STRATIX 10 NX 의 구조랑 성능비교 ....
1. Brainwave NPU overlay architecture

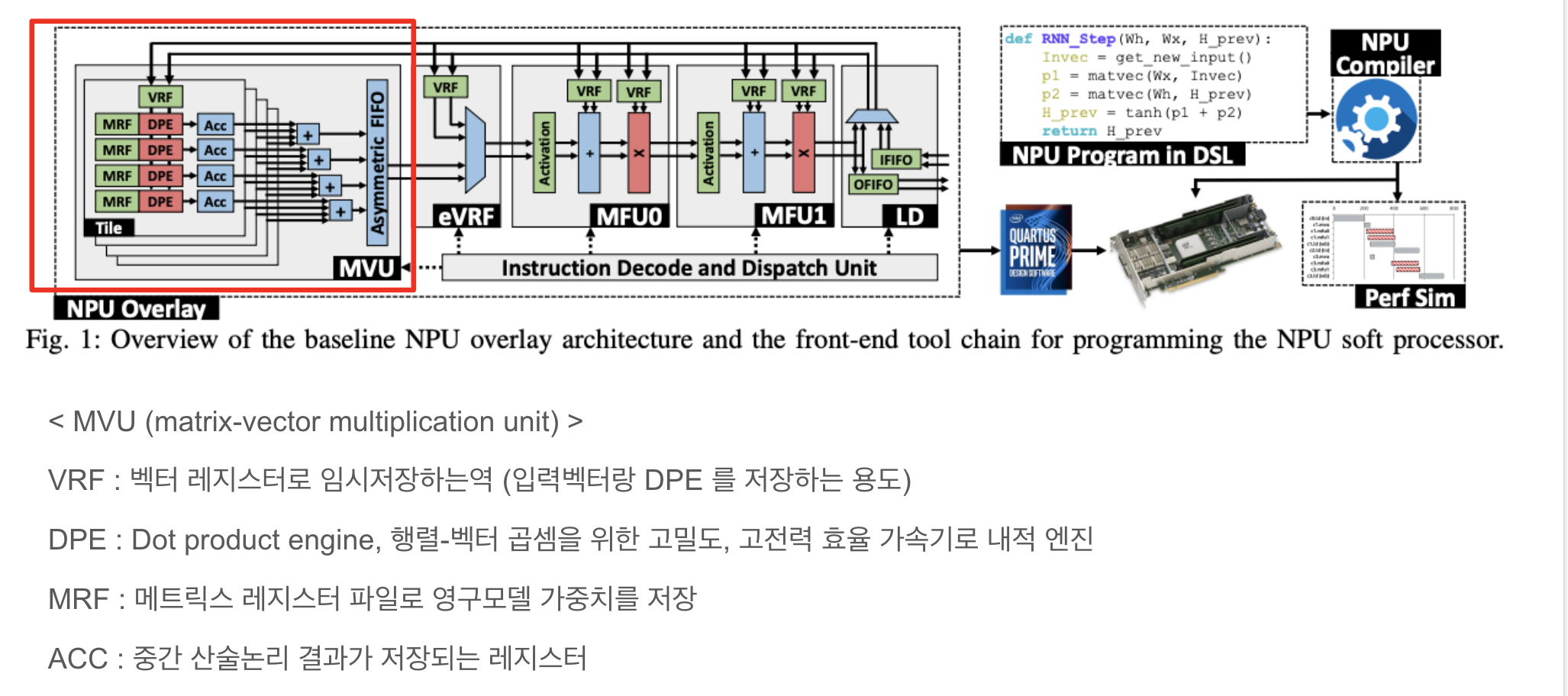



2. tensor block 구조


텐서 블록에는 3개의 내적 단위가 포함되어 있으며, 각 단위에는 10개의 8×8 승수와 3개의 선택적 누산기(ACC) 가 있음.
** DOT (곱셈) - 벡터끼리의 곱셈을 의미함
** 승수 : 승수란 어떤 수에 다른 수를 나누거나 어떤 식에 다른 식을 곱할 때, 그 나중의 수나 식을 말한다.
** ACC (누산기) : 연산된 결과를 일시적으로 저장해주는 레지스터로 연산의 중심

** 레지스터
레지스터는 비트 패턴을 저장하는 플립플롭 그룹입니다. FPGA의 레지스터에는 클럭, 입력 데이터, 출력 데이터 및 활성화 신호 포트가 있습니다. 클록 주기마다 입력 데이터가 래치되어 내부에 저장되고 출력 데이터가 내부에 저장된 데이터와 일치하도록 업데이트됩니다.

그림 3은 이 모드에서 AI 텐서 블록의 동작을 보여줌
각 주기에 내적 단위를 공급하는 레지스터 뱅크는 점선 상자로 표시됩니다. 3 클럭 사이클 후에 해당 피연산자의 모양과 색상을 사용하여 출력이 생성됩니다.
주황별 :역시 인풋벡터인데 무색 모양은 3개의 내적 단위로 브로드캐스트되는 텐서 블록의 데이터 포트에 대한 입력 벡터입니다.
유색원 : 레지스터 뱅크로 들어온 인풋벡터값
3. baseline 기반으로한 리얼구조

아까 베이스라인 npu 구조 에서 더 발전시킨것이 Stratix 10 NX Npu
- ** 타일이 왜 두개로 나뉨? (인풋레인이 2개라서)
- 베이스라인 NPU에서 2개의 타일 및 DPE를 갖는 MVU에 대한 매트릭스-벡터 연산의 매핑을 예제로 들고있다.
- DPE는 여러 주기에 걸쳐 입력 벡터의 블록과 행렬 행 블록 간의 내적을 수행
- 그런 다음 다른 타일에서 해당 DPE의 출력을 줄여 행렬의 다음 행 블록으로 진행하기 전에 최종 결과를 생성

- 대신에 다음그림처럼 여러가지 결과를 저장하기위해 BRAM 기반 누산기(=MVU)를 구현. (BRAM = block ram)
- dual-port RAM. 듀얼 포트 램이므로 한 사이클에 2개의 주소로부터 값을 읽거나 쓰기가 가능
- BRAM 이 여기서 하는일은 기본적으로 스토리지의 역할을 하며 read/write 속도가 매우 빠르다고함/ On-Chip 메모리 ( 메모리가 칩위에 있다는 의미/ 메모리가 칩 위에 있기 때문에 버스(Bus)를 사용하지 않고 바로 메모리에 접근할 수 있다 / BRAM 은 기본적으로 FPGA안에 필요한 정보, data를 저장하는 공간이다 )
*BRAM ? Xilinx FPGA 내부의 SRAM 의 한 종류를 BRAM 이라 부릅니다. (Xilinx FPGA 에는 URAM 도 있습니다.) Intel FPGA 은 BRAM 역할을, Embedded Memory 라고 부르구요.
- 결과적으로 타일 간 감소를 수행하기 위해 각 타일에서 중앙 가산기 트리로 넓은 버스를 라우팅하면 상당한 라우팅 혼잡이 발생할 수 있습니다
- 라우팅 혼잡을 완화하기 위해 그림 4c와 같이 각 타일이 이전 타일의 결과를 가져오고 로컬 이진 축소를 수행하고 결과를 다음 타일로 전달하는 데이지 체인 아키텍처를 갖도록 MVU를 재설계합니다. .
- 이 아키텍처는 각각의 두 개의 연속 타일 사이에 더 짧고 더 지역화된 라우팅을 사용하며 몇 사이클 더 높은 대기 시간을 희생하면서 더 효율적이고 라우팅 친화적인 것으로 밝혀졌다.

4. 성능비교

** ALM = 해당 제품군의 베이직 빌딩블록
** 빌딩블록 = 컴터를 구성하는 여러가지종류의 기본 회로들을 지칭함
** TOPS = 초당 1조 연산속도 (15TOPS = 1초에 15조번 연산)
**PEAK TOPS 는 MVU 에서만 국한지음

** GEMV = 일반 행렬곱
** GEOMEAN = 기하평균 ( n개 양수값을 모두 곱한다음 n제곱근을 구함)
** 1개의 배치로부터 loss를 계산한 후 Weight와 Bias를 1회 업데이트하는 것을 1 Step이라고 한다.
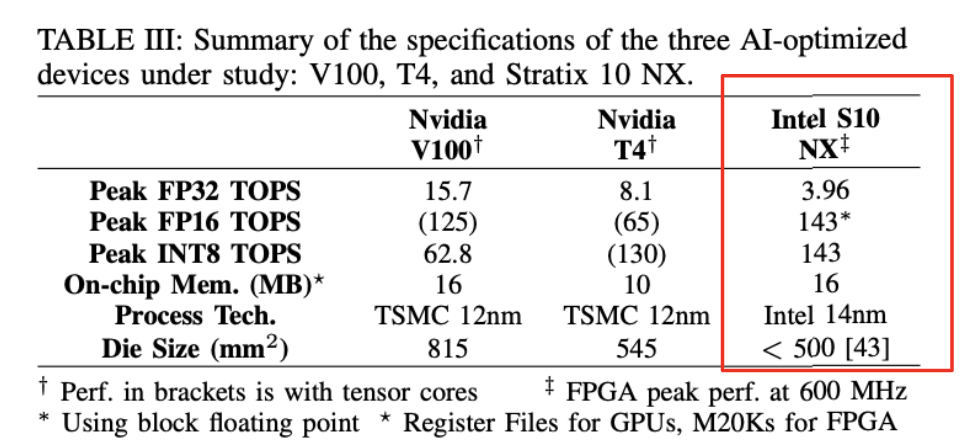
** 오프칩 : CPU와 주기억장치, I/O Port가 외부에 존재하는 것
** DIE size = 집적회로의 물리적인 크기 (길이,너비) https://en.wikichip.org/wiki/die_size
** TSMC 반도체 위탁제조회사
**12nm 제조공정에서 만들어진 프로세서 이름
** V100 p3 / T4 g4dn

그림 6은 T4 및 V100 GPU에서 fp32, fp16 및 int8 정밀도에 대한 GEMM 마이크로 벤치마킹 결과를 보여줍니다.
빨간점선 : 2048 이하의 매트릭(행렬) 크기에서 최고 성능(빨간색 점선)
** GEMM = 행렬곱
** throughput 한마디로 단위시간당 처리할수 있는양이라고 보면됨.
- 결과는 텐서 코어가 비활성화된 경우(파란색 선)에 비해 텐서 코어가 GEMM(빨간색 선)에서 GPU의 성능을 크게 향상시킬 수 있음을 보여줌
- T4 및 V100의 텐서 코어는 fp32 정밀도를 지원하지 않습니다. 대신 fp32 데이터는 텐서 코어에서 곱셈 연산을 실행하기 전에 fp16으로 변환됩니다[45]. 이 데이터 변환 오버헤드는 순수 fp16 GEMM에 비해 텐서 코어 성능을 감소시킵니다
- 결과적으로 텐서 코어(마커가 없는 빨간색 선)에서 달성된 int8 성능은 매우 큰 8192 × 8192 행렬을 처리할 때도 최고 성능의 45% 미만
- GEMM 워크로드에서 T4와 유사한 성능을 달성합니다. ++ FPGA의 재구성 가능성을 활용하여 NX 텐서 블록을 조금 변환하여 GEMM용 NPU 오버레이를 사용자 정의할 수 있습니다. 그런데 이건 이 논문의 주제랑 조금 벗어나다고 하여 거기까지는 하지않았음

** GRU ( lstm 이랑 비슷한데 다른모델임)
** GENV 일반행렬 벡터곱
**GEOMEAN 기하평균값
- Stratix 10 NX의 향상된 NPU 성능을 최고의 T4 및 V100 성능과 비교합니다. NPU 성능은 크기가 3과 6인 소규모 배치의 경우 두 GPU보다 항상 훨씬 높습니다.
=> NPU는 배치 6(각각 배치 3에서 2개의 코어용으로 설계됨)에서 24.2배 및 11.7배 더 높은 성능을 보입니다.
=> 이러한 결과는 FPGA가 low- 배치를 사용한 실시간 추론에서 GPU보다 10배 더 나은 성능을 달성할 수 있다.

** TACC - 텍사스 대학교 컴퓨팅 센터
** BW = bandwidth
** virt linux = EC2 g4dn

다음을 보면 GPU개랑 NPU 에서 대역폭을 측정하고 있습니다. (좌 - 대역폭 / 우 : 대역폭 활용률)
측정된 대역폭은 먼저 데이터 크기가 증가할수록 늘어나는것을 볼수 있다.
T4 는 aws 가상화로 인해서 훨씬더 낮은 대역폭을 보인다. (가상 머신의 물리적 메모리에 고정된 메모리 공간에서 GPU 입력 데이터를 보낼 때)
(두번쨰그림) FPGA는 최대 90% 활용으로 100G 이더넷 인터페이스를 최대한 활용하는 반면, V100은 최대 128Gbps PCIe 대역폭의 최대 80%만 활용할 수 있습니다.
'<눈문,학회>' 카테고리의 다른 글
| 논문쓰기 TIP (0) | 2023.07.17 |
|---|---|
| Habitat Wave Scaling (0) | 2022.05.31 |
| AI Gauge: Runtime Estimation for Deep Learning in the Cloud (0) | 2021.09.09 |
| Cost-Effective Data Analytics across Multiple Cloud Regions (0) | 2021.08.31 |
| Horus: Interference-Aware and Prediction-Based Scheduling in Deep Learning Systems (0) | 2021.08.14 |