<string 유사도 구하기 알고리즘3가지 적용>
1. LCS알고리즘 (=최장공통부분 문자열)
=Longest Common Subsequence
(substring은 연속된 부분 문자열, subsequence는 연속적이지 않은 부분 문자열 - 핵심!)
두개 s1,s2가 주어졌을때, 공통으로 들어있는 부분열중 가장긴 열의 길이를 찾아낸다. (여기서 부분열이란? 몇몇 문자가 빠져도 순서는 바뀌지않는 문자열을 의미
def lcs(a, b):
prev = [0]*len(a)
for i,r in enumerate(a):
current = []
for j,c in enumerate(b):
if r==c:
e = prev[j-1]+1 if i* j > 0 else 1
else:
e = max(prev[j] if i > 0 else 0, current[-1] if j > 0 else 0)
current.append(e)
prev = current
return current[-1]

2. 레벤슈타인 알고리즘(=편집거리 알고리즘)
→ 위에 LCS랑 거의 비슷한데 약간의 디테일만 다르다!!!!!!
두 문자열이 같아지려면, 몇번의 문자조작(삽입,삭제,변경)이 필요한지 구하는것 ( 위의 3개를 합치면 총 조작비용이 나온다)
#레반슈타인 알고리즘 ( 편집거리 알고리즘 )
import numpy as np
def levenshtein(seq1, seq2):
size_x = len(seq1) + 1 #왜냐면 matrix에 넣어줄때, 제일 왼쪽에 0이 붙으니까~~
size_y = len(seq2) + 1
matrix = np.zeros ((size_x, size_y)) # matrix를 0으로 초기화함
for x in range(size_x):
matrix [x, 0] = x
for y in range(size_y):
matrix [0, y] = y
# 참조링크 들어가보면 matrix 북서쪽에 0,1,2,... 이런식으로 숫자 채워줌
# matrix 북서쪽 채워주고 나머지는 전부 0
# 북서쪽이 뭐냐! 앞에서 len()+1로 더해준 0이랑 조작비용을 계산하는거라 0,1,2,3....이렇게 채워진다.
# 여기서부터 나머지 matrix값들 채워줌
for x in range(1, size_x): #북서쪽 앞에서 채워준거 제외해줘야하니까 1부터 시작~
for y in range(1, size_y): #for, for로 비교
if seq1[x-1] == seq2[y-1]: # seq[]이랑 matrix[]이거랑 따로!!! 그려서 넣어보면 바로이해감
matrix [x,y] = min(
matrix[x-1, y] + 1,#문자삽입
matrix[x-1, y-1], #문자제거
matrix[x, y-1] + 1 #문자변경
)
else:
matrix [x,y] = min( #둘이 안같으면 그냥 전값에 1더해주기
matrix[x-1,y] + 1,
matrix[x-1,y-1] + 1,
matrix[x,y-1] + 1
)
#print (matrix)
return (matrix[size_x - 1, size_y - 1]) # matrix에서 제일 오른쪽아래값을 출력해줌 
3. n-gram
n개의 연속적인 단어나열 / n개의 단어뭉치단위로 끊어서 이것을 하나의 토큰으로 간주.
위에 두개는 subsequence로 연속적이지 않는 부분 문자열을 살폈지만, 이건 연속적인것으로 판단함
그러니까 2-gram이라고 하면, 두개씩 찢어서 찢어놓은 리스트에서 같은것이 몇개인가를 확률로 나타낸것.
#n-gram
def ngram(s, num): #
res = []
slen = len(s) - num + 1 # num개로 찢으면 몇개나오나 연산
for i in range(slen):
ss = s[i:i+num] #찢어준다!
res.append(ss) #res안에 조각조각낸거 넣어줌
return res
def diff_ngram(sa, sb, num): #sa,sb가 비교할 string, num은 몇개로 찢을거냐
a = ngram(sa, num) #sa를 num으로 찢은게 a
b = ngram(sb, num) #sb를 num으로 찢은게 b
r = []
cnt = 0
for i in a: #찢어준 리스트중에 머가 곂치는지 하나하나 비교해줌
for j in b:
if i == j:
cnt += 1
r.append(i)
return cnt / len(a)#곂치는 조각들을 모아서 리스트로 만들어줌
#return cnt / len(a), r # cnt을 리스트개수로 나눠서 출력/ r
4. 그외 문자열 유사도 구하는 다른 방법들... Hamming Distance / Smith-Waterman / Sørensen–Dice coefficient ......
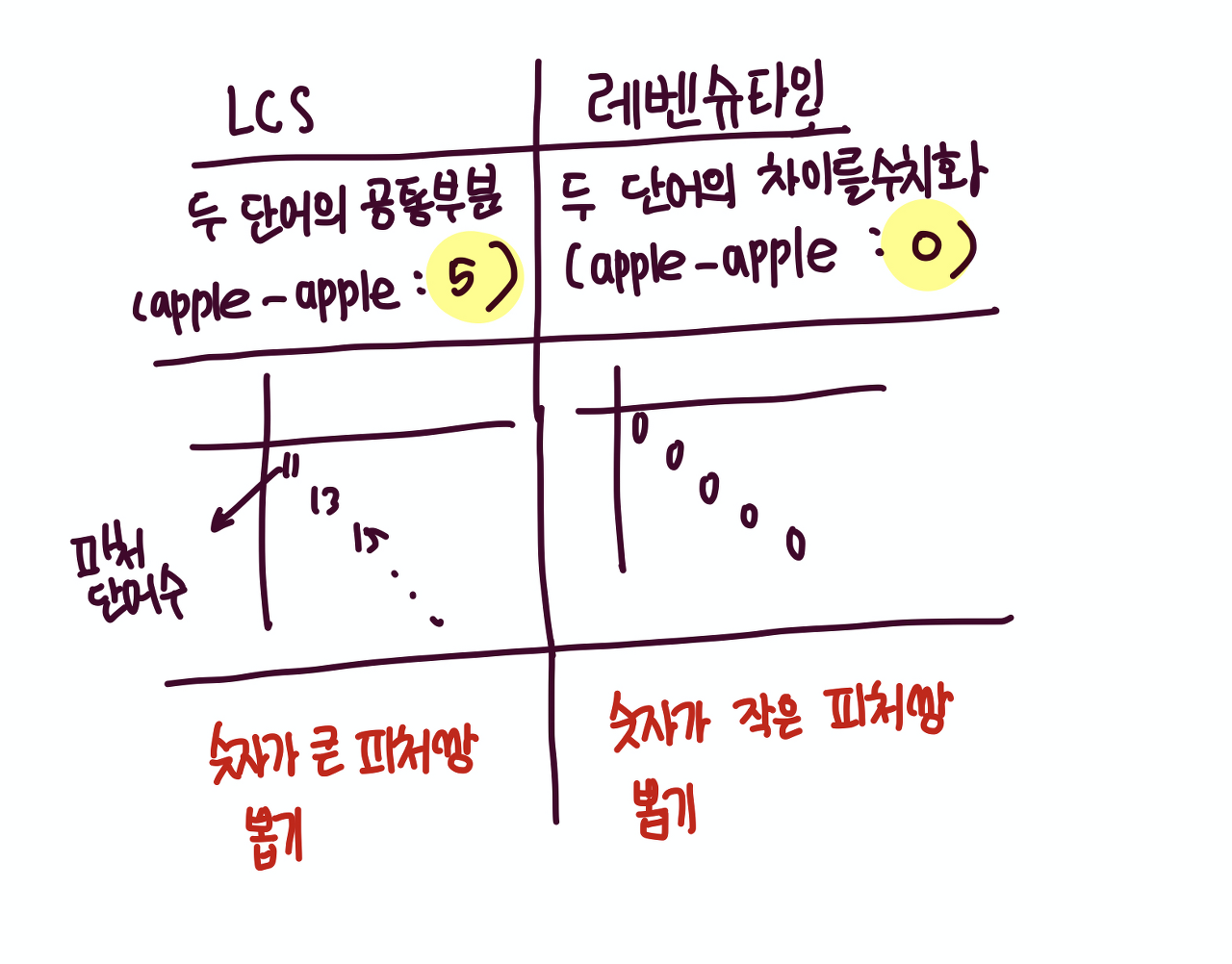
- Lcs랑 레벤슈타인 피처들간의 연관도를 표로 만들었을때 차이점 (헷갈리지말기)
-> 연관도 있는 피처쌍을 뽑을때, lcs는 숫자가 큰것들을 필러팅 / 레벤슈타인은 숫자가 작은것들을 필터링해야한다
'<개념> > 기타' 카테고리의 다른 글
| SHIFT 개념 이해하기 예제 with SIN/COS/TAN (0) | 2021.12.30 |
|---|---|
| 자주나오는 이산수학관련 내용 (0) | 2021.11.28 |
| RestfulAPI 개념정리 (0) | 2021.08.14 |
| AJAX,JSON 개념메모 (0) | 2021.08.14 |
| 도커 초간단 개념정리 (0) | 2021.05.09 |