- transformer 구조을 알기 위해서는 attention is all you need라는 논문을 보면된다.
- transformer 구조는 아래그림과 같다.

- 여기서 정리할것들
- self attention
- multi head attention
- feed forward
- add & Norm
1. Self Attention
참조 (아래 더보기 클릭)
- 위의 구조가 self-attention의 핵심구조이다.
- (MASK 모듈은 생성형 AI에 주로 쓰이니 생략해도 된다고 함)
<self attention 설명>
- embedding_dimension이 d_model
- I love you가 입력 x 이고 가로는 d_m or d_model이라고 부를거고 세로는 T개라고 명명하겠음
- wq,wk,wv는 파라미터
- Q,K,V는 X(입력벡터시퀀스)에 WQ,Wk,WV를 곱해서 구해준다.
- WQ,Wk,WV는 Task(예: 기계 번역)를 가장 잘 수행하는 방향으로 학습 과정에서 업데이트됨
- QK^T를 곱한 이유는 각 단어와 단어간의 상관관계를 보기위해서
- Q의 (0,0) K의 (0,0)를 곱한숫자는 I와 I간의 상관관계가 어느정도인지 나타낸것과 같다고 볼 수 있다.
- dk^1/2를 나눠주는 이유는 숫자가 극단적으로 갈수있는것을 예방하여 smoothing 한것과 동일하게 이해하면 된다
- softmax를 적용한이유는 0-1사이의 숫자로 나타내주기위함
- softmax(QK^T)를 해준다음 V를 곱한것의 의미는
- I love you라는 문장에 각 i,love,you와의 상관관계를 적용해준것과 같다.
- 예를들어서 배를 먹었더니 배가 아프다 라는 문장에서 먹는배와 , 신체 배의 차이를 극대화하는 과정과 같다. 먹었다,아프다 라는단어와의 상관관계를 분석하여 배라는 단어가 어떤것에 더 가까운지 확실히하는 과정이라고 생각하면 된다.
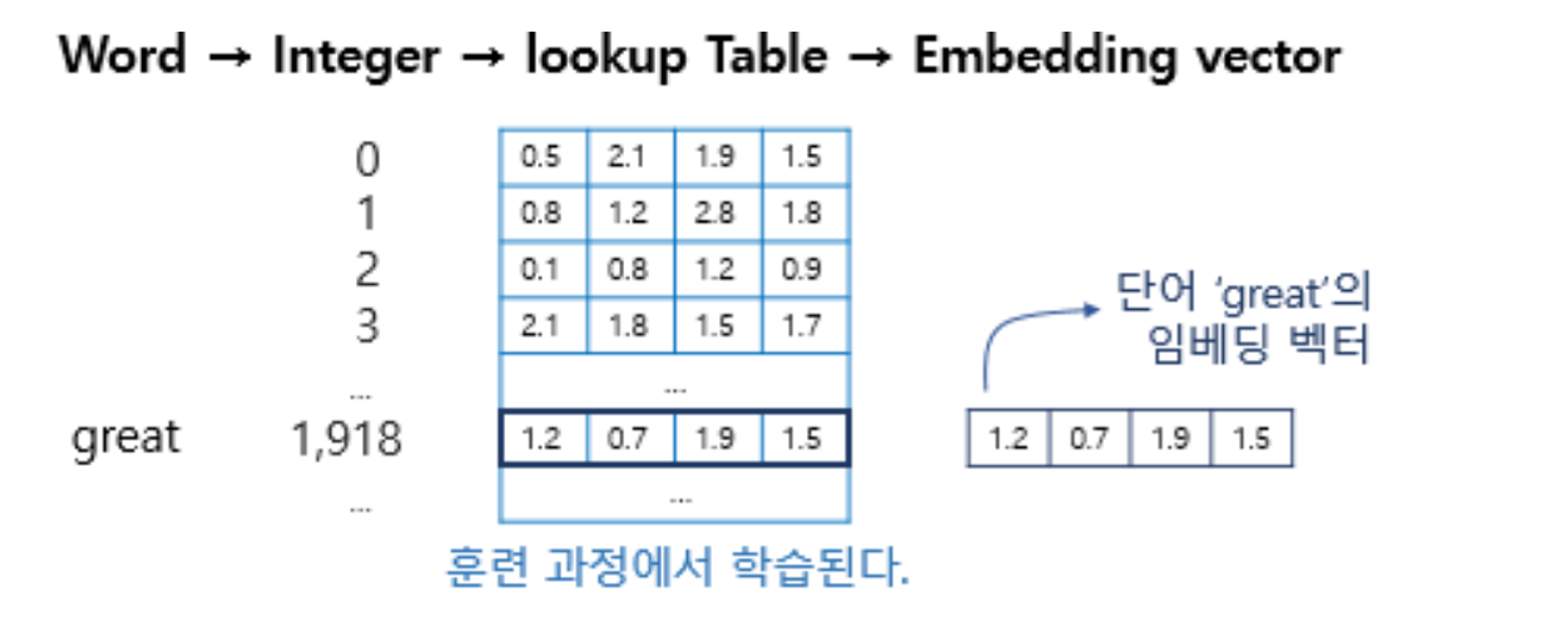
- 위사진에서 4, embedding dimension이 의미하는것은?
- 자연어처리에서는 단어가 들어오면 단어를 토큰화하고, word embedding을 통해서 벡터화한다.
- 어떤흐름으로 진행되는지는 아래 그림을 참조
- integer부분이 토큰화, lookup table에서 한줄 뽑아온것(위그림의 단어별로 존재하는 리스트) 바로 임베딩 벡터를 의미한다.
- 자연어처리에서는 단어가 들어오면 단어를 토큰화하고, word embedding을 통해서 벡터화한다.
⇒ 한마디로 이과정은 각각의 단어들을 비교해서 문맥을 파악하고, 벡터표현값을 업데이트하는 과정
< 헷갈리는것들 >
여기서 간과하면 안되는점 : Wq의 크기는 d_model x d_model이다. (Tx d_model) x (d_model*d_model) 이렇게 행렬곱셈을 하면 결과값 크기도 input과 동일한 T x d_model이 나옴
<추가설명>
- 위사진에서 4, embedding dimension이 의미하는것은?
- 자연어처리에서는 단어가 들어오면 단어를 토큰화하고, word embedding을 통해서 벡터화한다.
- 어떤흐름으로 진행되는지는 아래 그림을 참조하자
- 아래그림에서 integer부분이 토큰화, lookup table에서 한줄 뽑아온것(위그림의 단어별로 존재하는 리스트) 바로 임베딩 벡터를 의미한다.
- 자연어처리에서는 단어가 들어오면 단어를 토큰화하고, word embedding을 통해서 벡터화한다.
2. Multihead attention
참조 (아래 더보기 클릭)
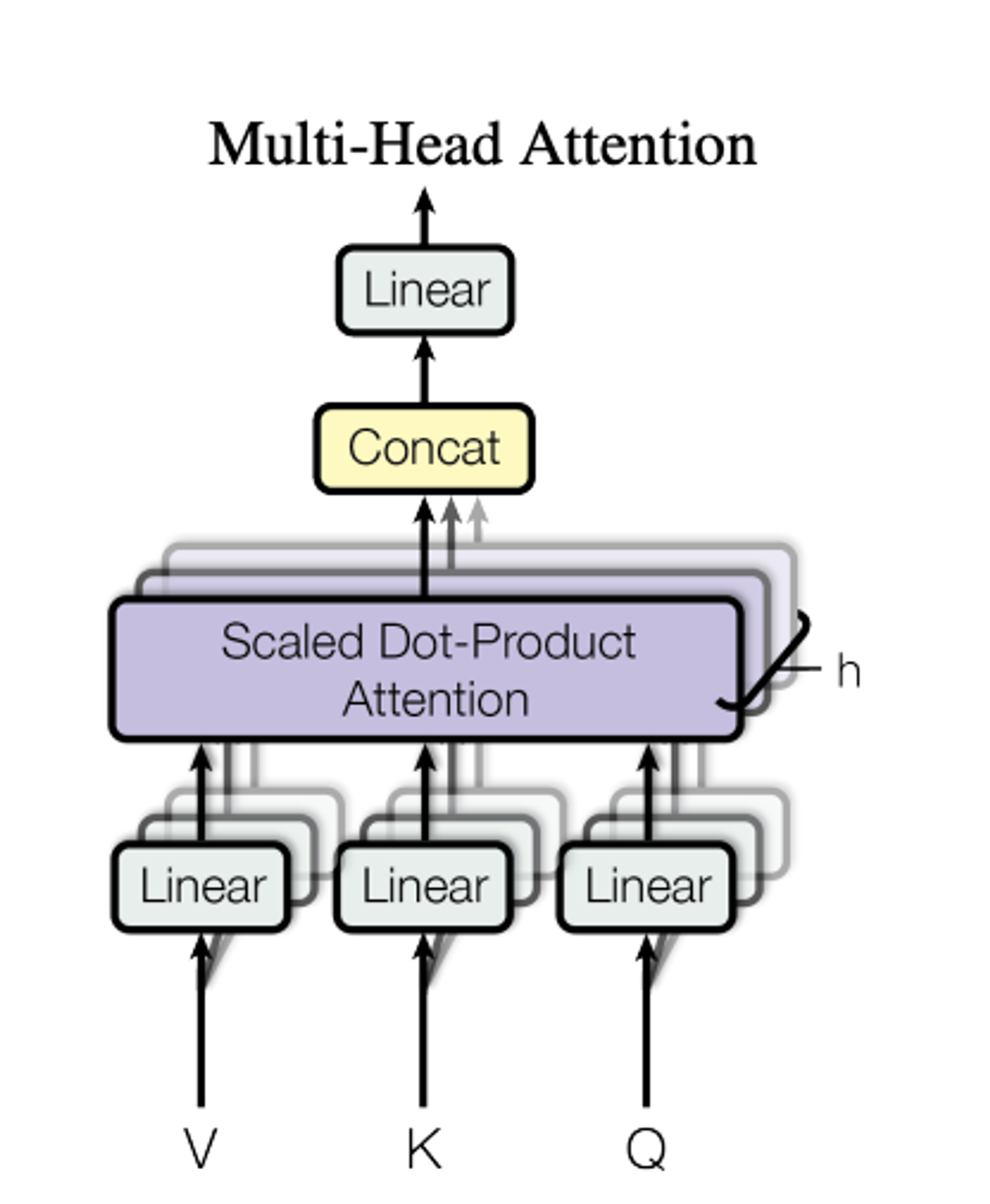
위 그림이 논문에 나온 그림이다.

- h는 사용자가 직접 정해준다. 멀티헤드를 몇개로 지정해줄것인가를 뜻한다.
- h(멀티헤드 갯수)를 직접 정해주지않으면 디폴트값은 12개이다.
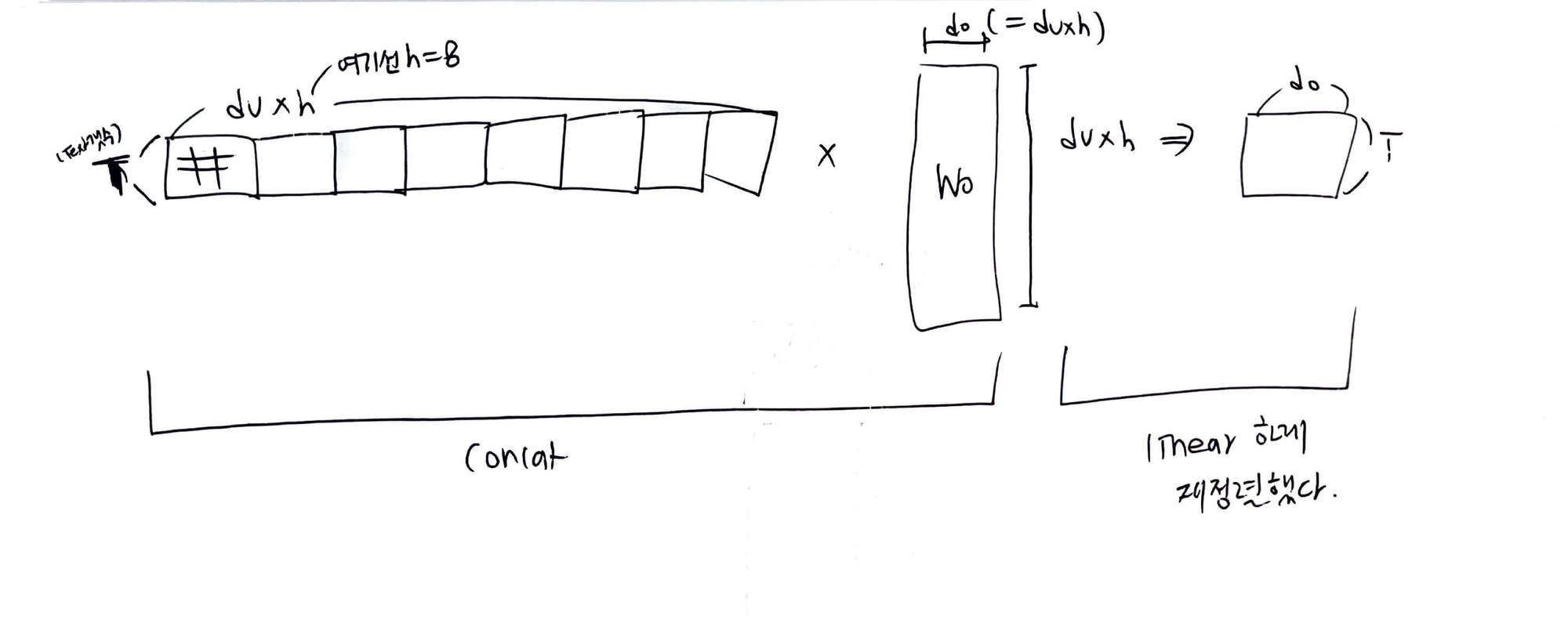
- 앞에서 self attention으로 구한 블럭을 가로로 나란히 h개 붙인다
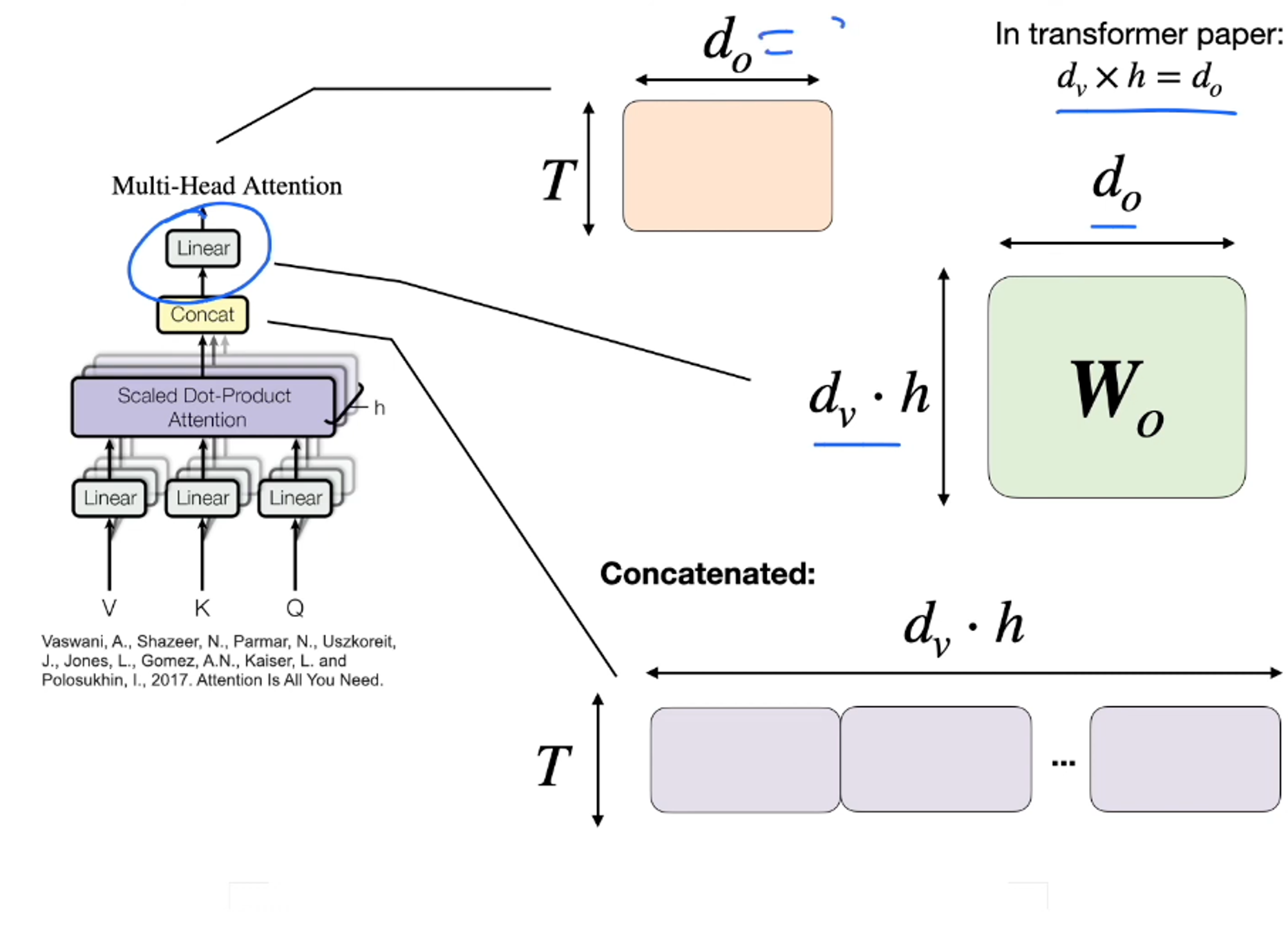
- 그다음, w0 행렬에 곱해서 linear하게 재정렬한다.
- 한마디로 맨위에서 wo랑 곱하는 과정이 concat
- concat를 해서 리니어하게 재정렬 된다는것을 의미한다.
- transformer paper에서 w0는 가로세로 길이가 같음 (d0=dv*h)
참조 : https://medium.com/analytics-vidhya/understanding-bert-architecture-3f35a264b187
위 링크에서 보면 keras_bert로 multihead attention이 끝나고 파라미터수가 Bert는 인코더수가 12개이기 때문에 encoder-1의 multihead self attnetion의 파라미터수가 2,362,368개가 나오는지 계산해보자
import keras
from keras_bert import get_base_dict, get_model, compile_model, gen_batch_inputs
model = get_model(
token_num=30000,
head_num=12,
transformer_num=12,
embed_dim=768,
feed_forward_dim=3072,
seq_len=500,
pos_num=512,
dropout_rate=0.05
)
model.summary()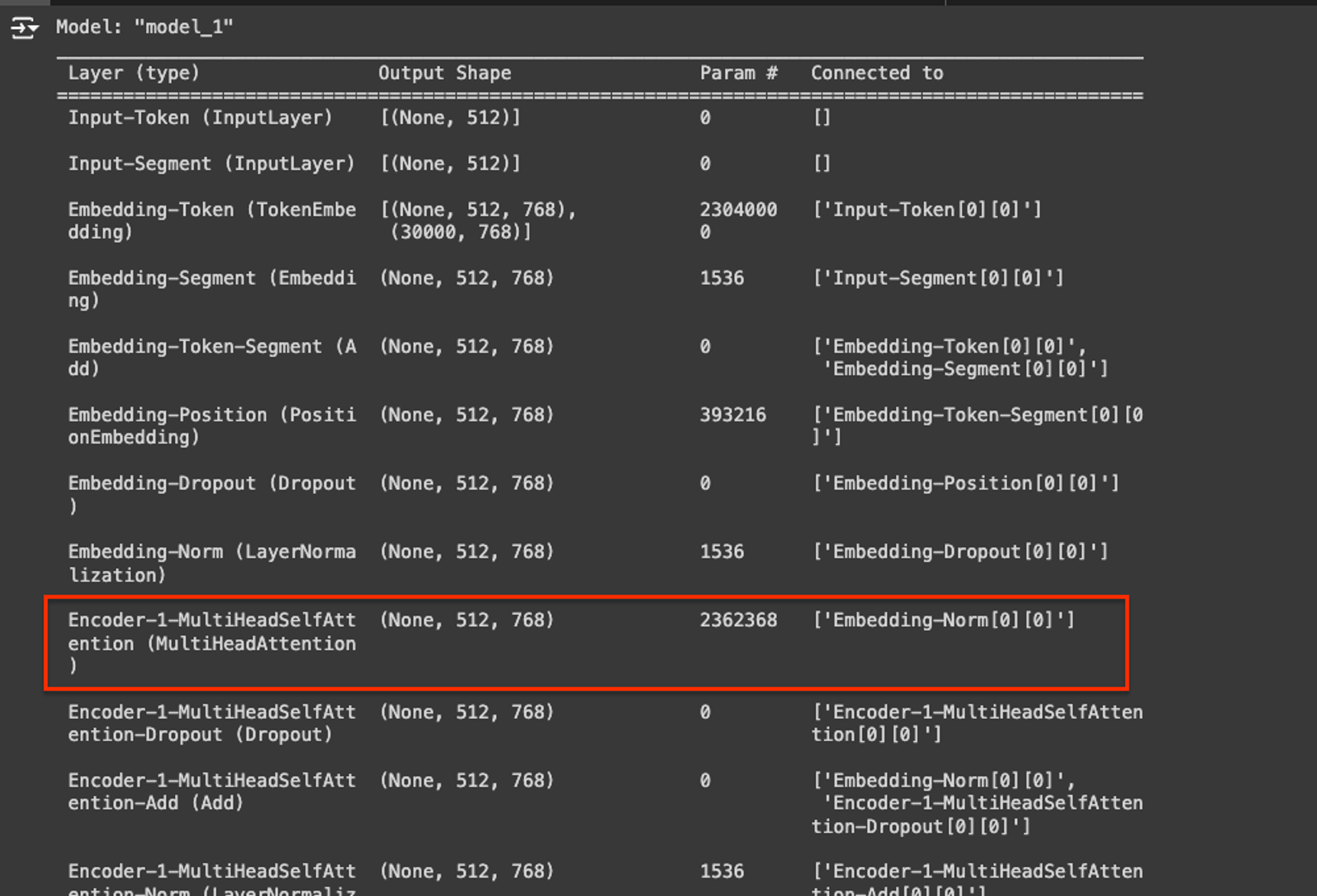
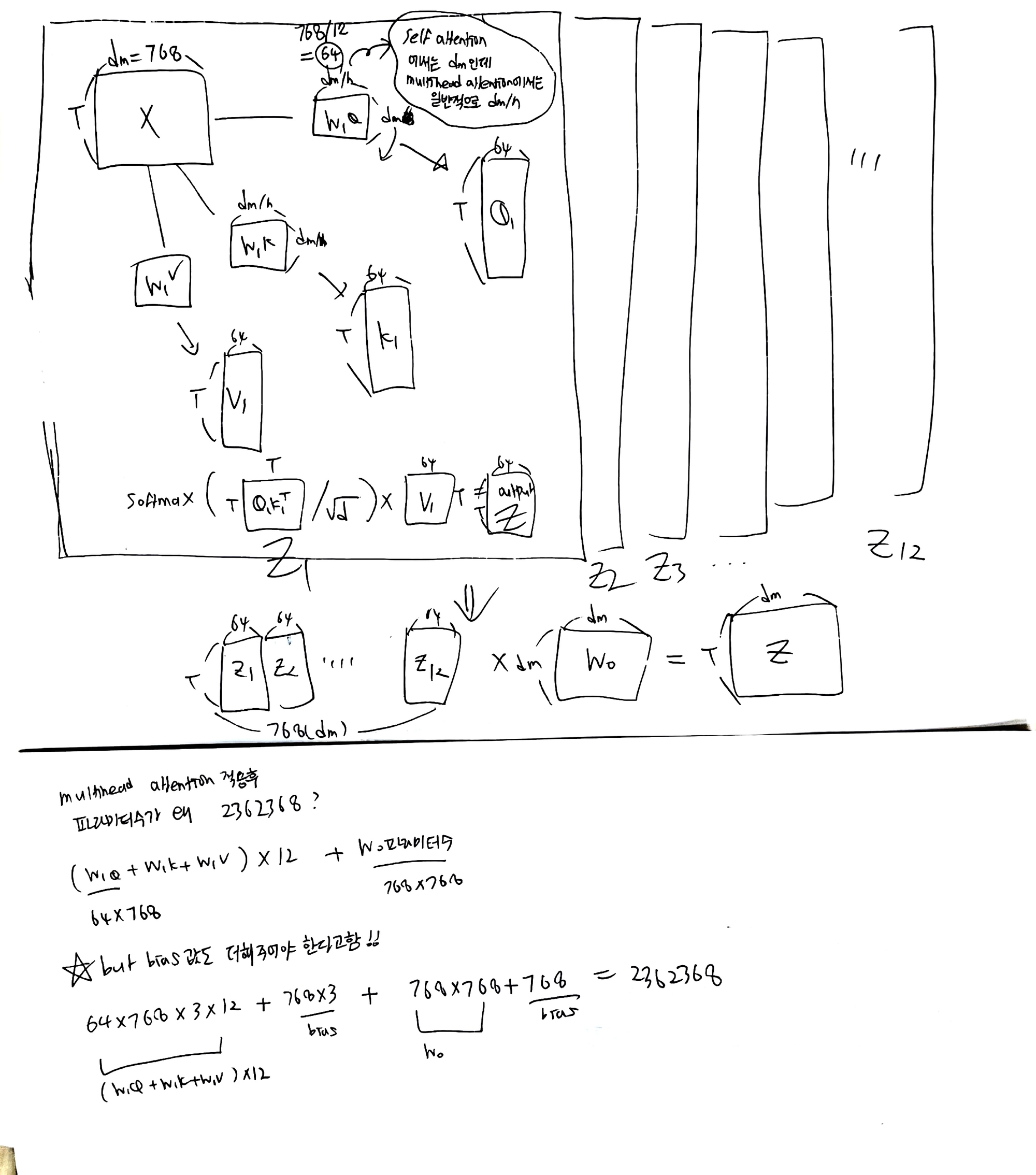
- parameter를 구하기위해서는 위에서 wq,wk,wv랑 w0의 수를 모두 더해주면된다.
- 일반적으로 self-attention에서는 w1q크기가 d_model x d_model이지만 여기서는 multihead attention이기 떄문에 d_model x d_model/h 로 구성되게 된다.
- 위의 예제에서 dm = 768, h=12로 지정해준 상태이다.
- 그렇다면 wq의 크기는 768*64 근데 이게 k,v,q 이렇게 3개가 있으니까 3을 곱해주고, 헤드가 12개니까 12도 곱해준다.
- 그런데 바이어스도 더해줘야한다고함..
- 그렇다면 wq,wv,wk의 모든 파라미터갯수는 76864312+7683
- w0은 쉽다. d_model x d_model인데 여기도 바이어스값을 더해줘야한다고
- 그래서 768*768 + 768
- 모두다 더해주면 2362368개의 파라미터수가 나온다!
3. Layer Norm
- 그림에서는 norm이 multihead 다음, 피드 포워드 다음에 진행되지만 최근 LLM모델들은 전부 norm을 먼저 진행한다고 한다 (최근은 순서가 반대라고함)
- 실제로 아래 BERT모델을 보면 Layer norm을 먼저하고나서 multihead attention을 진행한다.

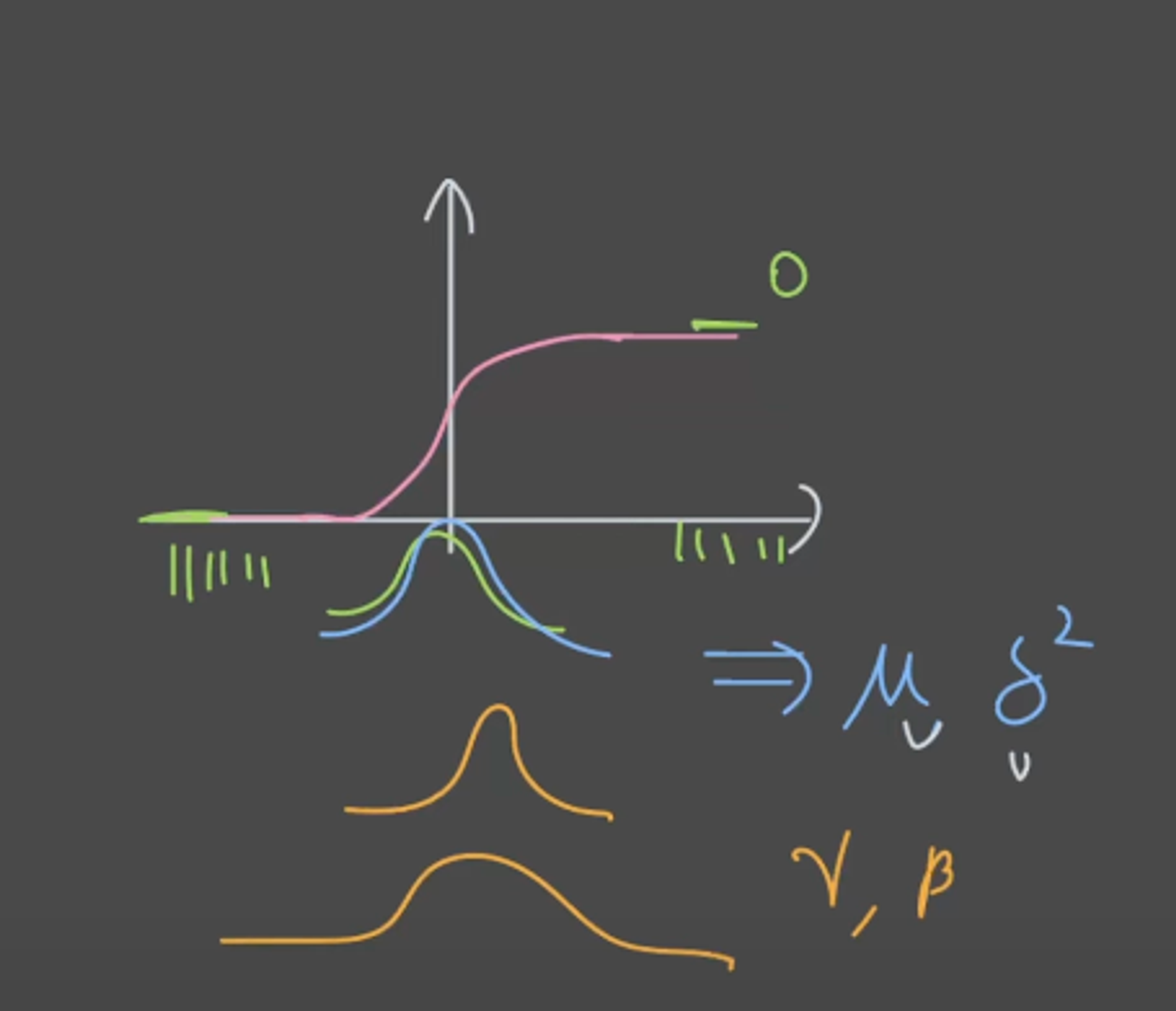
- 먼저 딥러닝을 진행할때 activation function에서 input데이터들이 너무 왼쪽이나 너무 오른쪽에 붙으면 문제가 생김
- 그걸 방지하고자 nomarlization을 진행, 이때 정규화분포의 모양과 위치는 감마와 베타가 결정함.
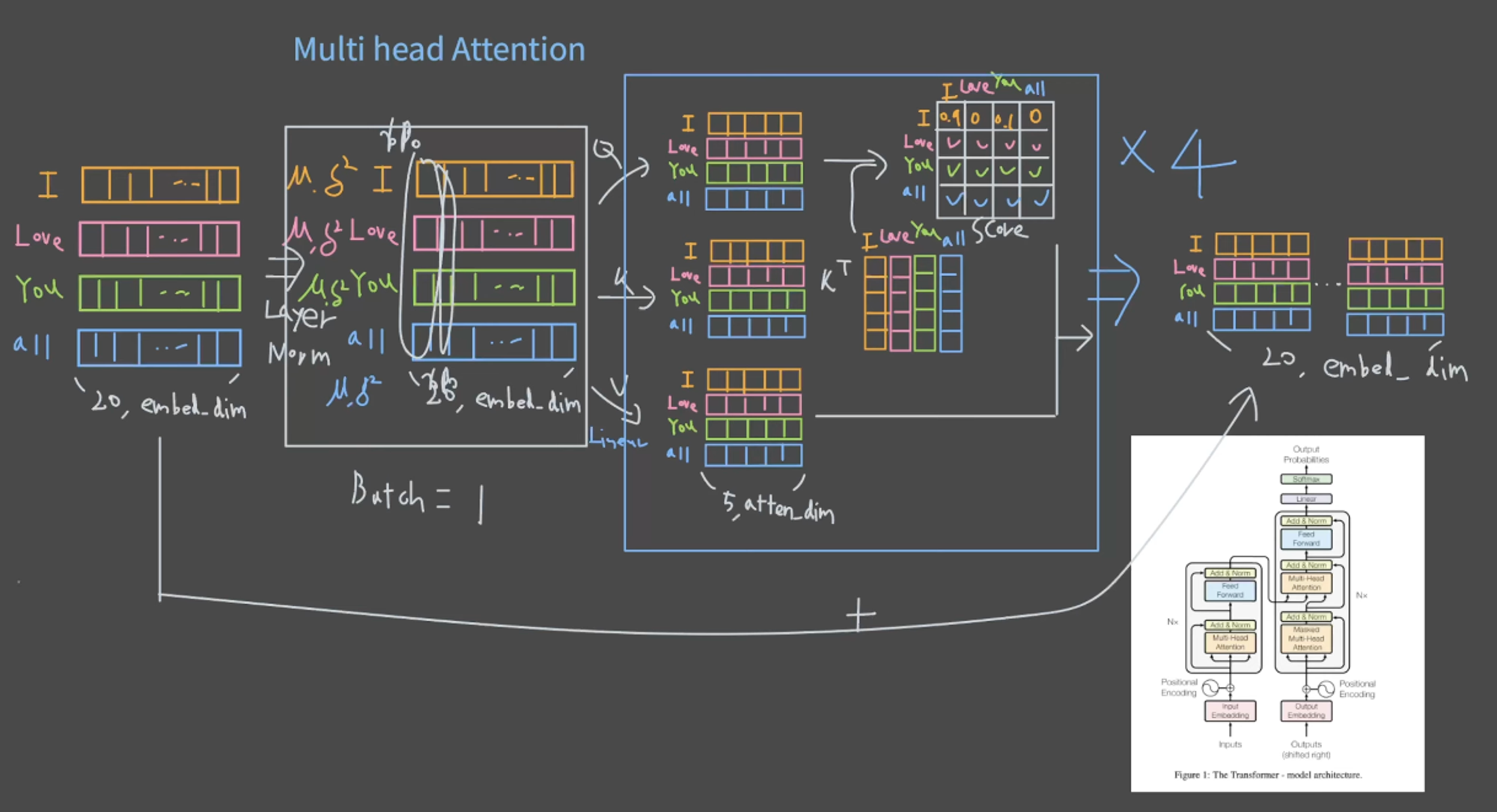
- Multihead attention을 적용하기 전에 normalization을 적용
- 세로 한줄 한줄씩 정규화하여 감마와 베타값도 구함.
- 이렇게 정규화한 값들을 가지고 멀티헤드 어텐션을 구함
- 원본과 멀티헤드 어텐션으로 나온값을 더해준다.
4. Feed Forward
참조 (아래 더보기 클릭)
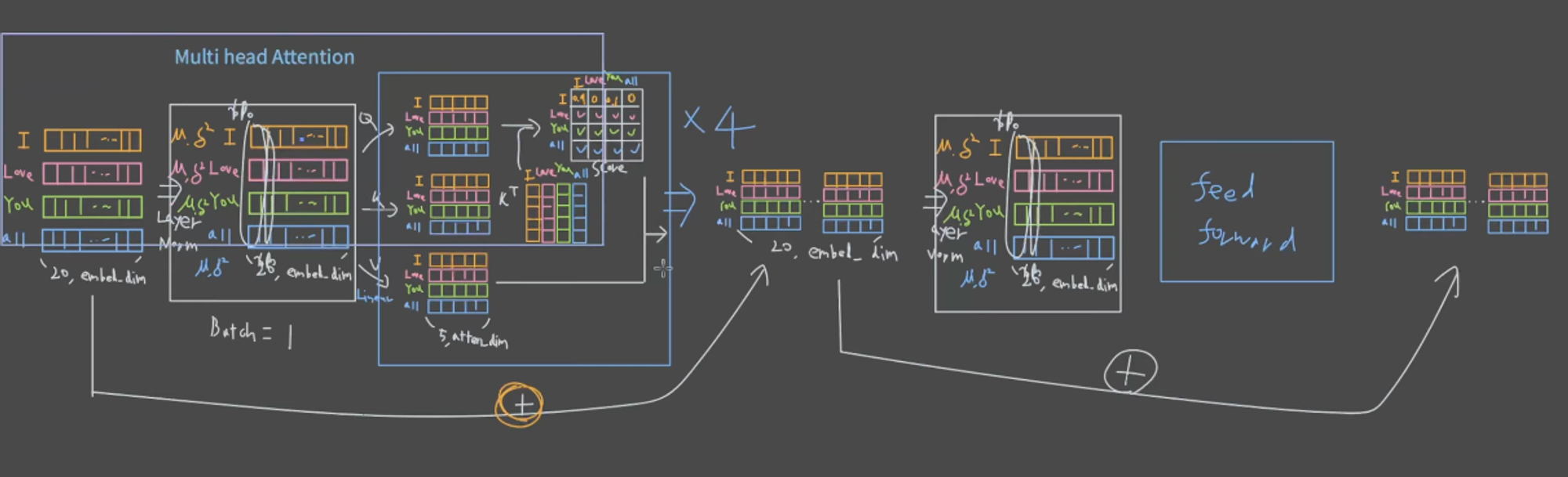
여기까지 싹하고나면, 아래 그림은 인코더 부분을 정리해서 나타낸 그림.

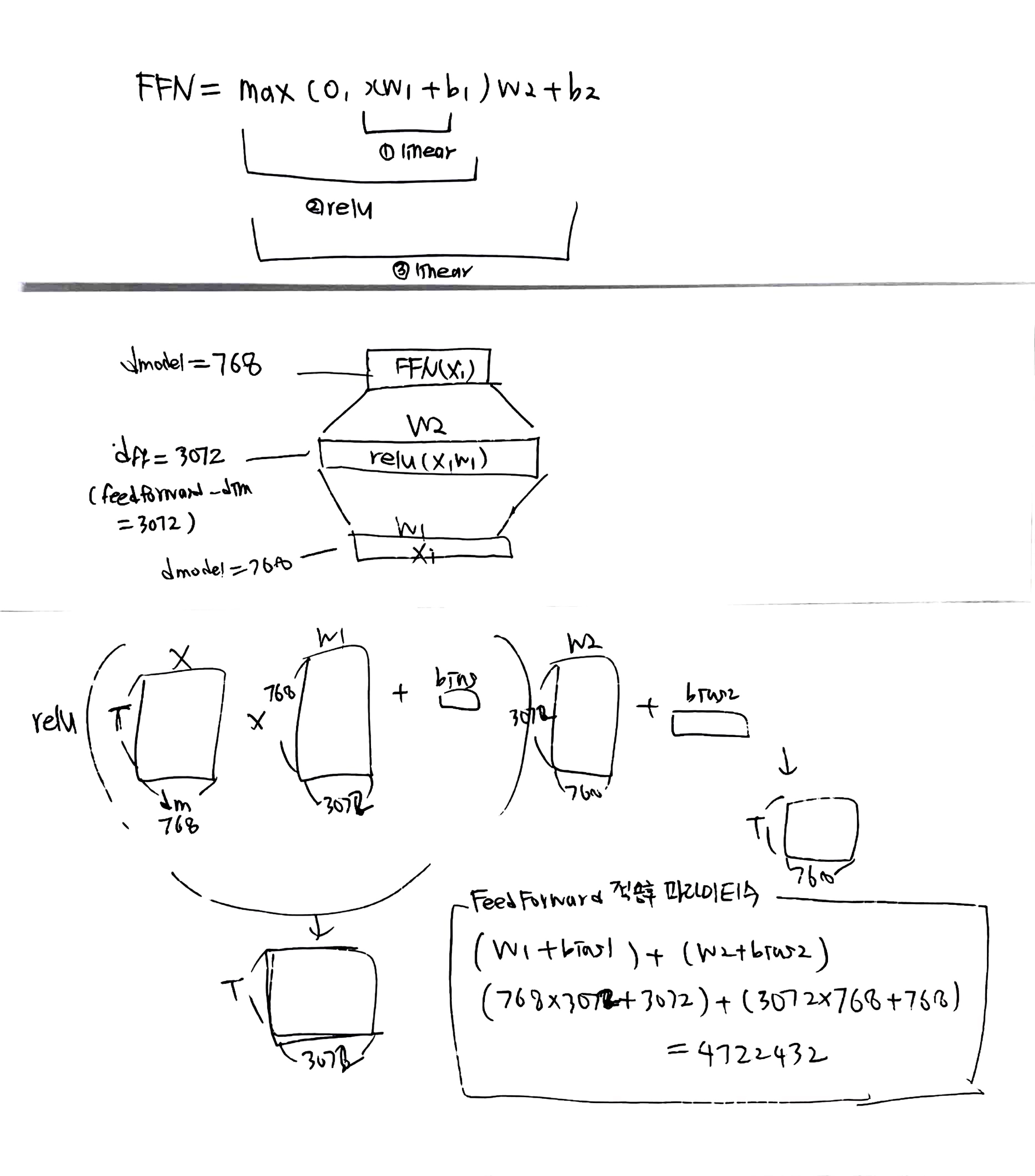
이것도 파라미터수가 feed forward후에 왜 4722432개 나오는 이유를 보자
'<개념> > Deep learning' 카테고리의 다른 글
| What is Agent Force? (0) | 2024.11.03 |
|---|---|
| LLAMA Inference (0) | 2024.05.17 |
| T5 inference in inferentia (0) | 2024.04.08 |
| openai gpt3 inference in inferentia2(neruon) (0) | 2024.03.28 |
| GPT2 Text-generation을 AWS환경의 GPU/CPU/Inf2/Trn1에서.. (1) | 2024.01.29 |