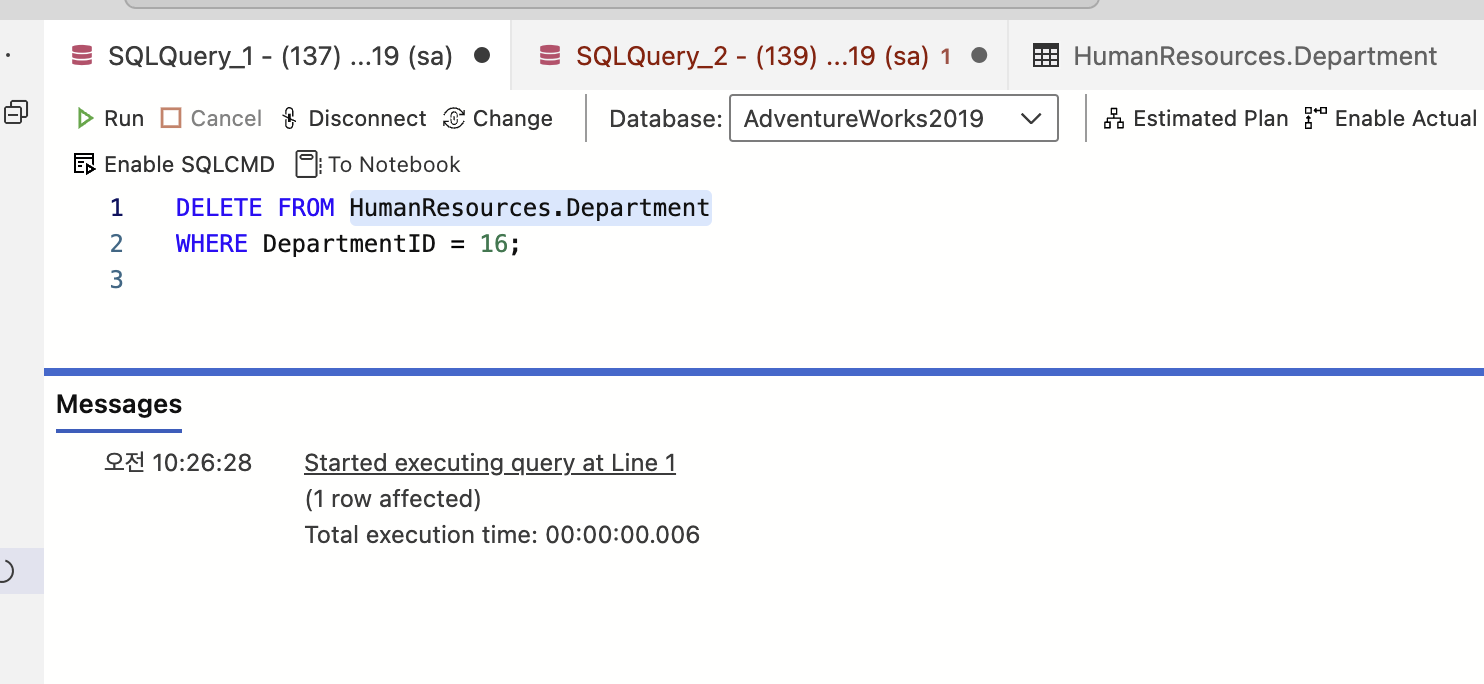
강의에서 하란대로 sql server express edition을 다운받아보았으나, 맥북이라 안됨 ^^
아래처럼 실습 환경 구축해서 진행함..
M2 맥북에서 AZURE SQL 실습환경 구축 (Data Studio+adventureworks.bak)
기본베이스는 https://learn.microsoft.com/ko-kr/sql/samples/adventureworks-install-configure?view=sql-server-ver16&tabs=data-studio#download-backup-files 이거 따라함 Azure Data Studio 설치하기 Azure SQL Server에서 [만들기] 눌러서
peanut159357.tistory.com


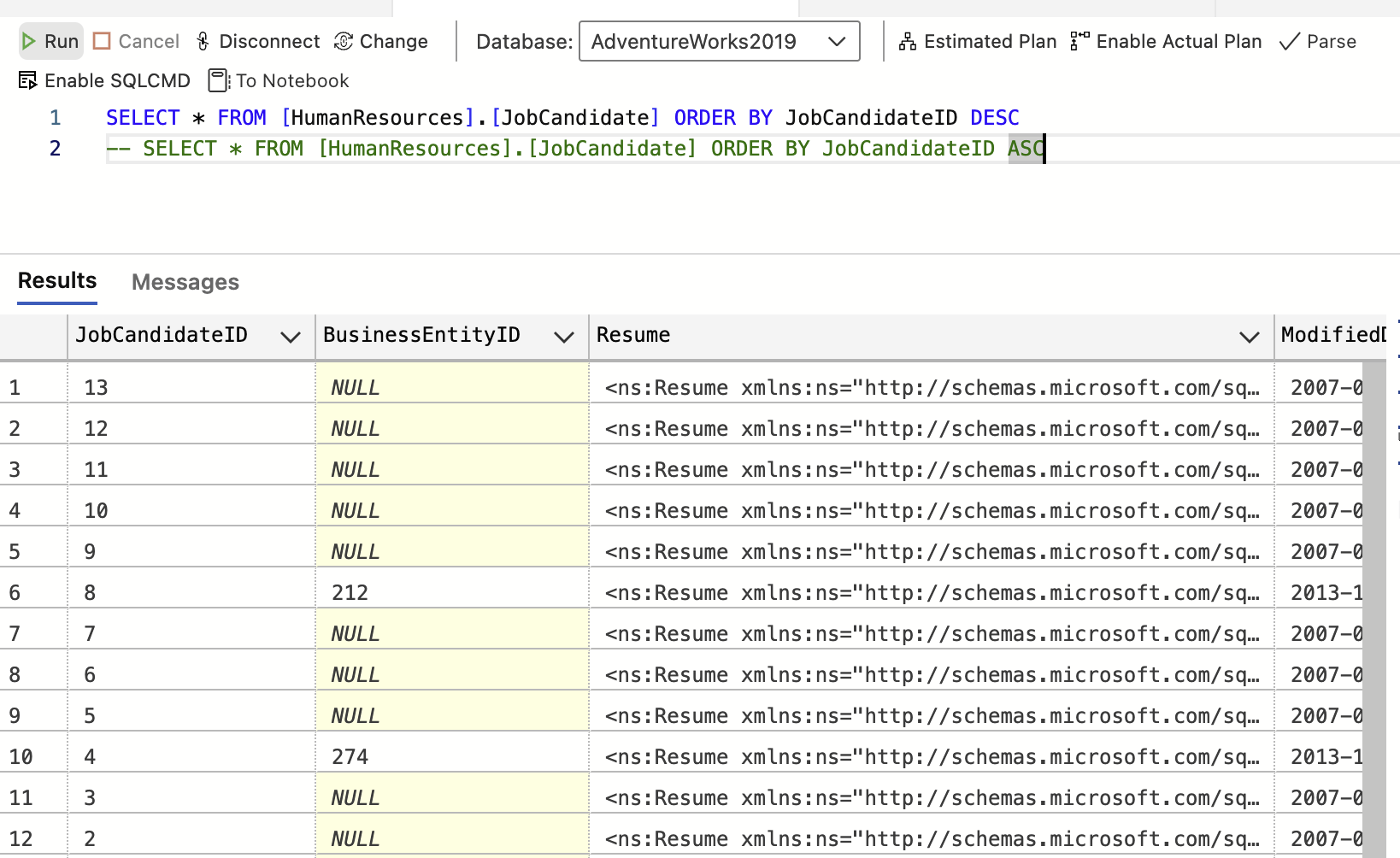

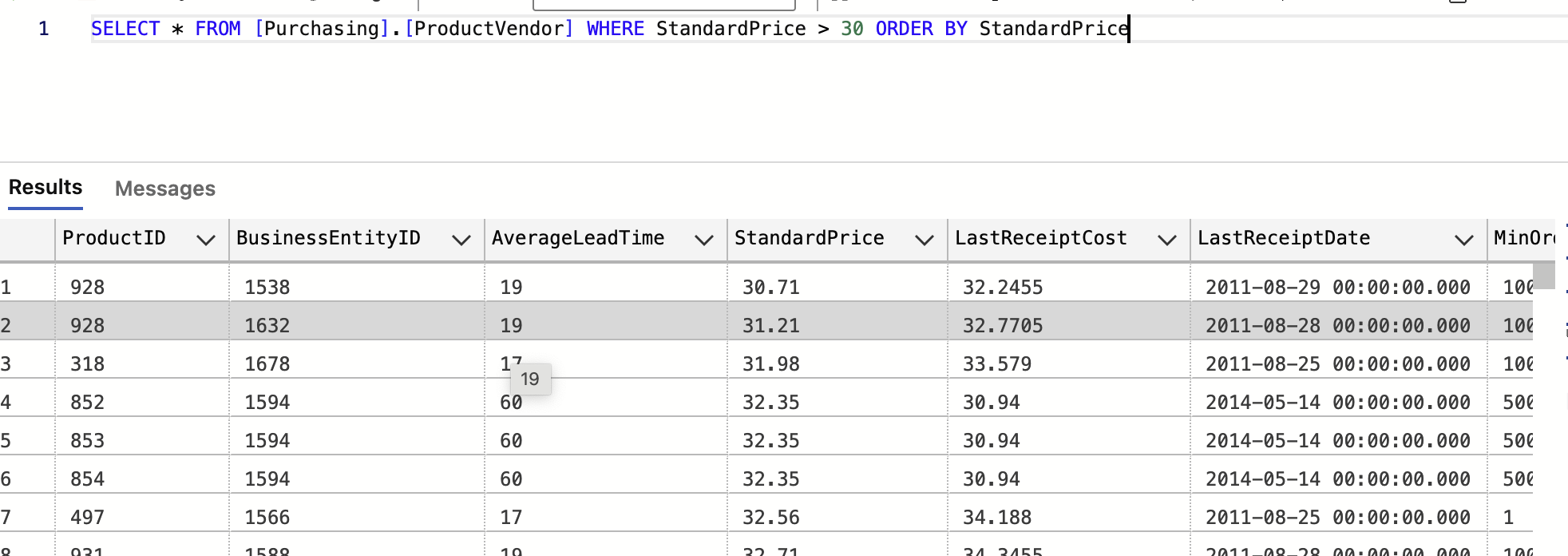
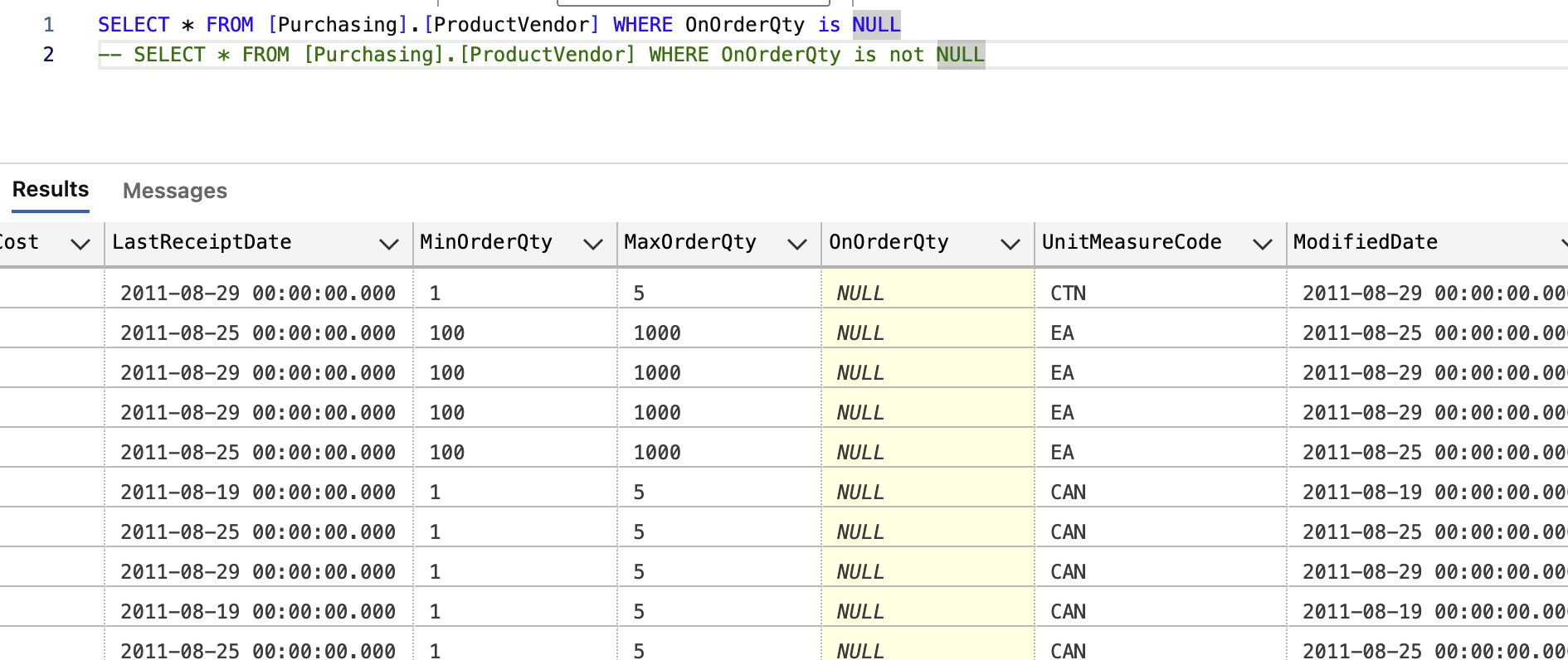
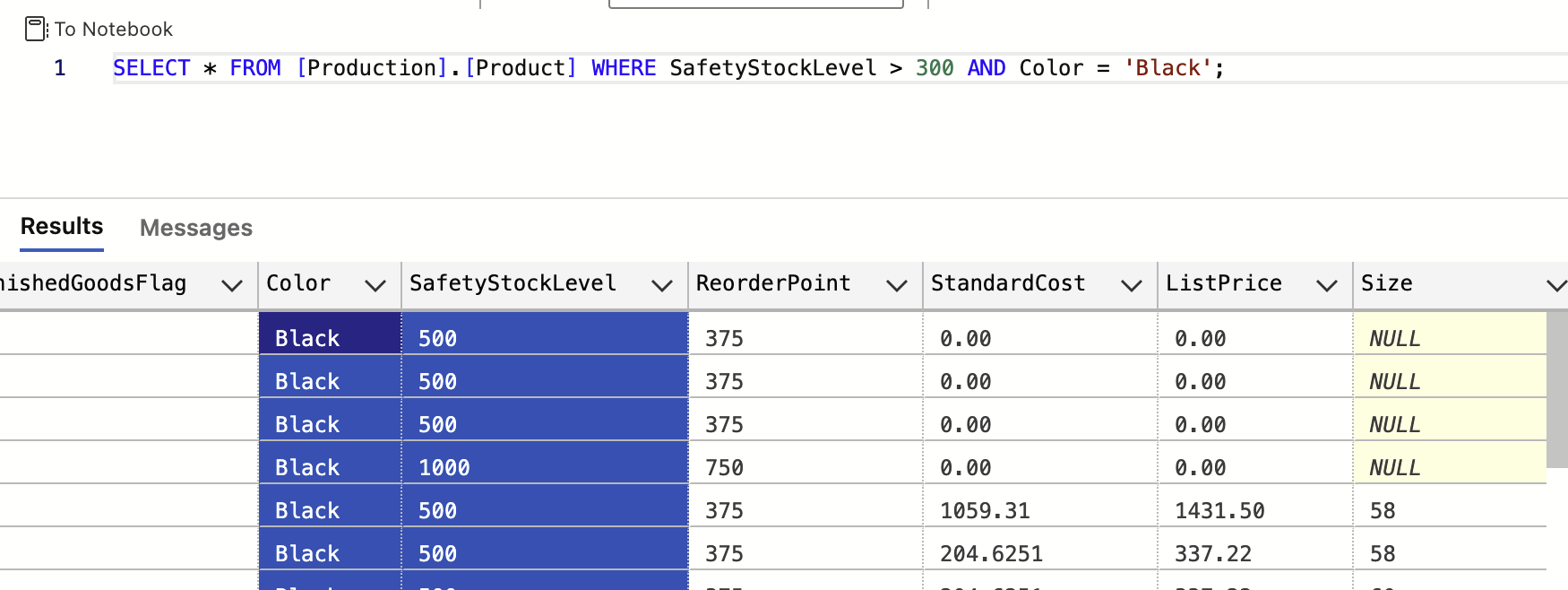

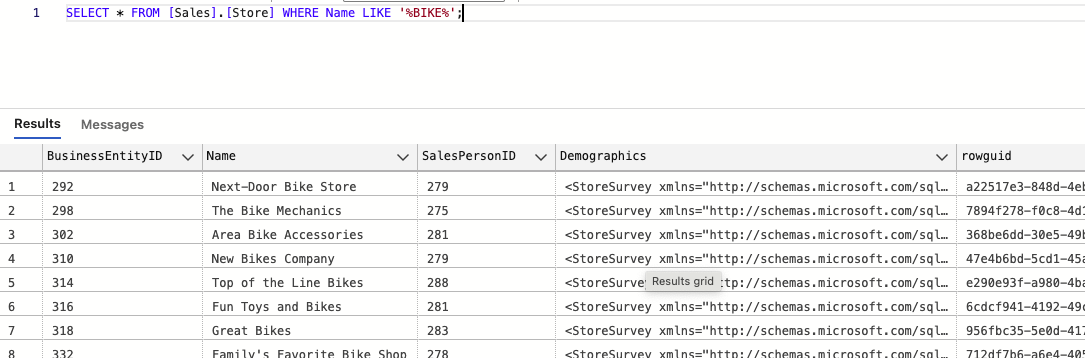

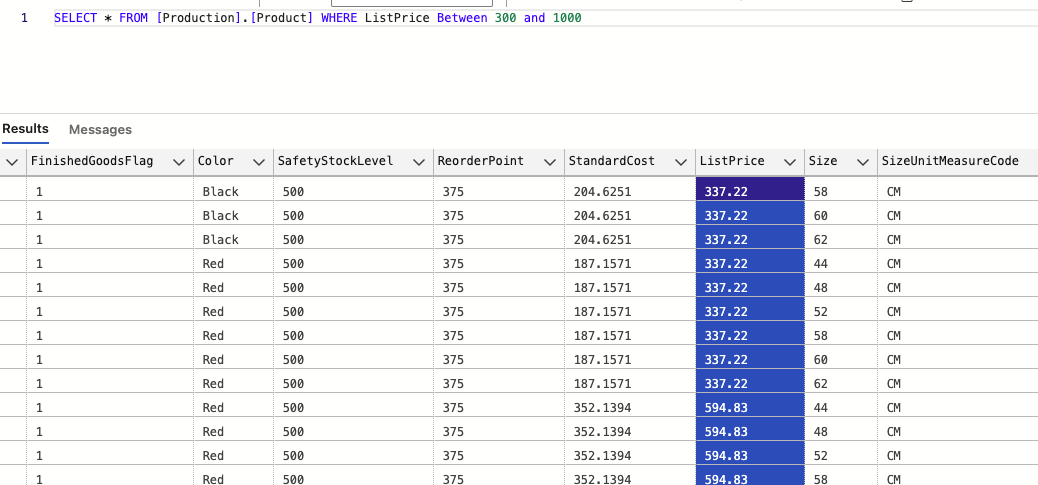

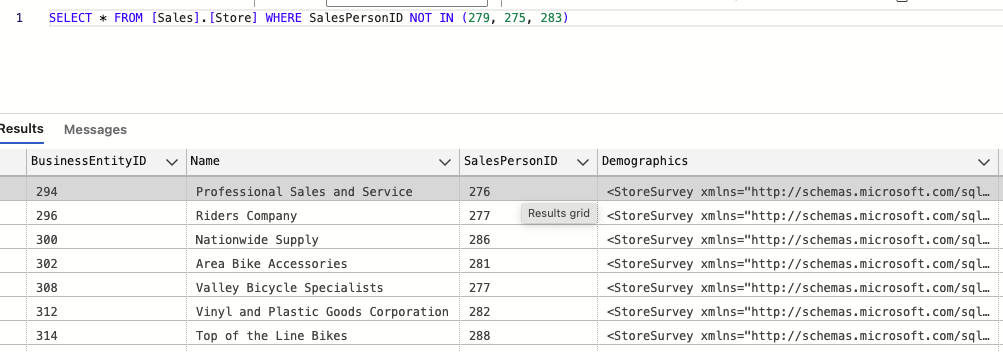
ㄴ or 를 대체해서 쓰는게 in / 100,200,300이 아닌경우 를 솎아낼때 쓰는용도로 유용 (실무에서 많이 쓰임)

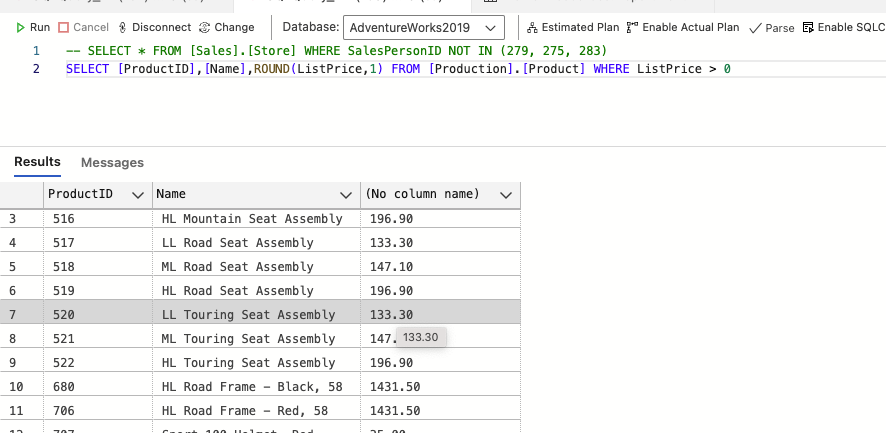

-- LEFT(X1,X2) / RIGHT(X1,X2)
SELECT [ModifiedData] LEFT([ModifiedData,10]) AS D_DATE, RIGHT([ModifiedData,12]) AS D_TIME FROM [Sales][Customer]문자열을 왼쪽에서 몇자까지만 보여주겠다 (왼쪽은 날짜만 나오게, 오른쪽은 시간만 나오게 조정 (as는 새로운 컬럼으로 만들어서 보여줌)
--SUBSTRING(x1,x2,x3) x1는 대상문자열, x2는 시작, x3은 종료
SELECT SUBSTRING('MS SQL DATABASE MANAGEMENT STUDIO',8,8) AS D_STRING위에서 너무 기니까 LEFT+RIGHT를 합친게 SUBSTRING
-- len()
SELECT LEN([AccountNumber]) FROM [Sales].[Customer]
-- COLUMN별로 몇개 길이를 가지고 있는지 출력해준다--REPLACE(x1,x2,x3) x1대사문자,x2지칭하는문자열, x3바꿔줄문자열
SELECT 'SQL IS SO DIFFICULT', REPLACE('SQL IS SO DIFFICULT', 'DIFFICULT','EASY') AS D_REP-- SYSDATETIME(), GETDATE()
SELECT GETDATE() AS T_DATE
-- YEAR(X1), MONTH(X1), DAY(X1)
YEAR(GETDATE()) AS T_Y, MONTH(GETDATE()) AS T_M,DAY(GETDATE()) AS T_D
-- DATEPART(x1,x2)
DATEPART(YY.GETDATE()) AS T_Y, DATEPART(MM.GETDATE()) AS T_M,
DATEPART(HH.GETDATE()) AS T_H, DATEPART(II.GETDATE()) AS T_I, DATEPART(SS.GETDATE()) AS T_S,
SELECT * FROM [Purchasing].[PurchaseOrderDetail]
WHERE DATEPART(YY,ModifiedDate)=2014 AND DATEPART(MM,ModifiedDate)=1-- DATEDIFF(x1,x2,x3) 두개사이의 간격 구하는것
SELET DATEDIFF(YY, '2020-01-01', GETDATE()) AS D_Y
-- OUTPUT = 2
SELECT DATEDIFF(YY, BirthDate, GETDATE()) AS D_AGE FROM [HumanResource].[Employee]
-- 위의 예제는 직원들 나이구하는것-- DATEADD(x1,x2,x3) x1대상, x2가 -3이면 3년을 뺴라는소리, x3은 now
SELECT DATEPART(W, DATEADD(DD,1000, '2020-01-01')) AS A_W
-- 위에는 요일을 출력하라는 뜻으로 6이 출력됨 (월요일이 1)<집계처리>
- STDEV 표준편차
- VAR 분산
- SUM 누적합계
- AVG 평균
- COUNT 총개수
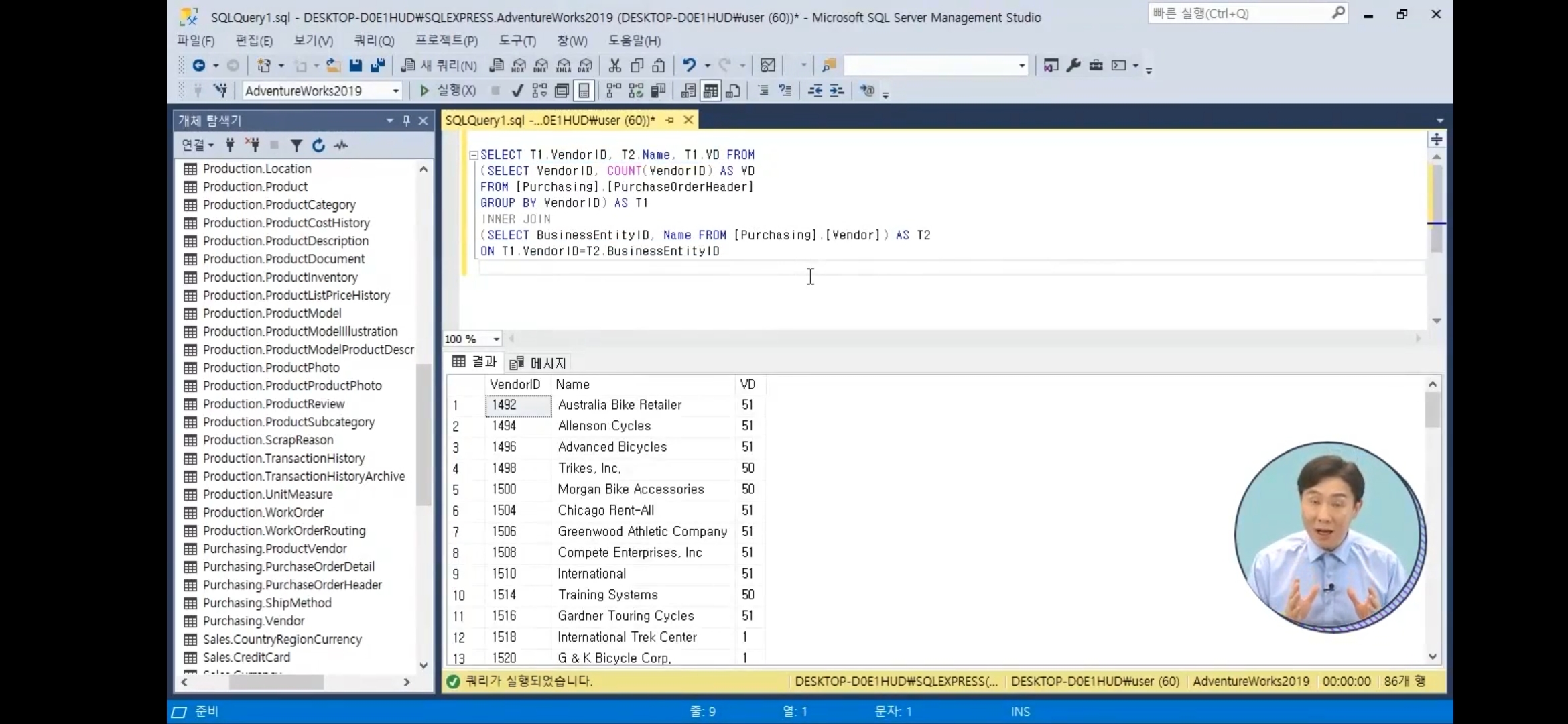
SELECT VendorID, Count(VendorID) AS CC
FROM [Purchasing].[PurchaseOrderHeadr]
WHERE VendorID>=1500
GROUP BY VendorID
ORDER BY COUNT(VenderID) DESC
-- 순서에 유념SELECT DATEPART(YY, OrderDate) AS A_Y, COUNT(DATEPART(YY, OrderDate)) AS CC
FROM [Purchasing].[PurchaseOrderHeader]
GROUP BY DATEPART(YY, OrderDate)
-- 년도만 보고, 년도별로 그룹핑해서 몇개인지 알아보려는 용도-- SELECT Color, ListPrice FROM [Production].[Product]
-- WHERE Color IS NOT NULL
-- GROUP BY Color
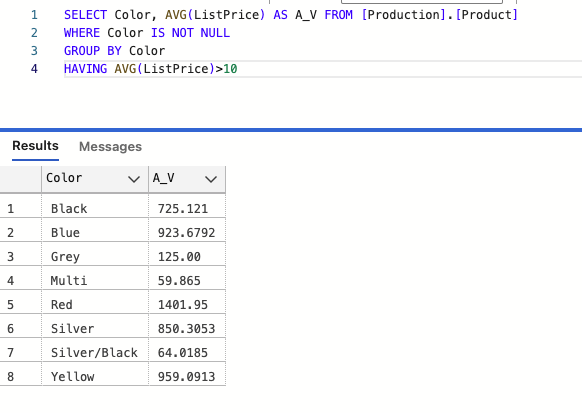
SELECT Color, AVG(ListPrice) AS A_V FROM [Production].[Product]
WHERE Color IS NOT NULL
GROUP BY Color
HAVING AVG(ListPrice)>10중요) 집계가 이뤄지고난 후에 값들은 having 을 통해 지정되어야함
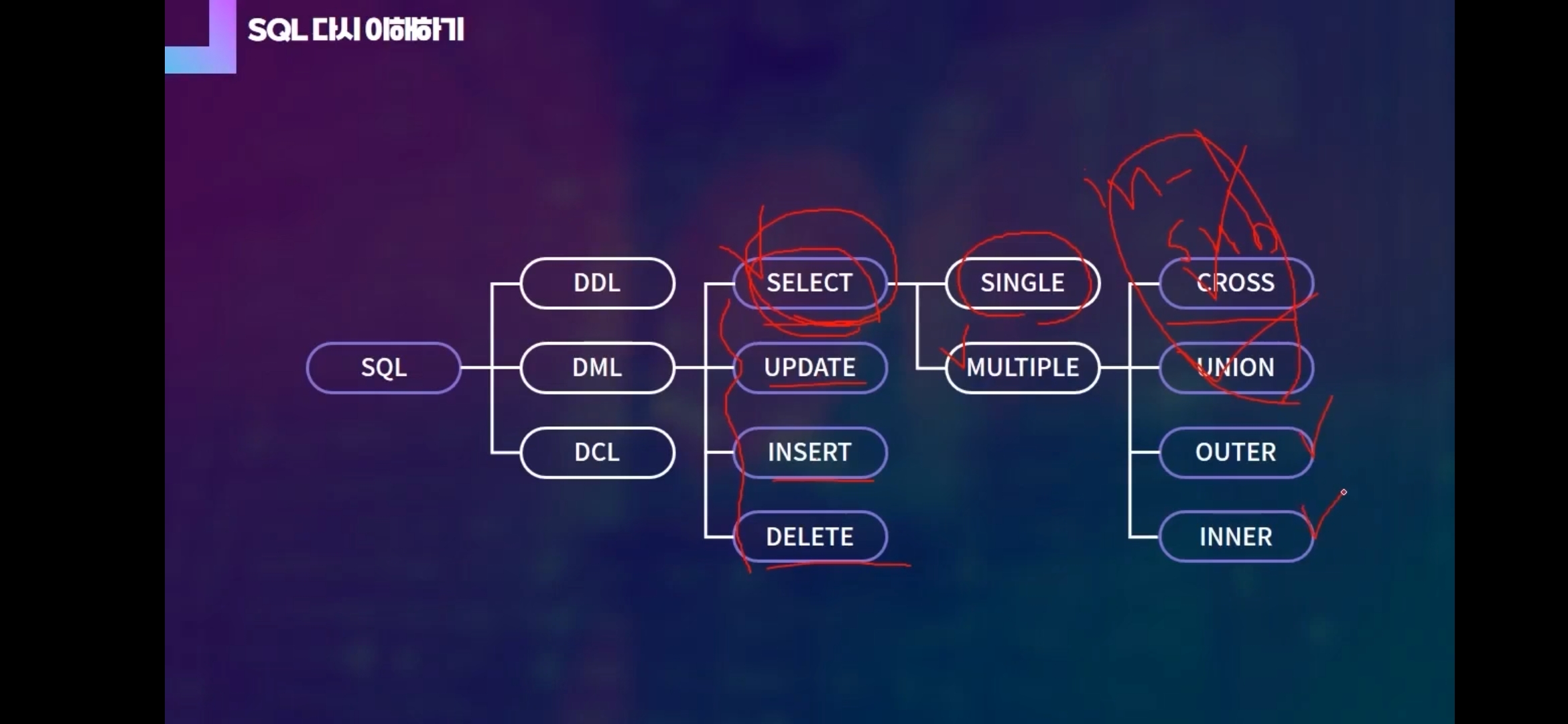
IN-LINE VEIW

-- SELECT Color, AVG(ListPrice) AS A_V FROM [Production].[Product]
-- WHERE Color IS NOT NULL
-- GROUP BY Color
-- HAVING AVG(ListPrice)>10
-- 이걸 아래 인라인뷰를 사용해서 똑같이 만들어보자
SELECT * FROM
(SELECT Color, AVG(ListPrice) AS A_V FROM [Production].[Product]
WHERE Color IS NOT NULL
GROUP BY Color) AS TEMP_T
WHERE A_V>10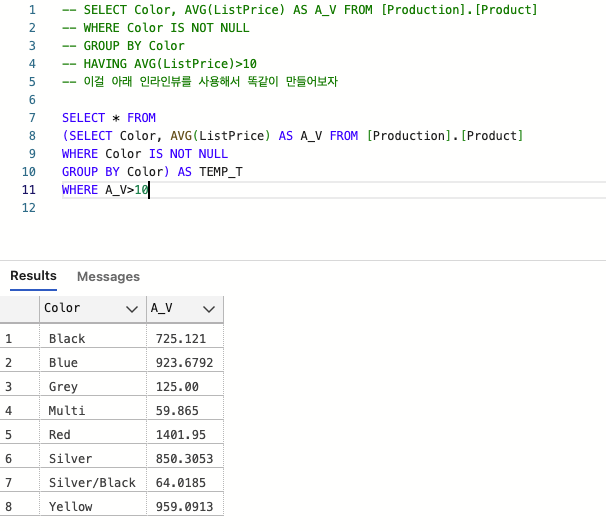
SUBQEURY
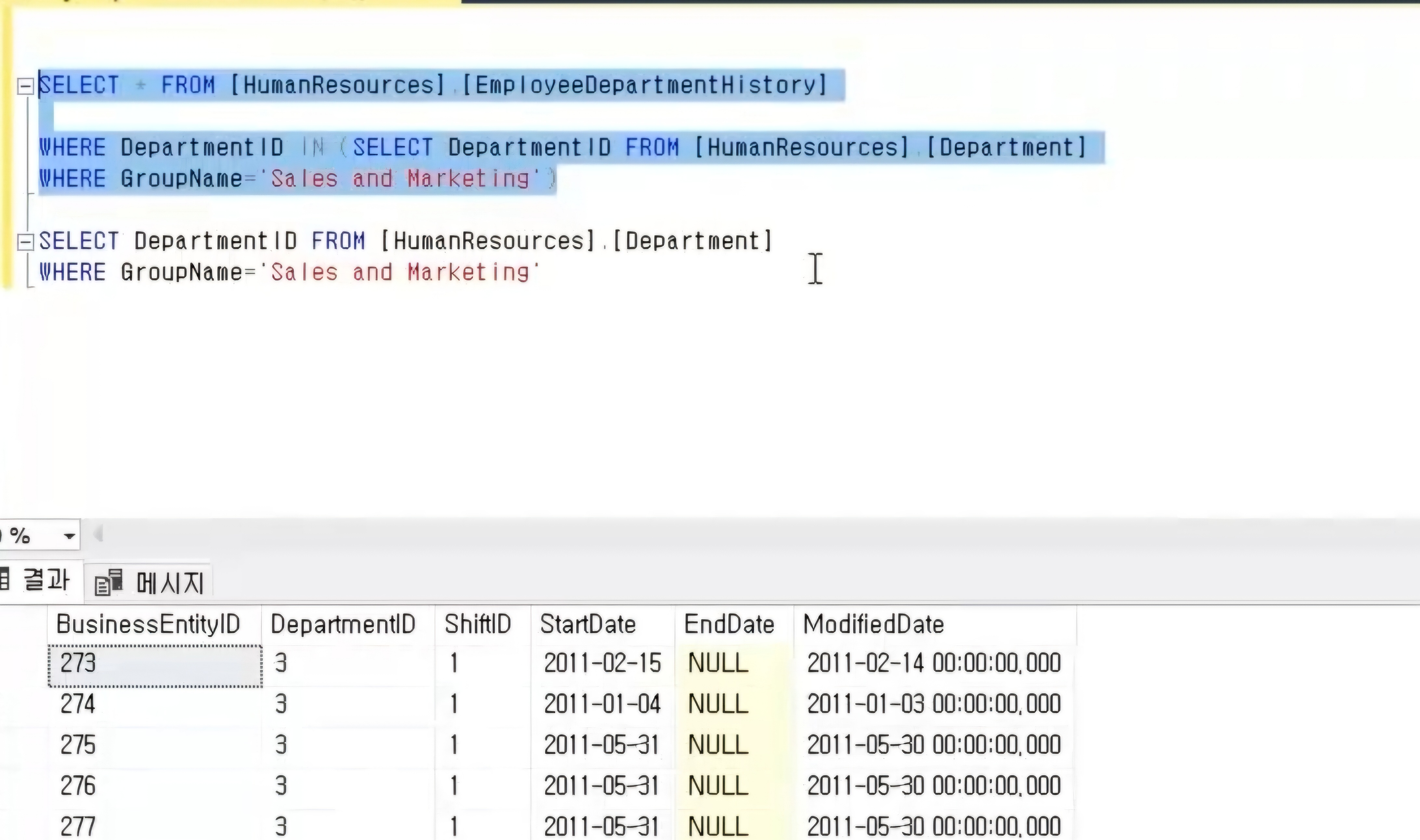
OUTER JOIN
**인라인 사용

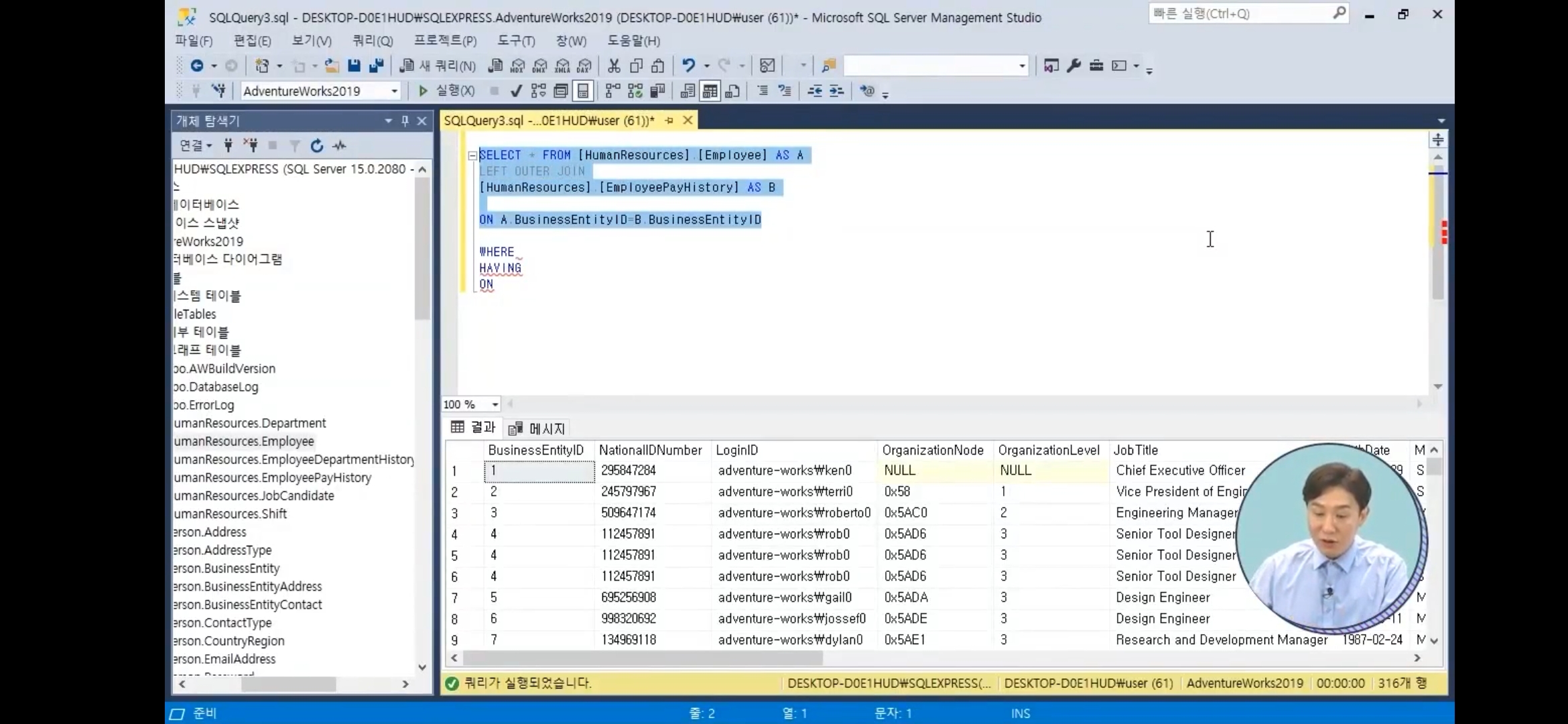
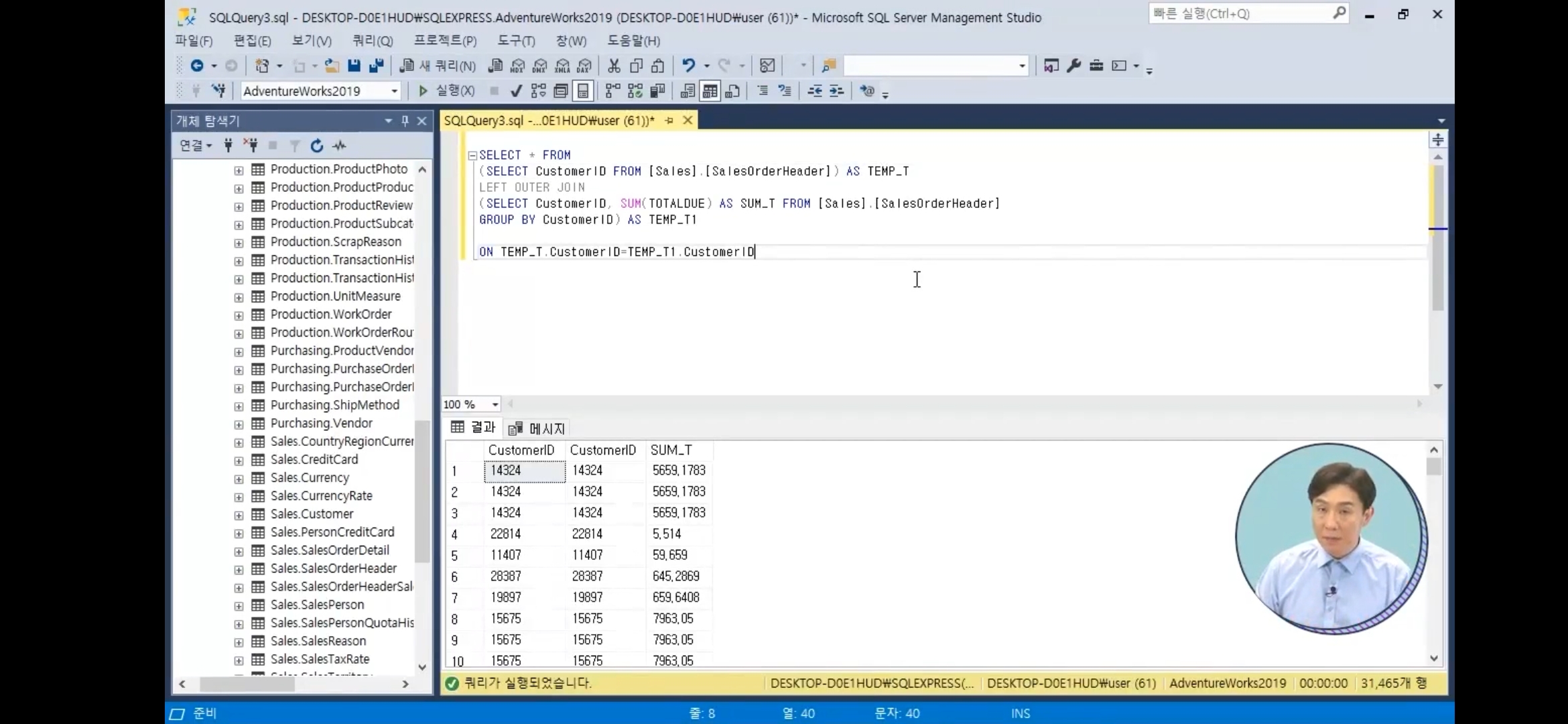
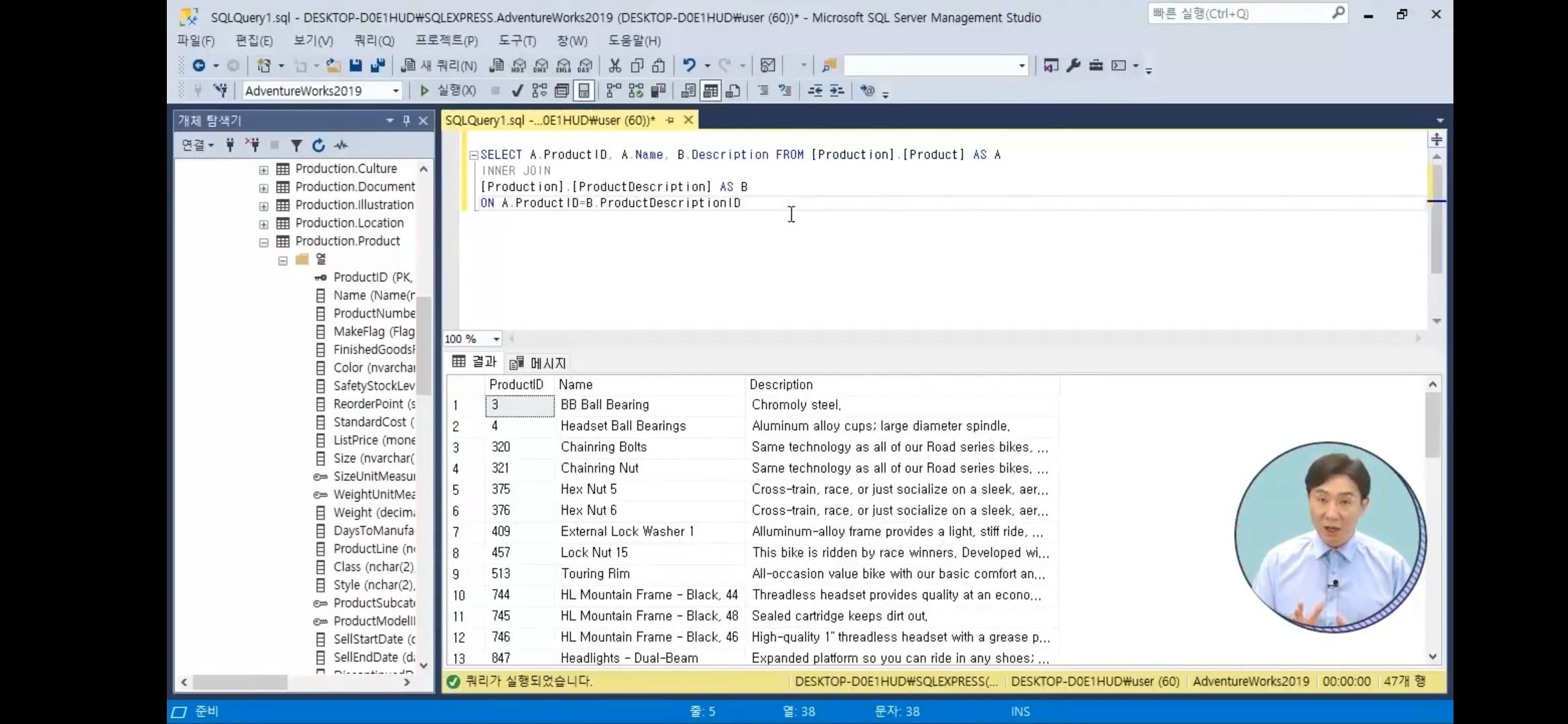
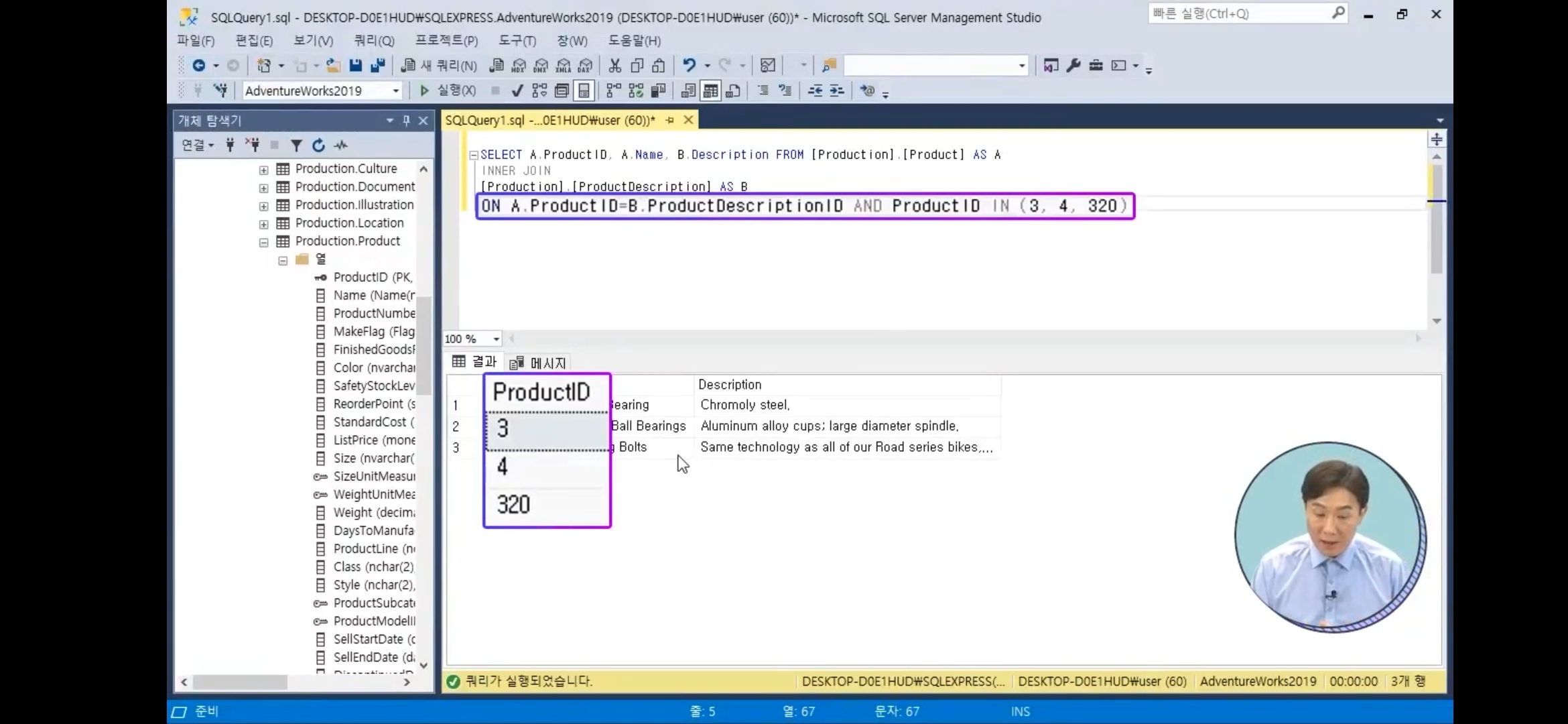
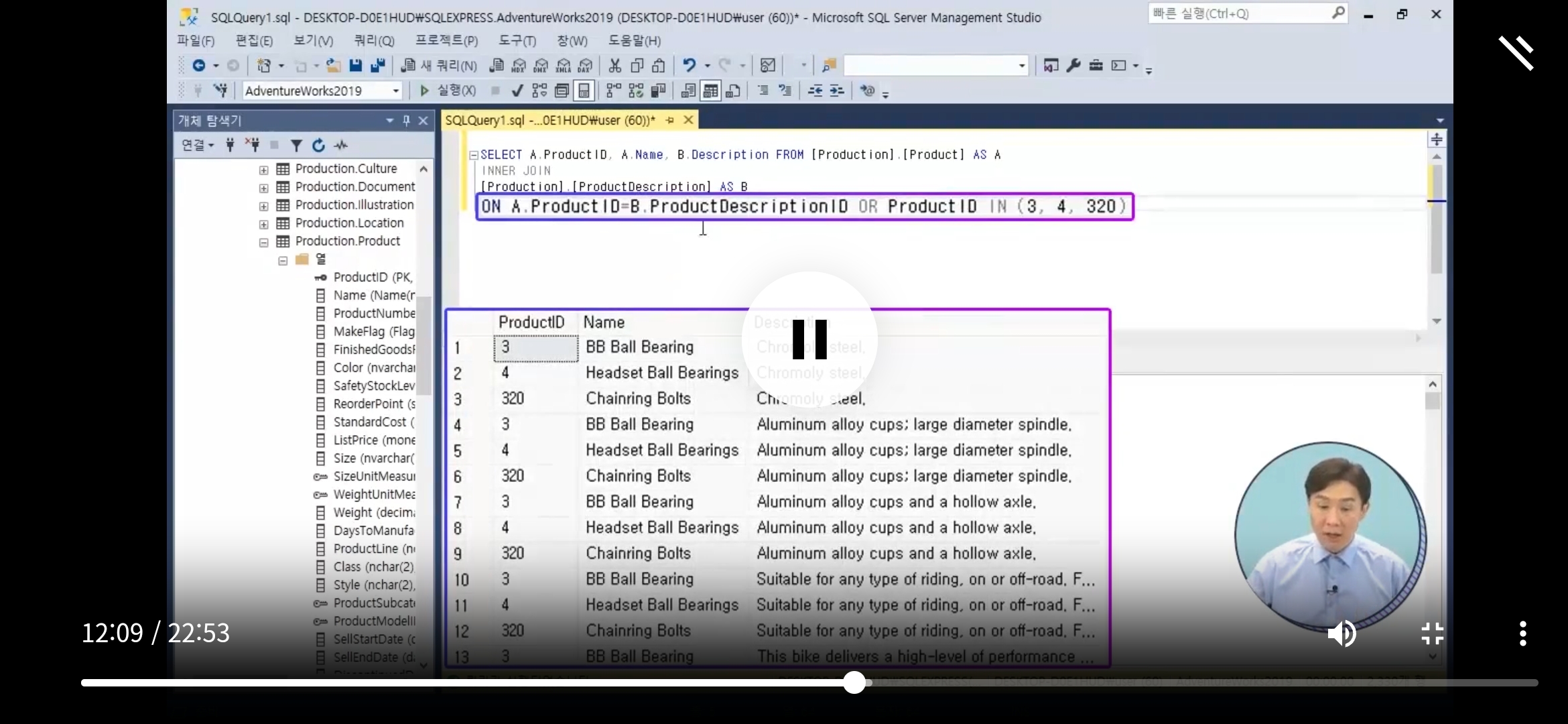
INNER JOIN

'<문법>' 카테고리의 다른 글
| 리눅스 명령어 목록 (0) | 2021.04.17 |
|---|