




GPU register,global,shared,local,constant,texture 메모리 정의구분 및 계층구조 + gpu구조




온칩 : (=레지스터 메모리)
- 온칩메모리는 GPU 칩 안에 있는 메모리로, 레지스터 메모리 / 로컬 메모리 라고 부릅니다.
- 레지스터는 GPU 커널 안에 선언되는 변수로, GPU 칩안에 있기 때문에 접근 속도가 빠릅니다.
- 레지스터 변수는 코어에 할당된 스레드가 분배해서 사용하는데, 커널 안에서 사용해야 할 변수가 많아지면 로컬 메모리에 레지스터 변수를 할당할 수 있습니다.
- 온칩은 속도가 빠른 대신에 비용 등의 이유로 인해 메모리 사이즈가 비교적 작습니다.
- 직접 연산수행하는 제일빠른 메모리 (싸인,코싸인 함수계산도 레지스터메모리사용함)
오프칩 : (=글로벌 메모리)
- 그래픽 카드에 장착한 DRAM으로
- CUDA에서는 이 off칩을 글로벌 메모리 / 디바이스 메모리라고 합니다.
- 메모리를 할당 및 해제하는 방법은 GPU 포인터를 선언 -> cudaMalloc 명령으로 메모리 할당해주기 -> 메모리 해제(cudaFree)
- 계산에 필요한 입력 데이터는 GPU가 아닌 CPU 메모리 영역에 있기 때문에 PCI-e 인터페이스를 통해서 GPU로 메모리를 전송합니다.
- 속도는 공유메모리랑 레지스터에 비하면 느린편이지만 cpu 메모리에 비교하면 상당히 빠른편
Shared Memeroy
- 글로벌 메모리(오프 칩)는 칩 안에 있지 않기 때문에 접근 시간이 많이 걸립니다. 그래서 GPU에서도 CPU처럼 캐시 기능을 사용할 수 있습니다.다른 점은 개발자가 캐시를 직접 제어할 수 있다는 점입니다.
- 블록 안의 스레드는 shared 메모리를 모두 공유합니다. (큰 메모리 개념)
- 블록은 블록마다 자신의 shared 메모리를 가집니다.
- shared 메모리는 항상 __syncthreads() 함수를 사용해야 합니다. 왜냐면 shared는 global의 데이터를 캐시처럼 shared에 올린 뒤 사용해야 하는데, 각각의 스레드가 shared에 올리는 작업을 수행합니다.이 때 sync를 걸지 않으면, 모두 메모리에 올라오지 않은 상태에서 값을 참조하여 쓰레기값을 가져올수 있기 때문입니다.
Texture Memory
- 3d 그래픽에서 사용하는 메모리
- read only memory
로컬 메모리
로컬메모리도 온칩메모리.보통은 커널내에 레지스터에 저장되지만 레지스터 공간에 맞지않는 변수는 로컬메모리에 저장된다고함. 아래같은것들은 컴파일러가 로컬메모리에 위치시키는 변수들이라고함.
- Local arrays referenced with indices whose values cannot be determined at compile-time
- Large local structures or arrays that would consume too much register space
- Any variable that does not fit within the kernel register limit
Constant memory
- 상수 메모리는 device 메모리에 위치하며 각 SM 의 컨스턴트 캐시에 캐싱된다. (gpu그림에서 c캐시부분)
- 커널은 상수메모리를 읽을수만 있다.
- 상수메모리는 워프의 모든 스레드가 동일한 메모리를 읽을때 가장베스트하다고함. 한마디로 각각의 데이터에 대해 동일한 계산을 수행하기위해 동일한 계수를 사용하기 떄문.

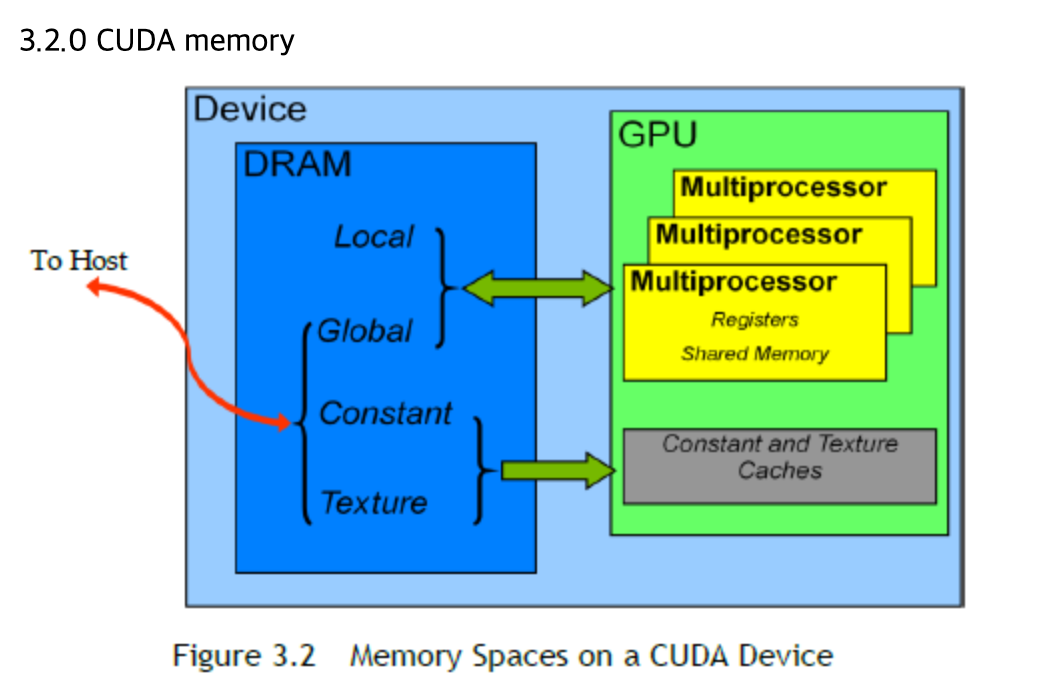

추가적으로 GPU 구조 관련해서도 간단히 정리

**커널 함수 : 병렬 함수 및 데이터 구조를 명시하는 키워드들을 확장한 형태로 작성된 코드로서, 디바이스가 실행하는 부분 (병렬 처리가 가능한 부분)
** 스레드 : 최소 명령어 처리단위 , 기본연산(Computation) 하나라를 스레드로 표현한다. (= 멀티프로세서 내에서 작동되는 코어하나에 할당된 명령어를 의미) / 커널함수의 한 인스턴스로써 gpu의 sp에 의해 실행
** 블럭 : 스레드 묶음 (=그리드내의 스레드들을 적절한수의 스레드들로 분할한 단위로 하나의 sm에게 할당한다)
** 그리드 : 블록이 모이면 그리드가 된다. (하나의 병렬 커널에 의해 실행되는 스레드 전체를 의미함)
+)TPC 는 fermi 이전에 있던것
** 멀티프로세서 : GPU를 구성하는 기본요소로 구성된 최소돤위, GPU 는 멀티프로세서내에 여러개의 GPU 코어를 지니고있다.
**GPU는 1개칩안에 최대 15개의 멀티프로세서를 가지고있음. 이 멀티프로세서안에 각각 192개의 코어 (계산유닛)을 가지고있다 그러므로 총 2880개의 코어를 가지고있는셈
** 커널 : GPU에서 병렬실행하는 명령의모음
**Wave(=Wavefront = WARP) : 32개 스레드들을 단위로 묶은것 (갯수는다를수있음), 대부분 엔비디아 gpu 는 32스레드를 1개워프로 치고있다고 한다.
Warp는 SM(Streaming Multi-processor)의 기본 실행 단위(unit of execution). 스레드 블록의 그리드를 실행하면, 그리드의 스레드 블록들은 SM들로 분배됩니다. 스레드 블록이 SM에 스케쥴링되면 스레드 블록의 스레드들은 warp로 파티셔닝됩니다. 32개의 연속된 스레드들로 구성된 하나의 warp는 SIMT(Single Instruction Multiple Thread) 방식으로 실행됩니다. 즉, 모든 스레드는 동일한 명령어를 실행하고, 각 스레드는 할당된 private data에 대해 작업을 수행합니다.



+) GPU DEVICE 에는 4가지 타입의 캐시가 존재
각 SM에는 하나의 L1 캐시가 있고, 모든 SM에서 공유되는 하나의 L2 캐시가 있는데(그림참). L1과 L2 캐시는 모두 local / global 메모리에 데이터를 저장하는데 사용됨. GPU에서는 오직 메모리 load 동작만 캐싱될 수 있고 메모리 store 동작은 캐싱될 수 없다고함. SM 또한 read-only constant 캐시와 read-only texture 캐시가 있는데, 이는 device memory의 각각의 메모리 공간에서 읽기 성능을 향상되는데 사용된다.
- L1
- L2
- Read-only constant
- Read-only texture
'<하드웨어> > GPU' 카테고리의 다른 글
| Ubuntu18.04+cuda11.4+python3.7+tensorflow2.7.0+cuDNN8.2.4 설치 (0) | 2022.04.10 |
|---|---|
| DeviceQuery 결과 csv파일로 저장 (0) | 2022.03.21 |
| DeviceQuery 정리 (0) | 2022.03.15 |
| DeviceQuery 실행 (0) | 2022.03.03 |
| AMD GPU(g4ad,NNv4) 에서 GPU+Tensorflow 사용 실패 (클라우드 환경에서 지원X) (0) | 2022.01.26 |
