import os
import pandas as pd
import glob
import datetime
import matplotlib.pyplot as plt
import statsmodels.api as sm
import seaborn as sns
import statsmodels.api as sm
from scipy import stats
from sklearn.preprocessing import LabelEncoder
import numpy as np
#pd.options.display.float_format = '{:.10f}'.format #표 전체 다보이
# 안잘리게 설정
pd.set_option('display.max_row', 3000)
pd.set_option('display.max_columns', 1000)
breaks_rpt = []
for i in breaks:
breaks_rpt.append(Data_F.index[i-1])
#breaks_rpt = pd.to_datetime(breaks_rpt)
breaks_rpt
plt.plot(y, label='data')
print_legend = True
for i in breaks_rpt:
if print_legend:
plt.axvline(i, color='red',linestyle='dashed', label='breaks')
print_legend = False
else:
plt.axvline(i, color='red',linestyle='dashed')
plt.grid()
plt.legend()
plt.show()
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
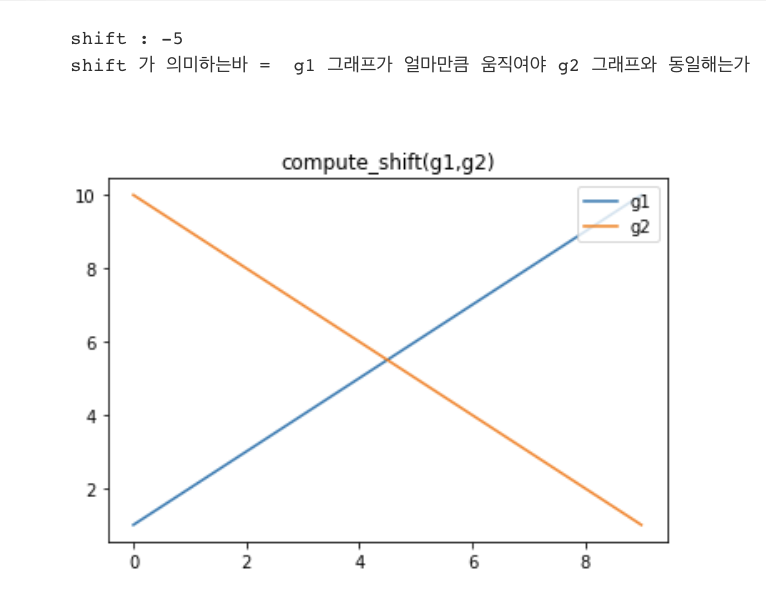
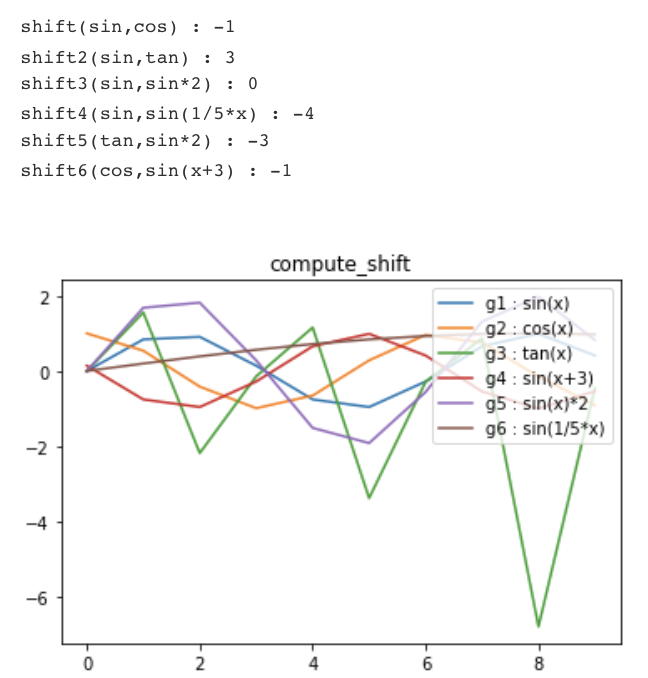
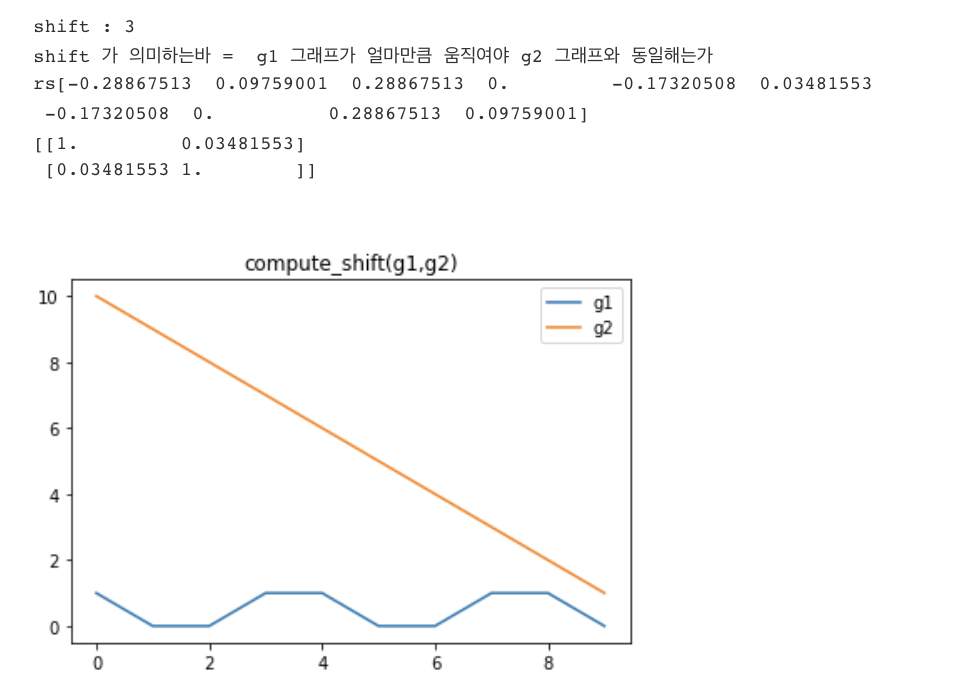
from synthetic_tests_lib import crosscorr, compute_shift
from scipy import signal
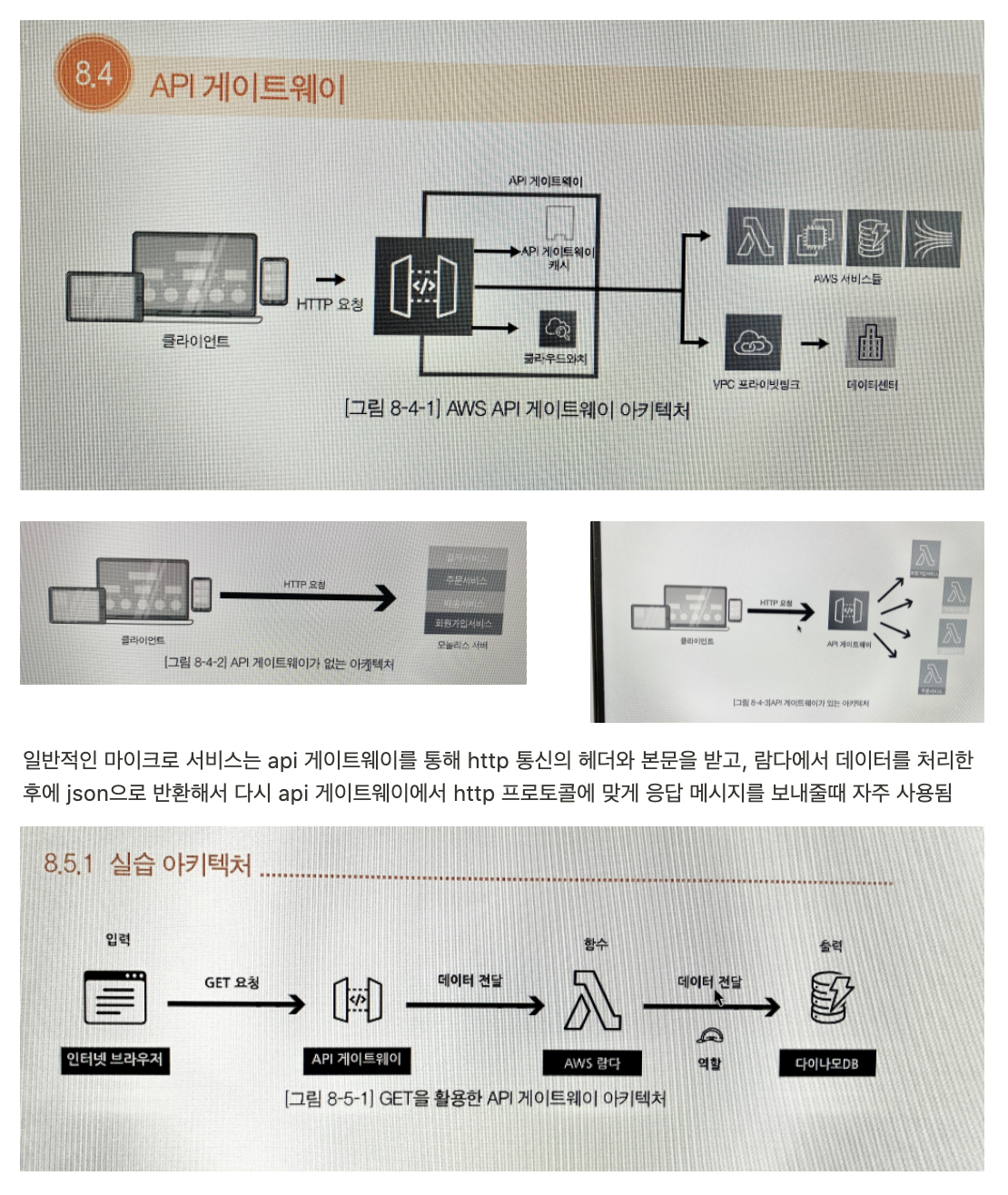
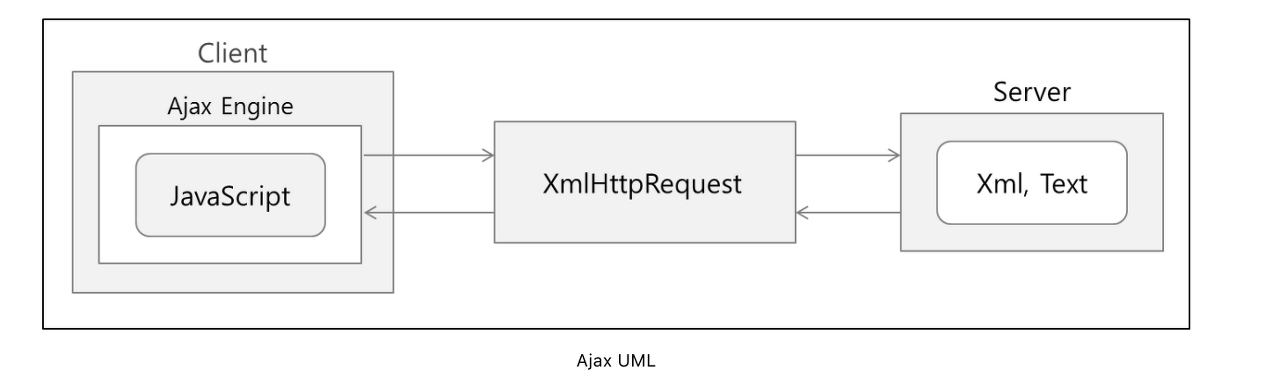
브라우저가 가지고있는 XMLHttpRequest 객체를 이용해서 전체 페이지를 새로 고치지 않고도 페이지의 일부만을 위한 데이터를 로드하는 기법 이며 JavaScript를 사용한 비동기 통신, 클라이언트와 서버간에 XML 데이터를 주고받는 기술이다. (https://velog.io/@surim014/AJAX란-무엇인가)
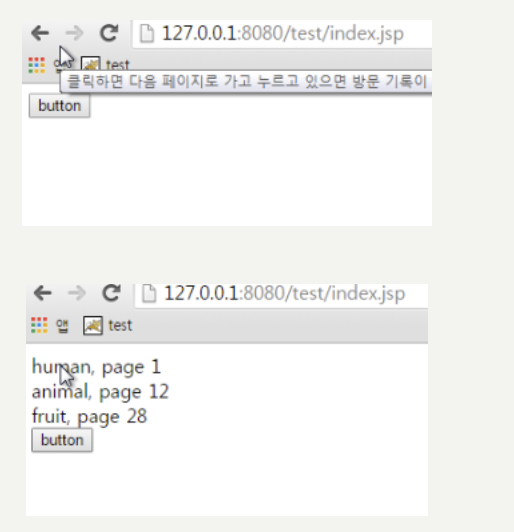
단순히 웹화면에서 무언갈 부르거나 데이터를 조회하고 싶을때 페이지전체를 새로고침하지않기위해 사용한다.
기본적으로 HTTP 프로토콜은 클라이언트쪽에서 Request를 보내고 서버쪽에서 Response를 받으면 이어졌던 연결이 끊기게 되어있다. 그래서 화면의 내용을 갱신하기 위해서는 다시 request를 하고 response를 하며 페이지 전체를 갱신하게 된다. 하지만 이렇게 할 경우, 엄청난 자원낭비와 시간낭비를 초래 → ajax를 사용
서버에서 데이터를 http get, post, json 의 모든방식으로 전송한후 서버측 응답을 받으럐때 사용, http get방식으로 전송한후 서버측 응답을 json형식으로 받을떄는 $get.JSON 을 사용한다.
var serverAddress = 'https://hacker-news.firebaseio.com/v0/topstories.json';
// jQuery의 .get 메소드 사용
$.ajax({
url: ,
type: 'GET',
success: function onData (data) {
console.log(data);
},
error: function onError (error) {
console.error(error);
}
});
<script>
$(document).ready(function() {
jQuery.ajax({
type:"GET",
url:"/test",
dataType:"JSON", // 옵션이므로 JSON으로 받을게 아니면 안써도 됨
success : function(data) {
// 통신이 성공적으로 이루어졌을 때 이 함수를 타게 된다.
// TODO
},
complete : function(data) {
// 통신이 실패했어도 완료가 되었을 때 이 함수를 타게 된다.
// TODO
},
error : function(xhr, status, error) {
alert("에러발생");
}
});
});
</script>
출처: https://marobiana.tistory.com/77 [Take Action]
전제조건 : 내가보고있는 페이지에서 다른페이지의 rest api를 호출해서 데이터를 json으로 가져오려고함. 내가 이용하는 페이지주소랑 데이터를 가지고 오기위한 서버 도메인이 서로 다를경우 crossdomain이라고 부름.
formData
비동기 업로드를 위해 ajax formData를 사용함. 평소엔 안쓰임 , 이미지를 ajax로 업로드할때 필요함.
*** 비동기?
비동기 처리 ? 특정 코드의 연산이 끝날떄까지 코드의 실행을 멈추지않고 다음코드를 먼저 실행하는 자바스크립트의 특성을 의미함. → 제이쿼리의 ajax를 많이씀.
function getData() {
var tableData;
$.get('https://domain.com/products/1', function(response) {
tableData = response;
});
return tableData;
}
console.log(getData()); // undefined
// get 부분이 ajax로 통신을 하는 부분임. http~ 에 get 요처응ㄹ 날려서 product정보를 요청함.
// 한마디로 쉽게 말하면 지정된 url에 데이터를 하나 보내주세요 라는 요청을 날리는것과 같음.
// http 서버에서 받아온 데이터를 respose 인자에 담김
// getdata는 뭐임?? undefined 왜? 왜냐 이전에 미리 return 해줘서 그럼. 기다려주지않고 바로
리턴해버려서 undefined를 출력하게됨.
// 이런식으로 특정로직의 실행이 끝날떄까지 기다려주지않고 나머지 코드를 먼저 실행해버리는게 비동기처리라는것임
콜백함수로 비동기처리 방식의 문제점 해결하기
function getData(callbackFunc) {
$.get('https://domain.com/products/1', function(response) {
callbackFunc(response); // 서버에서 받은 데이터 response를 callbackFunc() 함수에 넘겨줌
});
}
getData(function(tableData) {
console.log(tableData); // $.get()의 response 값이 tableData에 전달됨
});
mp4_cctv_list=[]
for i in file_list:
# 현재 디렉토리에 있는 모든 파일 리스트를 가져온다
path = "./task1/"+str(i)
file_listttt = os.listdir(path)
mp4_cctv = [file for file in file_listttt if file.endswith(".mp4")]
mp4_cctv_list.append(mp4_cctv)
for j in range(1,len(file_list)):
mp4_cctv = "./task1/"+str(file_list[j-1])+"/"+str(mp4_cctv_list[j-1][0])
try :
# -------------------- 동영상 쪼개기 ------------------------------------------------------------
import cv2
n=119 #동영상을 119개로 쪼개줄것임
vidcap = cv2.VideoCapture(mp4_cctv)
total_frames = vidcap.get(cv2.CAP_PROP_FRAME_COUNT)
frames_step = total_frames//n
for i in range(n):
#here, we set the parameter 1 which is the frame number to the frame (i*frames_step)
vidcap.set(1,i*frames_step)
success,image = vidcap.read()
#save your image
globals()['col{}.jpg'.format(i)]= image
#cv2.imwrite(globals()['./col{}.jpg'.format(i)],image)
# 저장해줄 위치 지정해줌
cv2.imwrite('./new2/col'+str(i)+'.jpg',image)
vidcap.release()
# -------------------- yolo ------------------------------------------------------------
# Yolo 로드
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
classes = []
with open("coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
colors = np.random.uniform(0, 255, size=(len(classes), 3))
for k in range(119): #수정 119로
# 이미지 가져오기
print('사진' ,k)
img = cv2.imread("./new2/col"+str(k)+".jpg")
img = cv2.resize(img, None, fx=0.4, fy=0.4)
height, width, channels = img.shape
# Detecting objects
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
# 정보를 화면에 표시
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
# Object detected
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# 좌표
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
font = cv2.FONT_HERSHEY_PLAIN
label_lists=[]
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = str(classes[class_ids[i]])
color = colors[i]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
cv2.putText(img, label, (x, y + 30), font, 3, color, 3)
label_lists.append(label)
cv2.imshow("Image", img)
cv2.waitKey(1)
cv2.destroyAllWindows()
print(label_lists)
df['mp4'][:][k]=label_lists
#맥에서 opencv 안닫힐때 꿀팁
cv2.destroyAllWindows()
cv2.waitKey(1)
cv2.waitKey(1)
cv2.waitKey(1)
cv2.waitKey(1)
except :
print('exept',file_list[j-1],j-1)
Xi = np.array([[0,17,21,31,23],[17,0,30,34,21],[21,30,0,28,39],[31,34,28,0,43],[23,21,39,43,0]]) dists = squareform(Xi) #여기서 flat하게 바꾸어 주어야한다.이거 안해주고 넣으면 어딘가 이상해짐 Z = linkage(dists, method='single') # method는 여기서 변경해주면 된다 dendrogram(Z) # 아래 그래프 출력 plt.axhline(20, color='k', ls='--'); #임계치값(20)에 대해 점점이 가로줄을 그어줌
shc.fcluster(Z, 20, criterion='distance') #임계치20에 줄을 그어서 나누어지는 군집들
→ [a,b][c][d][e] 이렇게 나누어짐을 확인할수 있습니다.
<개념부분>
첫번째줄에서, 임계값을 주지않으면, 총 1개의 군집이 출력됩니다. (method별로 만들어지는 dendrogram 모양이다릅니다)
두번쨰 줄에서 임계값을 줌으로써 여러개의 군집으로 나누어줄수 있습니다.
이것은 method 별로 유사도를 처리하는 방법이 다른것을 자세히 나타내 줍니다.
(single 은 가장 가까운 거리를 채택, complete 는 가장 먼거리를 채택, average는 이 두개의 평균을 채택합니다.)
e.g. single linkage 방법에서 abce, d 사이의 거리를 구할때, d와 ab간의 거리 31, d와 c간의 거리 28, d와 e간의 거리 43중에 가장 작은값인 28을 선택해줍니다. 만약 complete linkage 방법이였다면, 43을 선택해주었을것입니다.
(centroid , ward 이 두가지 메소드는 계산과정에서 (x,y)축을 필요로 하기 때문에 x,y축에서 pdist로 유사도를 구하는 방식이 아니라 처음부터 유사도를 집어넣어서 계산하는 방법에는 바람직하지 않음

































Uploaded by Notion2Tistory v1.1.0