- aws configure 설정은 기본으로 되어있다는 가정하에 시작
아래 코드를 받아서 실행해보기
LAUNCH_INFO=$(aws ec2 run-instances
--image-id $IMAGE_ID
--count 1
--instance-type $INSTANCE_TYPE \\
--key-name $AWS_KEY
--subnet-id $SUBNET_ID
--security-group-ids $SG_ID)
INSTANCE_ID=$(echo $LAUNCH_INFO | jq -r '. | .Instances[0].InstanceId')
INSTANCE_DNS=$(aws ec2 describe-instances --instance-ids $INSTANCE_ID | jq -r '. | .Reservations[0].Instances[0].PublicDnsName')
image id
1. cli 명령어로 찾는 방법
aws ec2 describe-images --filters 'Name=description,Values=*Deep Learning Base AMI*' --query 'Images[*].[ImageId,Description]' --output table
2. 검색해서 찾기
https://aws.amazon.com/marketplace 여기서 검색해서 찾으면됨
( 찾는 방법은 https://brunch.co.kr/@topasvga/872 여기보면 자세히 나와있음)
** 주의할점 : region 마다 ami-12345 이름이 다르다고 한다.
us-west-2 의 이름을 다시한번 검색해보기
aws ec2 describe-images --image-ids ami-048d4939678169ad1 --region us-west-2
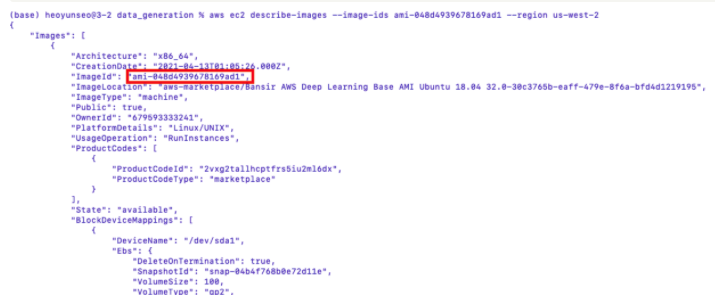
ㄴ 결과동일함
key-name
- 새로운 키를 만들어주고 시작
키페어 만들기
# aws ec2 create-key-pair --key-name ys-oregon
aws ec2 create-key-pair --key-name ys-oregon2 --query 'KeyMaterial' --output text > ys-oregon2.pem
chmod 400 ys-oregon2.pem

실행 과정에서 생긴 에러들
실행시 에러 발생)
An error occurred (OptInRequired) when calling the RunInstances operation: In order to use this AWS Marketplace product you need to accept terms and subscribe. To do so please visit https://aws.amazon.com/marketplace/pp?sku=2vxg2tallhcptfrs5iu2ml6dx
⇒ 다른 인스턴스로 변경하고나서 해결
( 아니면 마켓 플레이스에서 subscribe 하고 사용하면 됨)
실행시 에러 발생)
인스턴스 생성후 인스턴스 접속시에 문제발생
Warning: Identity file ys-oregon not accessible: No such file or directory.
경로에 한글이 들어있어서 그렇다고한다.
(x) 시도1 )
파일내에서 여기저기 위치를 변경해주어도 파일경로를 살펴보니 /Users/사용자/FIle/.. 이렇게 파일이름이 한글인것이 문제인듯하여 ⇒ 그냥 노트북을 한글 → 영어로 세팅 변경
(x) 시도2 ) 파일 이름을 변경해봄
- 주소/abc.pem
- 주소/abd
- abc
- abc.pem....
(x) 시도 3) chmod 400 ys-oregon.pem
chmod 400 ./ys-oregon.pem
chmod 400 /Users/heoyunseo/desktop/aws_pem/ys-oregon.pem
(x) 시도 4) aws ec2 create-key-pair --key-name ys-oregon2 --query 'KeyMaterial' --output text > ys-oregon2.pem 로 키페어 다시만들기
(0) 시도5) 인스턴스 생성할떄는 --key-name ys-oregon2 / 인스턴스에 접속할때는 ys-oregon2.pem 으로 접속
ㅠㅠㅠㅠ SSH 접속할때 ys-oregon2.pem 이 아니라 ys-oregon 으로 적용해줘서 에러가 났던것... 멍청....
실행시 에러 발생)
ssh: connect to host ec2-34-217-124-46.us-west-2.compute.amazonaws.com port 22: Operation timed out
⇒ 보안그룹의 인바운드규칙 에 모든 트래픽을 추가해주었더니 해결
INSTANCE_ID=$(echo $LAUNCH_INFO | jq -r '. | .Instances[0].InstanceId')
INSTANCE_DNS=$(aws ec2 describe-instances --instance-ids $INSTANCE_ID | jq -r '. | .Reservations[0].Instances[0].PublicDnsName')
이 부분에 대한 이해
- echo $LAUNCH_INFO 로 인스턴스 시작
- 실행한 결과를 jq 에 전달 ( 버티컬바는 왼쪽의 결과를 오른쪽에 넘겨준다는 의미)
$ echo '{"a": {"b": {"c": "d"}}}' | jq '.a | .b | .c'
"d"
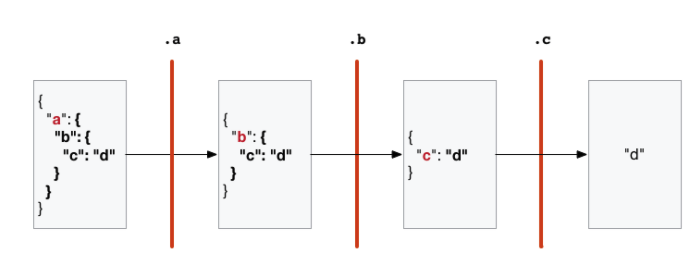
- INSTANCE_ID 는 INSTANCE_DNS를 구하기위해 사용
- INSTANCE_DNS 는 ssh 연결을 위해 구해줌
참조 : https://brunch.co.kr/@topasvga/872
https://www.44bits.io/ko/post/cli_json_processor_jq_basic_syntax
'<Cloud> > AWS' 카테고리의 다른 글
| EC2 VPC 올인원 한방에 생성하기 + 개념정리 (0) | 2022.05.18 |
|---|---|
| AWS g5.xlarge , p4d.24xlarge CUDA 호환성 (CUDA11.4, CUDA11이상) (0) | 2022.01.30 |
| EC2 Ubuntu 안의 파일째 모두 로컬에 옮겨 저장하기 (맥북/윈도우) (0) | 2021.11.28 |
| AWS CLI EC2 어떤식으로 구성되어있는지 보기 (0) | 2021.11.28 |
| AWS CLI lambda 간단정리 (0) | 2021.08.31 |



















Uploaded by Notion2Tistory v1.1.0