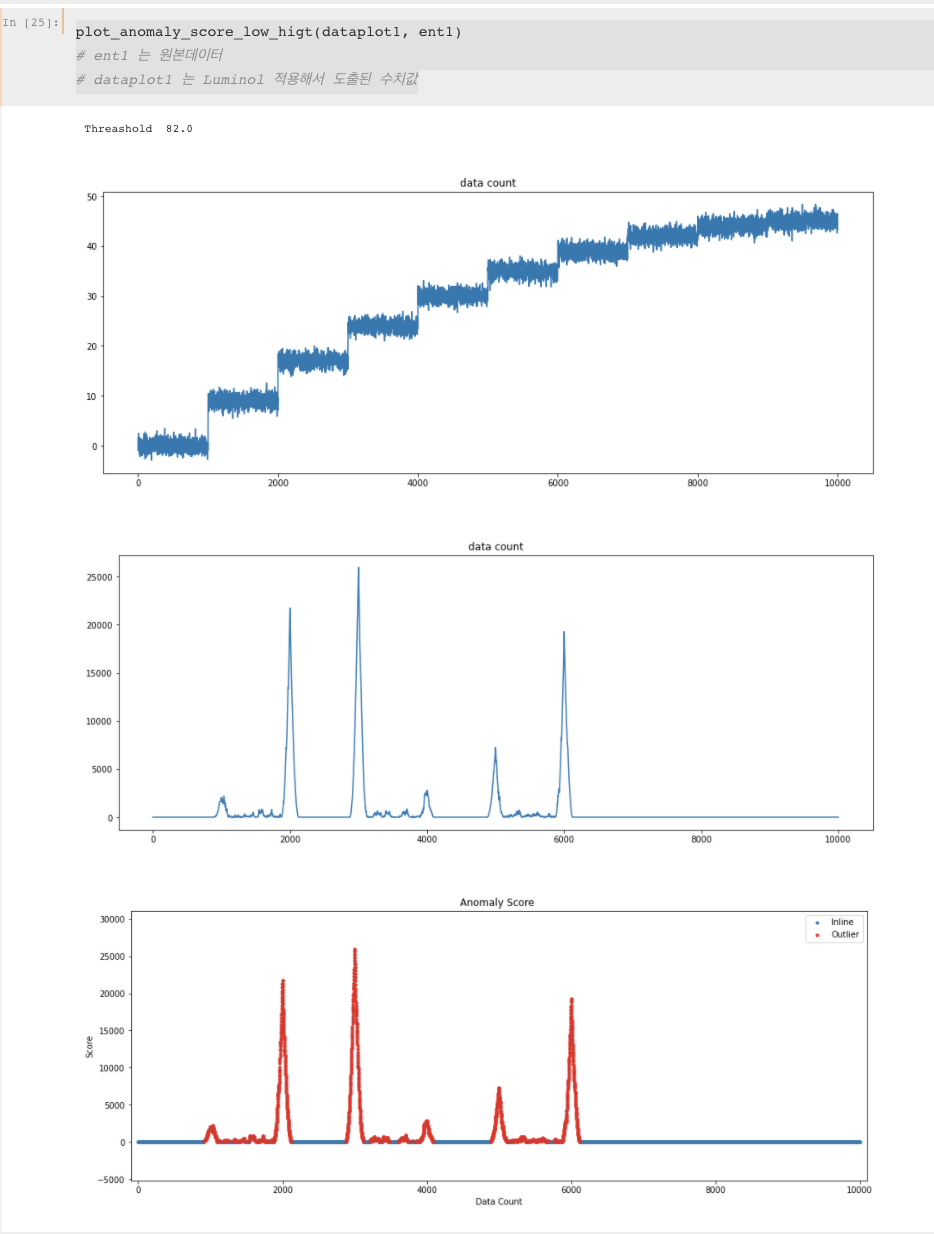
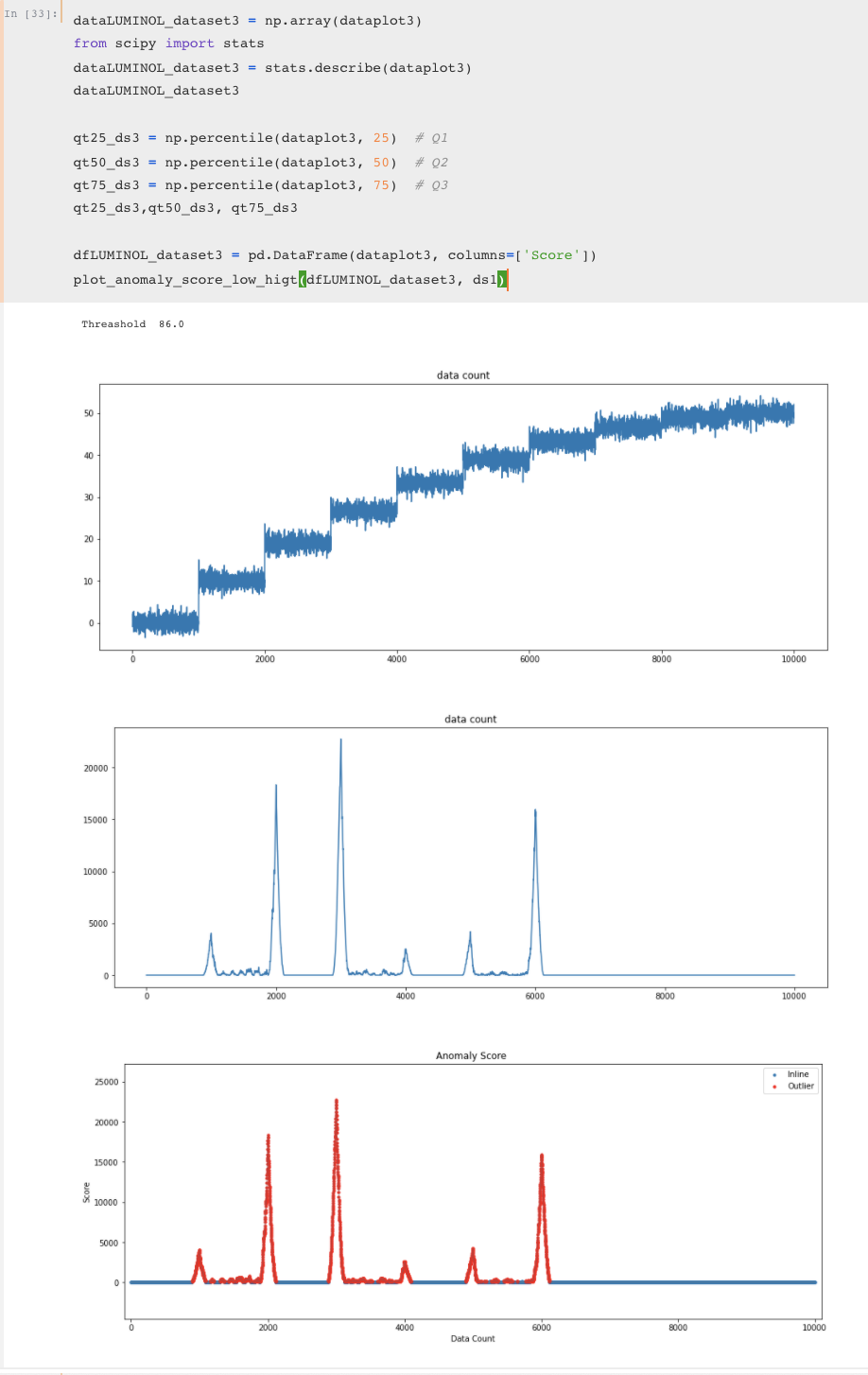
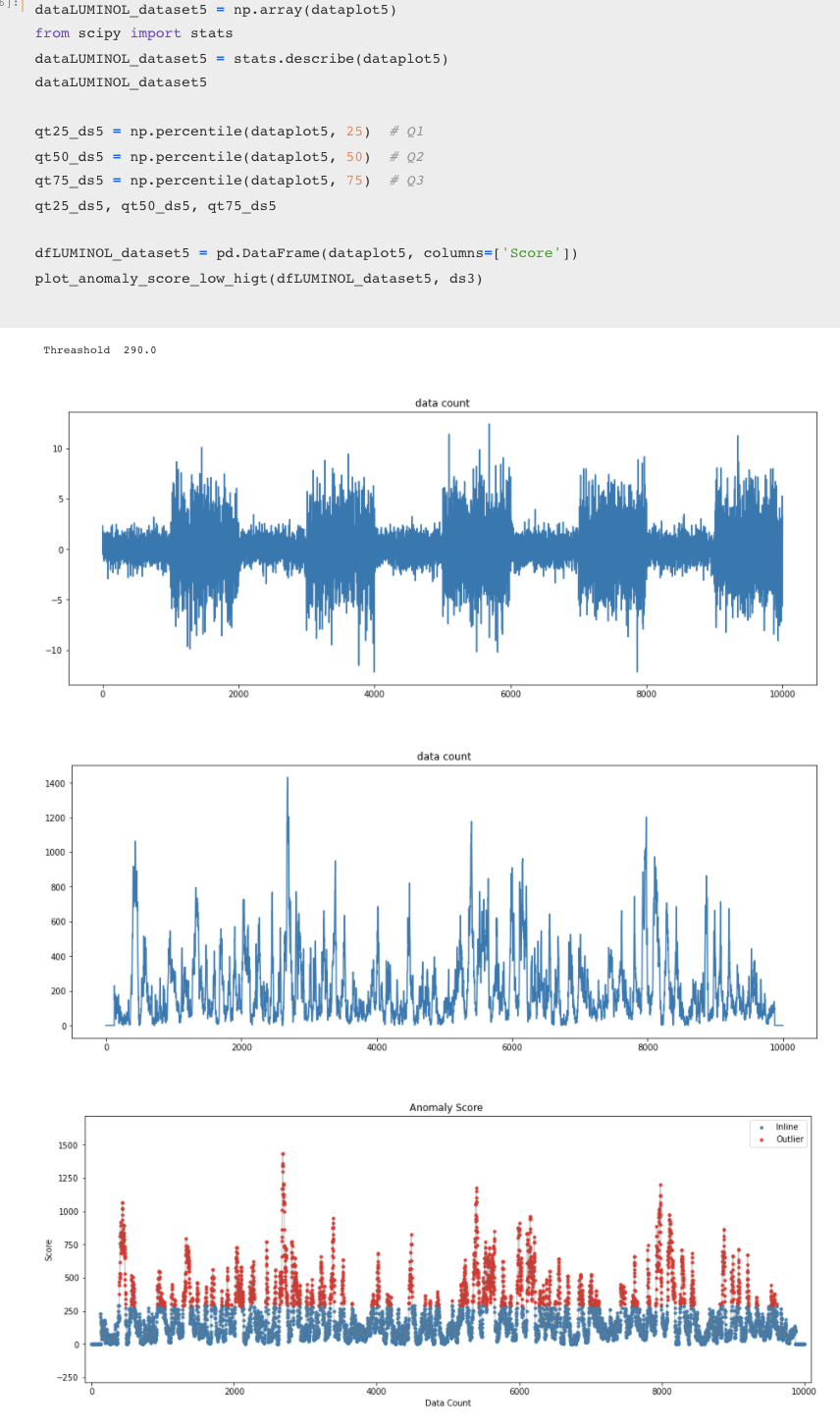
anomaly detection을 하는방법은 다음과 같습니다. 1) 타임시리즈는 lead 윈도우와 lag 윈도우로 나뉜다. 두개의 크기는 다를수 있으며 lead window는 예측하고자하는 window, lag window는 선행 윈도우로 대체적으로 lead window이전의값을 의미합니다. 이 각각의 window에 속한 타임시리즈는 앞에서처럼 sax알고리즘을 사용하여 문자열로 바꾸고 → 문자열로 바꾼값을 quad tree안에 집어넣어서 정리하여 두개의 bitmap를 생성합니다.→ 두개 비트맵사이의 거리는 아래식으로 구합니다. (이 구한 숫자가 바로 이상탐지값이고, 이 숫자 높을수록 이상치값이 높다고 판단합니다.) 이 과정을 쭉 반복하면서 이상치값을 구하고 새롭게 구한 이상치값으로 재구성한 그래프를 내놓은게 바로 luminol 입니다.
코드를 살펴본결과 Luminol울 수행할때 lead window, lag window 의 디폴트 크기는 전체 데이터 길이의 0.2/16 즉 약 1.25% 를 차지하도록 설정해줍니다. 그리고 너무 작은 데이터사이즈나 너무 큰 데이터 사이즈의 경우를 대비해서 min,max사이즈도 정해두었습니다. 아래코드처럼 chunk_size(=윈도우크기)를 사용자가 직접 설정하지 않으면 디폴트값으로 진행되는것으로 확인하였습니다.
그리고 lag window와 future_window(=lead window)값을 비교하는 함수를 살펴보니 위논문에서 구한 식과 동일한것을 확인하였습니다.
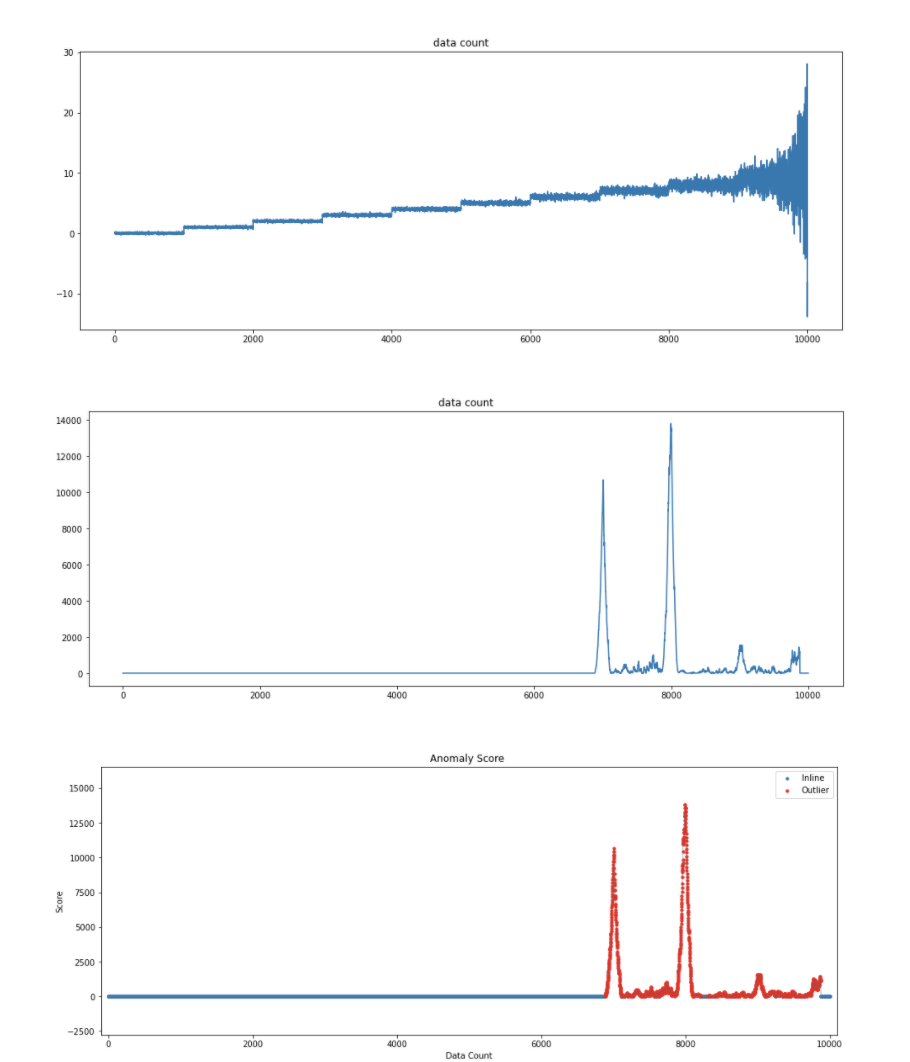
moving average가 가장 평균적으로 많이 쓰이는 smoothing 방식입니다. 이는 주어진 데이터 전/후의 일정 개수의 데이터의 평균이나 중간값을 그 데이터의 값으로 추정하는 방법입니다. 그에 반해 savgol filter은 특정구간의 평균/중간값이 아니라, 특정구간을 ax^2 + bx + c 같은 회귀모델을 이용한 smoothing을 수행합니다.
xi의 새로운 값은 양쪽 근방 2n+1 개의 점으로 다항식 회귀한 식으로부터 다시 추정해 내는 것이 핵심 아이디어입니다. 즉, xi 를 포함하고 있는 양쪽 근방 2n+1 개의 점으로 다항식 회귀한 식 Si을 찾고, Si(xi)로 xi 를 대체하는 것입니다. (** 2n+1인이유는 오른쪽으로 n개, 왼쪽으로 n개 , xi 1개해서 2n+1로 셉니다. 그래서 윈도우 갯수는 홀수입니다.) 아래 그림을 예제로 들면 25값을 기준으로 오른쪽으로3개 왼쪽으로3개값을 떼서 7개 데이터를 윈도우로 떼서 봅니다. 7개데이터를 가지고 회귀곡선을 새롭게 그린다음 25에 해당하는 Y값을 새로이 지정해줍니다.
여기서 가장 큰 문제는 xi를 구하기위해 앞뒤 데이터들을 합친 2n+1개 윈도우를 떼서 새로이 다항회귀식(si)를 재구성하는것입니다.
import os
import pandas as pd
import glob
import datetime
import matplotlib.pyplot as plt
import statsmodels.api as sm
import seaborn as sns
import statsmodels.api as sm
from scipy import stats
from sklearn.preprocessing import LabelEncoder
import numpy as np
#pd.options.display.float_format = '{:.10f}'.format #표 전체 다보이
# 안잘리게 설정
pd.set_option('display.max_row', 3000)
pd.set_option('display.max_columns', 1000)
breaks_rpt = []
for i in breaks:
breaks_rpt.append(Data_F.index[i-1])
#breaks_rpt = pd.to_datetime(breaks_rpt)
breaks_rpt
plt.plot(y, label='data')
print_legend = True
for i in breaks_rpt:
if print_legend:
plt.axvline(i, color='red',linestyle='dashed', label='breaks')
print_legend = False
else:
plt.axvline(i, color='red',linestyle='dashed')
plt.grid()
plt.legend()
plt.show()