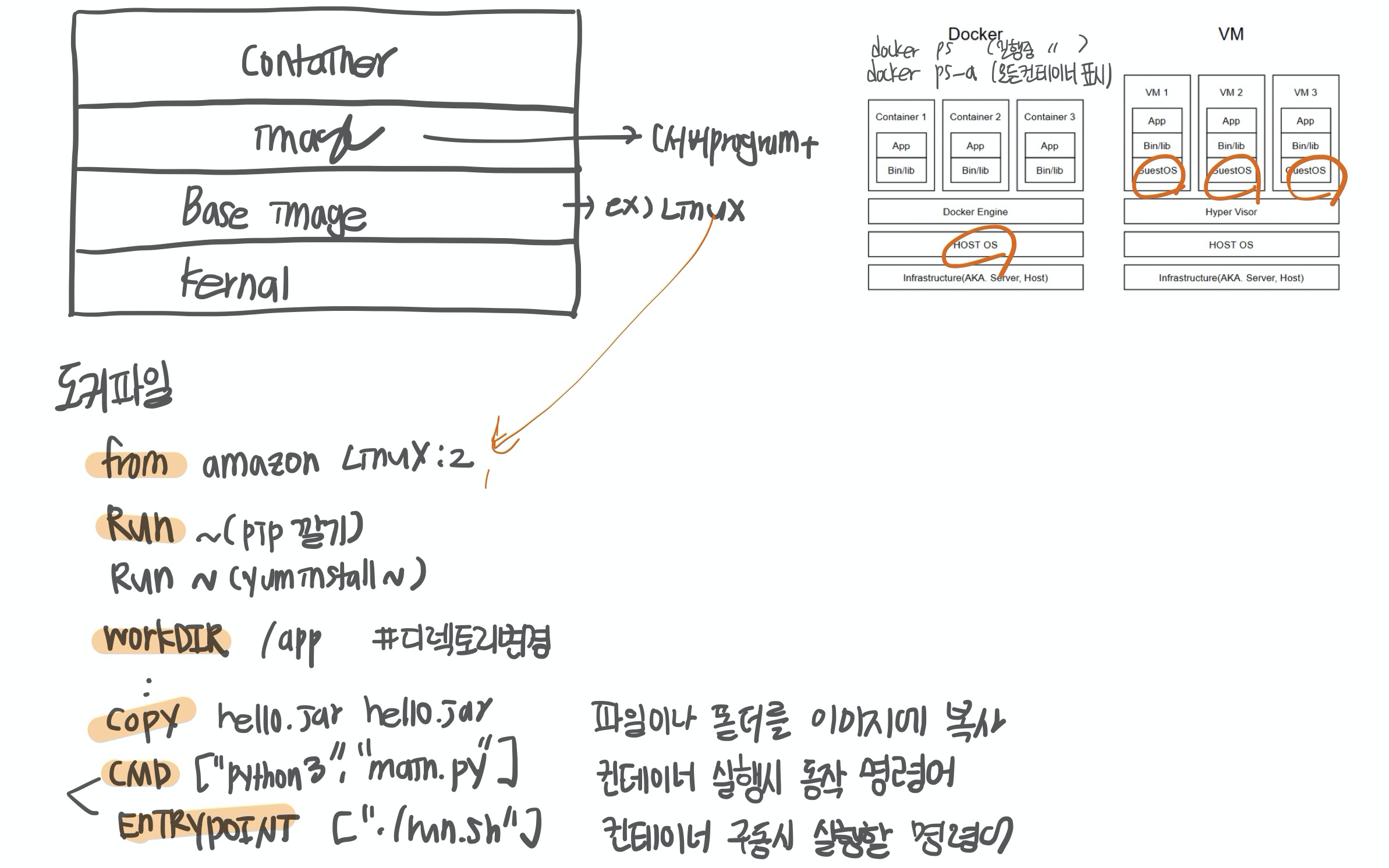
# python3.8 lambda base image
FROM public.ecr.aws/lambda/python:3.8
# copy requirements.txt to container
# 설치할 패키지들을 requirements.txt 에 기재
COPY requirements.txt ./
# installing dependencies
RUN pip3 install --upgrade --ignore-installed pip setuptools
RUN pip3 install -r requirements.txt
RUN yum install git -y
# Copy function code to container
COPY feature_info.py ./ # host 에서 Container 로 file copy
COPY app.py ./ # host 에서 Container 로 file copy
RUN git clone https://github.com/ ~~~ # 사용할 파일들 불러오기
# setting the CMD to your handler file_name.function_name
CMD [ "app.lambda_handler" ] # app.py 에서 handler 함수를 시작하도록 세팅
CMD ? ENTRYPOINT? → 컨테이너 실행시 동작 명령어 (전자) , 컨테이너 구동시 실행할 명령어 (후자)
ARG?
ARG 명령어 는 빌드 시 전달할 수 있는 변수를 정의합니다 . Dockerfile에 정의되면 이미지를 빌드하는 동안 --build-arg 플래그로 전달할 수 있습니다. Dockerfile에 여러 ARG 명령어가 있을 수 있습니다. ARG는 Dockerfile에서 FROM 명령어 앞에 올 수 있는 유일한 명령어입니다.2019. 9. 16.
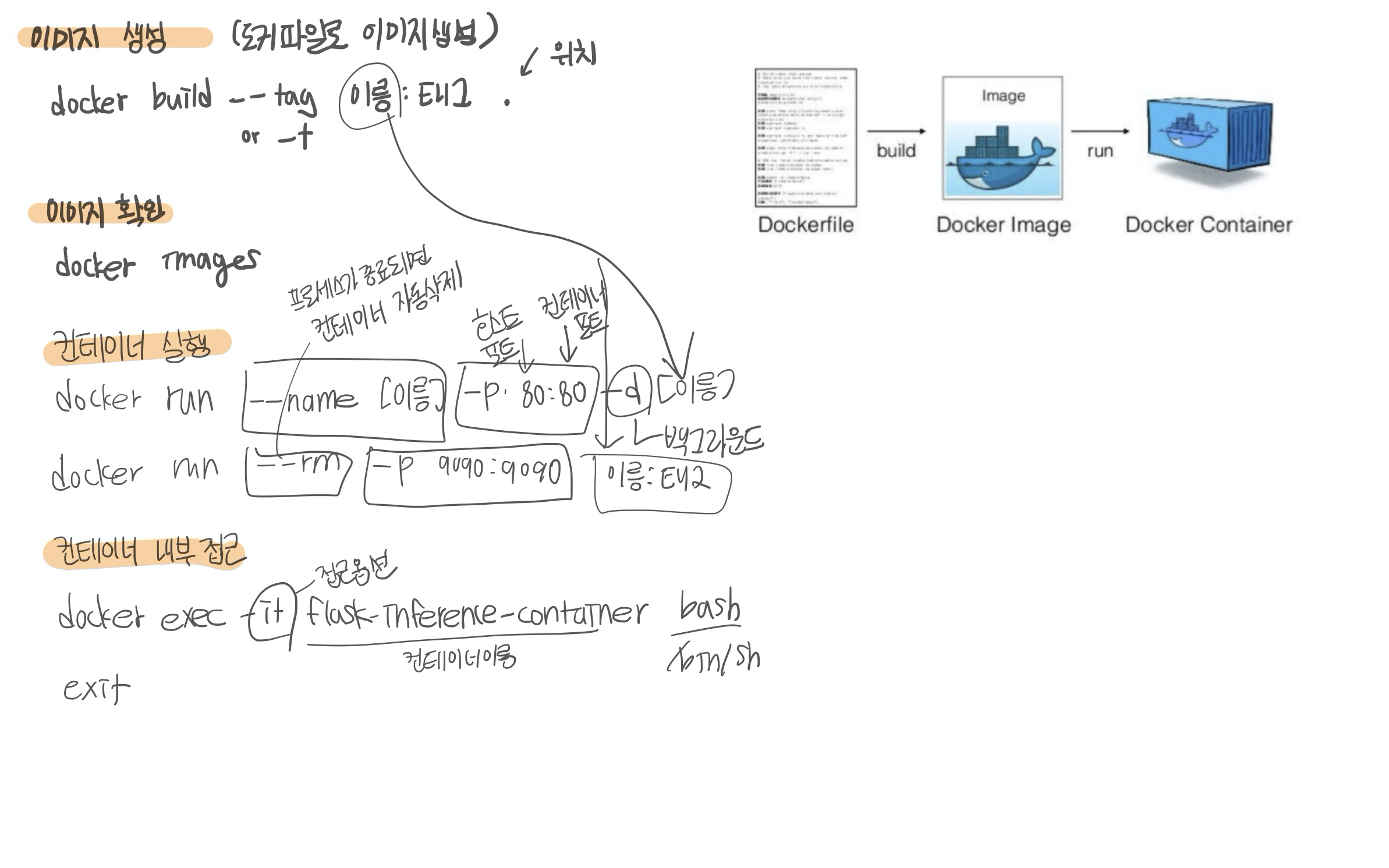
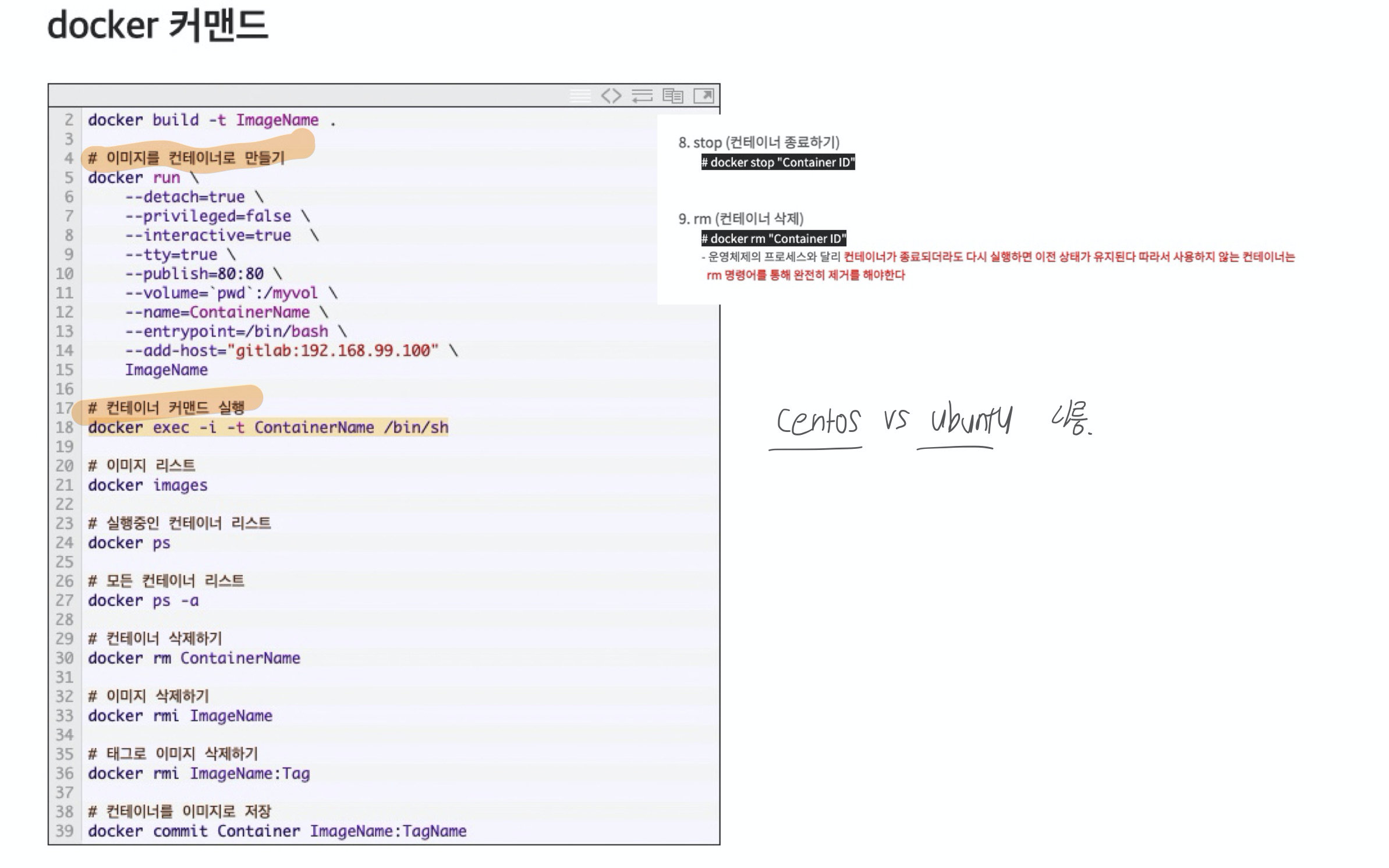
초반에는 직접 빌드하여 올려두고 사용하였으나 현재는 각종 공식 업체에서 기본 이미지를 생성하여 제공하고 있고, Dockerfile에 alpine버전으로 가져와서 필요한 것만 빌드하여 저용량으로 이미지를 수월하게 만들 수 있게 되었습니다. 이렇게 생성된 이미지를 가지고 실행하면 컨테이너가 생성되고 해당 공간은 내부에 전혀 영향 없는 독립적인 별개의 공간으로 활용 할 수 있습니다. docker-compose를 이용하면 더 쉽게 여러 개의 컨테이너를 실행 할 수 있습니다.
애플리케이션 코드 복사 명령(COPY) 은 자주 변경되지 않는 명령문 다음에 오는 것이 이미지 빌드 시간을 단축하는 데 유리하다.
이전 단락에서 의존성 패키지를 명시한 파일로 requirements.txt를 사용했다. 이 파일은 Python의 공식 패키지 관리자인 PIP에서 사용하는 관행적으로 지칭하는 파일이다.Python 개발 환경을 기준으로 봤을 때 PIP는 패키지별 상호 의존성에 관계를 관리할 때 부족한 면이 있다. 그래서 요즘은 좀 더 발전된 Locking 시스템을 갖춘 Pipenv나 Poetry를 사용하는 것을 추천한다.
이 도구들을 이용해 생성된 Lock 파일 (예: Pipfile)을 기반으로 패키지가 설치될 수 있도록 한다면 위 (3) 단락에서 설명한 캐시 레이어의 장점을 얻을 수 있고, 예상치 못한 패키지 버전 업데이트도 방지할 수 있다.
멀티-스테이지 빌드
는 위 (2), (3), (4) 단락에서 했던 노력보다 훨씬 더 효과적으로 도커 이미지 사이즈를 줄이는 방법이다.
멀티-스테이지 빌드는 Dockerfile 1개에 FROM 구문을 여러 개 두는 방식이다.각 FROM 명령문을 기준으로 스테이지를 구분한다고 했을 때 특정 스테이지 빌드 과정에서 생성된 것 중 사용되지 않거나 불필요한 모든 것들을 무시하고, 필요한 부분만 가져와서 새로운 베이스 이미지에서 다시 새 이미지를 생성할 수 있다.
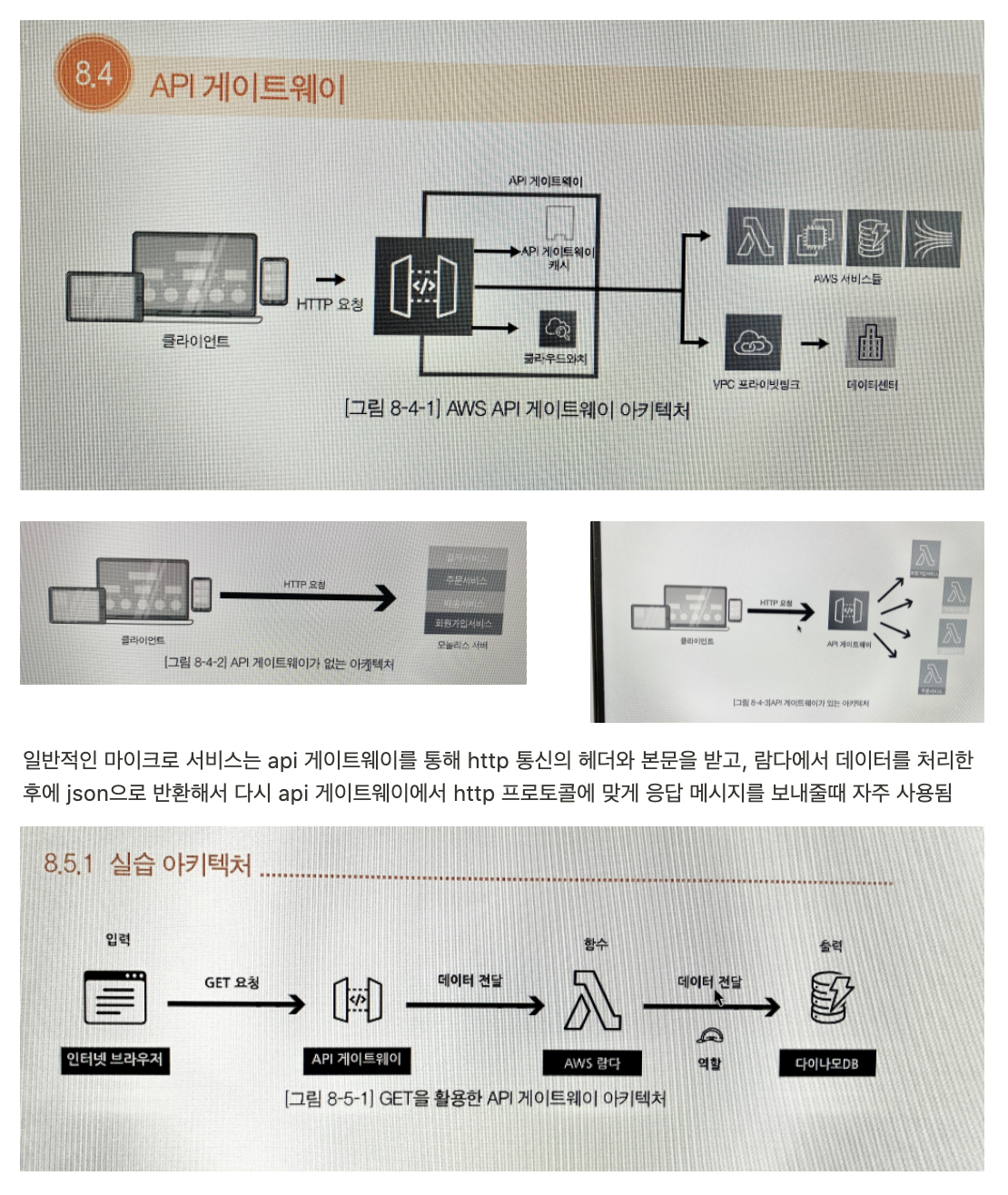
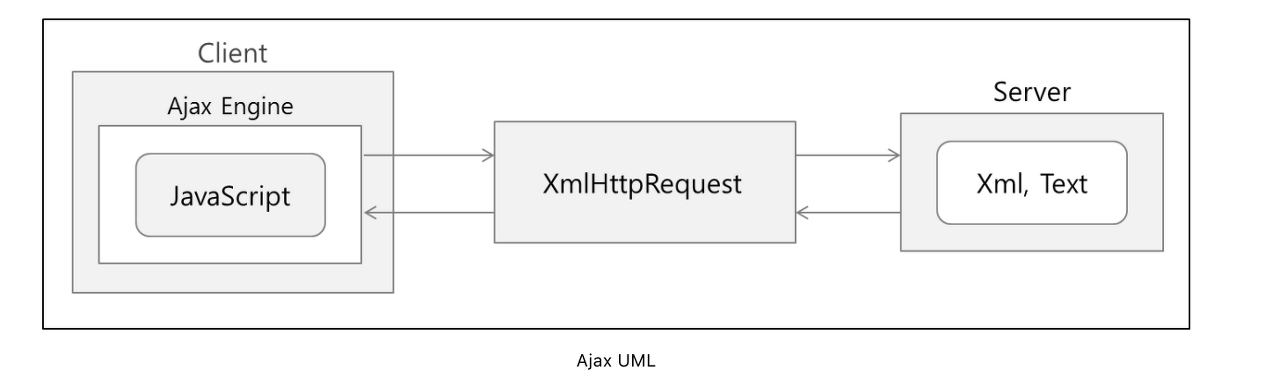
브라우저가 가지고있는 XMLHttpRequest 객체를 이용해서 전체 페이지를 새로 고치지 않고도 페이지의 일부만을 위한 데이터를 로드하는 기법 이며 JavaScript를 사용한 비동기 통신, 클라이언트와 서버간에 XML 데이터를 주고받는 기술이다. (https://velog.io/@surim014/AJAX란-무엇인가)
단순히 웹화면에서 무언갈 부르거나 데이터를 조회하고 싶을때 페이지전체를 새로고침하지않기위해 사용한다.
기본적으로 HTTP 프로토콜은 클라이언트쪽에서 Request를 보내고 서버쪽에서 Response를 받으면 이어졌던 연결이 끊기게 되어있다. 그래서 화면의 내용을 갱신하기 위해서는 다시 request를 하고 response를 하며 페이지 전체를 갱신하게 된다. 하지만 이렇게 할 경우, 엄청난 자원낭비와 시간낭비를 초래 → ajax를 사용
서버에서 데이터를 http get, post, json 의 모든방식으로 전송한후 서버측 응답을 받으럐때 사용, http get방식으로 전송한후 서버측 응답을 json형식으로 받을떄는 $get.JSON 을 사용한다.
var serverAddress = 'https://hacker-news.firebaseio.com/v0/topstories.json';
// jQuery의 .get 메소드 사용
$.ajax({
url: ,
type: 'GET',
success: function onData (data) {
console.log(data);
},
error: function onError (error) {
console.error(error);
}
});
<script>
$(document).ready(function() {
jQuery.ajax({
type:"GET",
url:"/test",
dataType:"JSON", // 옵션이므로 JSON으로 받을게 아니면 안써도 됨
success : function(data) {
// 통신이 성공적으로 이루어졌을 때 이 함수를 타게 된다.
// TODO
},
complete : function(data) {
// 통신이 실패했어도 완료가 되었을 때 이 함수를 타게 된다.
// TODO
},
error : function(xhr, status, error) {
alert("에러발생");
}
});
});
</script>
출처: https://marobiana.tistory.com/77 [Take Action]
전제조건 : 내가보고있는 페이지에서 다른페이지의 rest api를 호출해서 데이터를 json으로 가져오려고함. 내가 이용하는 페이지주소랑 데이터를 가지고 오기위한 서버 도메인이 서로 다를경우 crossdomain이라고 부름.
formData
비동기 업로드를 위해 ajax formData를 사용함. 평소엔 안쓰임 , 이미지를 ajax로 업로드할때 필요함.
*** 비동기?
비동기 처리 ? 특정 코드의 연산이 끝날떄까지 코드의 실행을 멈추지않고 다음코드를 먼저 실행하는 자바스크립트의 특성을 의미함. → 제이쿼리의 ajax를 많이씀.
function getData() {
var tableData;
$.get('https://domain.com/products/1', function(response) {
tableData = response;
});
return tableData;
}
console.log(getData()); // undefined
// get 부분이 ajax로 통신을 하는 부분임. http~ 에 get 요처응ㄹ 날려서 product정보를 요청함.
// 한마디로 쉽게 말하면 지정된 url에 데이터를 하나 보내주세요 라는 요청을 날리는것과 같음.
// http 서버에서 받아온 데이터를 respose 인자에 담김
// getdata는 뭐임?? undefined 왜? 왜냐 이전에 미리 return 해줘서 그럼. 기다려주지않고 바로
리턴해버려서 undefined를 출력하게됨.
// 이런식으로 특정로직의 실행이 끝날떄까지 기다려주지않고 나머지 코드를 먼저 실행해버리는게 비동기처리라는것임
콜백함수로 비동기처리 방식의 문제점 해결하기
function getData(callbackFunc) {
$.get('https://domain.com/products/1', function(response) {
callbackFunc(response); // 서버에서 받은 데이터 response를 callbackFunc() 함수에 넘겨줌
});
}
getData(function(tableData) {
console.log(tableData); // $.get()의 response 값이 tableData에 전달됨
});
i 를 x축 중심 이라고 하면 바1은 -0.18 ,바2는 +0.18 해서 두 그래프가 딱붙어서 출력
x= [ i-0.20 for i in range(7)]
x2= [ i+0.20 for i in range(7)]
x_middle= [ i for i in range(7)]
plt.bar(x, original,color='darkgray',width=0.36,label='label1', edgecolor='black')
plt.bar(x2, (a+b+c+d)/4 ,color='white',width=0.36,label='lable2',edgecolor='black',hatch='/')
- 붙은 그래프
바그래프 가로길이 0.36 반띵하면 .018
i 를 x축 중심 이라고 하면 바1은 -0.20 ,바2는 +0.20 해서 두 그래프두개 0.4 띄워서 출력
x= [ i-0.18 for i in range(7)]
x2= [ i+0.18 for i in range(7)]
x_middle= [ i for i in range(7)]
plt.bar(x, original,color='darkgray',width=0.36,label='label1', edgecolor='black')
plt.bar(x2, (a+b+c+d)/4 ,color='white',width=0.36,label='lable2',edgecolor='black',hatch='/')
plt.xticks(x_middle,['a','b','c','d','e','f','g'])
plt.xticks(rotation=90,fontsize=80,ha="right")
# ha는 오른쪽을 기준으로 맞추라는뜻
<바그래프 위에 텍스트 표시>
o= ['%','%','%','%','%','%','%']
for i, v in enumerate(x2):
plt.text(v, original[i], str (round(((original-(a+b+c+d)/4)/original*100)[i],1))+o[i] ,
fontsize = 60,
color='black',
#weight="bold",
horizontalalignment='center',
verticalalignment='bottom')
mp4_cctv_list=[]
for i in file_list:
# 현재 디렉토리에 있는 모든 파일 리스트를 가져온다
path = "./task1/"+str(i)
file_listttt = os.listdir(path)
mp4_cctv = [file for file in file_listttt if file.endswith(".mp4")]
mp4_cctv_list.append(mp4_cctv)
for j in range(1,len(file_list)):
mp4_cctv = "./task1/"+str(file_list[j-1])+"/"+str(mp4_cctv_list[j-1][0])
try :
# -------------------- 동영상 쪼개기 ------------------------------------------------------------
import cv2
n=119 #동영상을 119개로 쪼개줄것임
vidcap = cv2.VideoCapture(mp4_cctv)
total_frames = vidcap.get(cv2.CAP_PROP_FRAME_COUNT)
frames_step = total_frames//n
for i in range(n):
#here, we set the parameter 1 which is the frame number to the frame (i*frames_step)
vidcap.set(1,i*frames_step)
success,image = vidcap.read()
#save your image
globals()['col{}.jpg'.format(i)]= image
#cv2.imwrite(globals()['./col{}.jpg'.format(i)],image)
# 저장해줄 위치 지정해줌
cv2.imwrite('./new2/col'+str(i)+'.jpg',image)
vidcap.release()
# -------------------- yolo ------------------------------------------------------------
# Yolo 로드
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
classes = []
with open("coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
colors = np.random.uniform(0, 255, size=(len(classes), 3))
for k in range(119): #수정 119로
# 이미지 가져오기
print('사진' ,k)
img = cv2.imread("./new2/col"+str(k)+".jpg")
img = cv2.resize(img, None, fx=0.4, fy=0.4)
height, width, channels = img.shape
# Detecting objects
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
# 정보를 화면에 표시
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
# Object detected
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# 좌표
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
font = cv2.FONT_HERSHEY_PLAIN
label_lists=[]
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = str(classes[class_ids[i]])
color = colors[i]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
cv2.putText(img, label, (x, y + 30), font, 3, color, 3)
label_lists.append(label)
cv2.imshow("Image", img)
cv2.waitKey(1)
cv2.destroyAllWindows()
print(label_lists)
df['mp4'][:][k]=label_lists
#맥에서 opencv 안닫힐때 꿀팁
cv2.destroyAllWindows()
cv2.waitKey(1)
cv2.waitKey(1)
cv2.waitKey(1)
cv2.waitKey(1)
except :
print('exept',file_list[j-1],j-1)
Xi = np.array([[0,17,21,31,23],[17,0,30,34,21],[21,30,0,28,39],[31,34,28,0,43],[23,21,39,43,0]]) dists = squareform(Xi) #여기서 flat하게 바꾸어 주어야한다.이거 안해주고 넣으면 어딘가 이상해짐 Z = linkage(dists, method='single') # method는 여기서 변경해주면 된다 dendrogram(Z) # 아래 그래프 출력 plt.axhline(20, color='k', ls='--'); #임계치값(20)에 대해 점점이 가로줄을 그어줌
shc.fcluster(Z, 20, criterion='distance') #임계치20에 줄을 그어서 나누어지는 군집들
→ [a,b][c][d][e] 이렇게 나누어짐을 확인할수 있습니다.
<개념부분>
첫번째줄에서, 임계값을 주지않으면, 총 1개의 군집이 출력됩니다. (method별로 만들어지는 dendrogram 모양이다릅니다)
두번쨰 줄에서 임계값을 줌으로써 여러개의 군집으로 나누어줄수 있습니다.
이것은 method 별로 유사도를 처리하는 방법이 다른것을 자세히 나타내 줍니다.
(single 은 가장 가까운 거리를 채택, complete 는 가장 먼거리를 채택, average는 이 두개의 평균을 채택합니다.)
e.g. single linkage 방법에서 abce, d 사이의 거리를 구할때, d와 ab간의 거리 31, d와 c간의 거리 28, d와 e간의 거리 43중에 가장 작은값인 28을 선택해줍니다. 만약 complete linkage 방법이였다면, 43을 선택해주었을것입니다.
(centroid , ward 이 두가지 메소드는 계산과정에서 (x,y)축을 필요로 하기 때문에 x,y축에서 pdist로 유사도를 구하는 방식이 아니라 처음부터 유사도를 집어넣어서 계산하는 방법에는 바람직하지 않음
먼저 간단히 논문의 개요를 살펴보자면, 요즘 머신러닝은 이기종 리소스를 보유한 전담 작업자가 아니라, 클러스터에서 더많이 훈련이 됩니다. 이떄, 다른워커보다 훨씬 느리게 실행되는 스트래글러는 부정적인 영향을 미칩니다. (오른쪽 그림, 빨간색 화살표) 여기서 스트래글러가 의미하는것은 적은수의 스레드가 주어진 반족을 실행하는데 다른 스레드보다 오래걸릴떄 발생하는 문제를 의미합니다. 모든 스레드는 동기화되어야해서 모든 스레드는 가장 느린 스레드(스트래글러)의 속도로 진행할수밖에 없기 때문입니다. 이 논문의 핵심은 이 샘플 배치의 크기를 적절하게 조정해서 작업자의 부하를 즉각적인 처리기능에 맞게 조정하는것입니다.
이 논문에서는 ML 워크로드의 스트래글러를 제거하기 위해 SEMI Dynamic Load balancing이라는 새로운 방법을 제안합니다. 그리고 이방법을 이용해서 LP_BSP를 구현합니다. 여기서 BSP란 병렬 소프트웨어와 하드웨어 개발의 기준이 되는 모델로 PRAM 모델의 일종입니다.
**Pram ⇒ 공유 메모리르를 사용해서 프로세스간에 병렬 통신을 지원하는 구조입니다.
이 체계에서 빠른 작업자는 각 iteraiton이 끝날때마다 느린 작업자(스트래글러)를 기다려야함으로 스트래글러는 모델의 학습 효율성을 저하시킵니다. 이 기존의 BSP모델의 단점을 보완한것이 LP-BSP 모델입니다.
들어가기 앞서서 이 논문에서 자주 쓰이는 개념들에 대해 간단히 짚고 넘어갑니다. 클러스터는 다음과 같이 두가지 종류로 나뉘는데, 전자의 경우, 전용 클러스터라고 불리며 후자의 경우 비전용 클러스터라고 합니다.
전자는 높은 효율성을 보이지만, 유지관리 비용이 많이 들고 널리 엑세스가 불가함으로 쉐어링이 되지 않는 문제를 가지고있습니다.
후자의 경우, 비전용 클러스터로 앞서 설명한 이기종 하드웨어로 구성되어있으며, cpu 와 gpu의 빠른 발전속도에 맞게 aws같은곳에서 이기종 하드웨어 세트로 모델을 학습시킬수 있습니다. 이 경우 dynamic하게 리소스들이 할당되며, 싸고 용량문제가 비교적 적게 발생합니다.
최근 비전용 클러스터(위에서 설명드린) 에서 주로 모델 훈련이 이루어지는 한편, 더 심각한 스트레글러 문제가 발생합니다. 스트래글러의 경우에도 크게 두가지로 나뉠수가 있는데 비결정론적 스트래글러, 결정론적 스트레글러로 나뉠수가 있습니다.
전자의 경우, os 지터같은 일시적인 장애로 인해 발생하며, 일시적이로 아주 미미합니다
** os jiter: e.g. 백그라운드 데몬 프로레서의 에약 / 비동기 이벤트 처리로 인해 발생하는 간섭
하지만 후자의 경우, 전자에 비해 훨씬 심각하고 오래 지속됩니다. 그리고 이는 앞서 설명드린 비전용 클러스터에서만 발생합니다.
간단히 말하면, 스트래글러는 적은 수의 스레드에서 주어진 반복을 실행해야하는데 다른 스레드보다 오래걸릴때 발생하는 문제입니다 모든 스레드가 동기화되어야해서 각 스레드는 iteraiton마다 가장 느린 스레드의 속도로 진행되어 문제가 발생하는것입니다.
이제 이런 스트래글러를 해결하기위해 과거에 행해졌던 여러가지 시도들에 대해 살펴봅니다.
ASP 방식은 다른 worker를 기다리지 않고 독립적으로 다음 반복을 수행합니다. 이렇게 하면 컴퓨팅 주기를 낭비하지않고 하드웨어적으로 효율이 높습니다. 그런데 가장큰 문제가 global하게 매개변수가 동기화가 제대로 되지않아 부실한 매개변수를 사용하게 될 확률이 높아집니다. 이는 앉은 품질의 업데이트를 만들어내기 때문에 더 많은 Iteraitondl 필요하게되고 결국엔 그렇게 효과적인 스트래글러 해결방법은 아닌듯합니다.
SSP 방식은 앞서 ASP 와 BSP를 섞어놓은 방법입니다. 매개변수 비활성이 특정한 임계값에 도달할때만 스트래글러를 기다려줍니다. 하지만, SSP는 주로 비결정적 스트레글러에만 초점을 맞춘 방법이기 때문에, 결정적 클러스터에 적용할경우 지연이 자주 발생할수 있습니다. ASP 와 BSP가 섞인 방법이기 떄문에 여전히 스트래글러가 발생시 기다려야하는 문제가 남아있고 해결되지 않았습니다.
Redundant execution이라는 방법은, 스트래글러 worker에 여러 복사본을 두어서 먼저 완료된 작업의 결과만 받아들이는 방법입니다. 그런데 이 방법은 차선책일뿐, 일부의 스트래글러만 완화해주지만 최악의 스트래글러의 경우 전혀 도움이 되지 않습니다. 복제본이 모두 느리다면 큰 효과가 없기 때문입니다. 또 복제본을 만들기 때문에 추가적인 리소스를 소비해야 한다는것이 단점입니다.
지금까지의 방법들은 전부 스트래글러가 발생할경우 이를 완화하는 방법들만을 다루었지 스트레글러의 근본원인에 대해 서는 다루지 않았습니다. 애초에 스트레글러가 발생하는것을 방지하면 더 근본적으로 문제를 해결할수 있습니다. 이를 위해서는 로드밸런싱 기술에 의존할 필요가 있습니다. 이 로드밸런싱(부하분산) 은 병렬처리에서의 고전적인 연구주제이며 두가지 (static , dynamic) 방식으로 나뉩니다.
전자는 정적 부하분산방법이고 후자는 동적 부하분산 방법입니다.
정적 부하분산은 라운드 로빈같이 정적인 양을 다루며, 동적 부하분산은 부하가 많은 작업자의 일을 런타임부하가 적은 작업자로 재분배해줍니다
아래 그림은 FLEXRR 이라고 최근의 Dynamic한 load balancing 방법입니다. 주어진 임계값에 대해서 다른 작업자보다 뒤처지면(slow) Fast한 작업자에게 일을 제공합니다
이 논문에서는 이 dynamic load balancing 개념을 사용해서 Sem-dynamic loac balancing이라는 전략을 제공합니다
앞서 말한방법들을 바탕으로 새로운 전략을 내놓았습니다. 각 iteraiton 안에서는 정적으로 부하를 유지하지만, 다른 iteraiton에서는 동적으로 유지합니다. 이게 무슨말이냐 하면, 각 iteraiton의 경계부분에서 각 worker들의 상태를 측정합니다. 요즘에는 iteration의 크기가 아주 작고 iteraiton안에서도 엄청나게 큰 변화가 일어나는것이 아니기 때문에 (위 그래프에서 보면 배치 사이즈별로 iteraion time이 몇초 혹은 0.몇초 대로 굉장히 작음을 알수있습니다) iteraiton 의 경계부분에서 측정해도 충분합니다.
한마디로 iteraiton 전부를 볼필요없이 경계부분만 살펴본다는것입ㄴ디ㅏ
두번쨰로, 각 경계에서 스태글러를 감지해냅니다.
세번쨰로, 각 iteraiton 별 경계에서 스트래글러를 감지해내고 배치크기를 조정해줍니다.
이러한 로드밸런싱 전략을 사용할것이라고 합니다.
이제 앞에서 load balancing 전략을 정해주었으니, 비전용 클러스터에서 효율적인 분산학습을 위해 LB-BSP라는 새로운 방법을 제시합니다. 먼저 모델학습 반복과정에서 iteration이 걸리는 총 시간은 t 이고, 이 t는 tm + tp로 이루어집니다 (위 피피티에 설명)
x 는 배치를 의미합니다. 그런데 정해놓고 보니, cpu와 gpu 클러스터에 각각 다른 문제가 발생합니다. cpu 클러스터에서는 ti와 xi가 선형적으로 증가하는데 ( 배치 사이즈가 커지면 프로세싱 시간인 t도 늘어난다) , Gpu는 비선형적입니다. 그래서 cpu와 gpu를 각각 따로따로 살펴보기로 합니다.
cpu는 gpu같은 가속기가 없기 때문에 다음과같은 상황에서 주로 쓰입니다 ( 피피티 위에 설명)
그리고 앞 피피티에서 말한것처럼 x,v 간에 선형관계를 이루고 있습니다. 그리고 t에서 tp가 99퍼를 차지하고 있기 떄문에 tm은 무시해도 별 영향이 없습니다.
Γ (x) 값이 선형적이기 떄문에 tp와 배치사이즈(x) 는 비례하게됩니다. 그래서 다음 반복에 대해 작업자 배치 크기를 결정하기 위해서는 현재 반복에서 샘플처리속도만 알면됩니다.
그런데 문제가, 샘플처리속도가 항상 일정한것이 아니라 동적으로 달라지기 때문에, NARX라는 방법을 사용합니다
NARX는 RNN의 일종으로 과거속도와 현재속도, cpu및 메모리 사용량같은 과거와 현재값을 모두 받아들이는 방법이라, 보다 좋은 성능을 보인다고 합니다.
위 알고리즘을 간단히 살펴보면, 이전 피피티에서 언급했던 샘플 처리 속도 (v)의 과거 값 / CPU 및 메모리 사용량 (c / m)의 두 구동 리소스의 현재 과거 값들을 받아옴을 확인할수 있습니다.
tp와 해당 함수의 식을 조합해서 v(속도)를 구하고 이 속도를 F (NARX 함수) 에 넣어서 계산해줍니다. 앞 피피티의 연산식을 활용하여 새로운 배치사이즈를 리턴해줍니다.
앞서 cpu 클러스터에 대해 살펴보았고 이번에는 gpu 클러스터에 대한 성능을 특성화 한다음 알고리즘을 제시해주었습니다. 우선 gpu의 성능으로는 앞서 cpu에서는 tm을 무시해주었지만 gpu에서는 무시해주면 안됩니다. gpu에서 계산은 cpu에서보다 훨씬 빠르고 이에따라 통신시간도 무시할수 없어졌습니다.
또 gpu를 수행하기 위한 일련의 준비작업(메모리간에 매개변수 교환, 처리커널 시작..)에도 상당한 오버헤드가 발생하기 떄문에 이 것들도 무시할수 없어졌습니다.
세번쨰로, tesla100 같은 최신의 고급 gpu의 경우 샘플배치가 너무 작아서 일정 크기이상으로 샘플 배치크기를 줄인다면 성능이 확 떨어지게 됩니다.
네번쨰, 각 반복동안 중간겨로가와 매개변수등을 모두 gpu 메모리에 저장해야함으로, 최대 배치크기를 제한해야합니다. (메모리부족을 예방하기위해)
앞 피피티에서 살펴본것들을 바탕으로 다음 알고리즘을 살펴보면
우선 각 iteration에서 가장 느린 작업자를 스트래글러로 지정해주고 가장 빠른 작업자를 리더로 지정해줍니다.
먼저 위 피피티에서 세번쨰문제를 해결하기위해 특정 배치크기 이하로 떨어지는것을 예방해줍니다.
두번쨰로 여전히 스트래글러의 크기가 리더보다 크다면, 리더의 배치크기를 조금 줄여주고, 스트래글러의 배치크기를 조금 늘려주는 방향으로 균형을 잡아갑니다
세번쨰로 반대가 된다면 파인튜닝을 통해 스위치 해줍니다.
*파인튜닝 : 기존에 학습되어져 있는 모델을 기반으로 아키텍쳐를 새로운 목적으로 변형하고 이미 학습된 모델 weights 로 부터 학습을 업데이트하는 방법을 의미합니다.
마지막으로 cpu,gpu별로 결과값을 살펴보면, 그래프 3개짜리에서 보면 (A) 그래디언트 업데이트당 시간의 평균 / worker의 수를 의미합니다. (B)는 통계적 효율성으로 목표하는 정확도에 도달하는데 필요한 업데이트수를 의미합니다. (한마디로 목표한 정확도에 이르기까지 반복하는 iteraion수를 의미합니다.) (c)는 목표정확도에 도달하는데 필요한 전체시간을 보여줍니다.(=목표한 정확도에 도달하는데 필요한 전체 시간)
세개 그래프 값에서 모두 LB-BSP 이 가장 적은 업데이트수와 시간을 가짐을 확인할수 있습니다.
아래그래프 2개를 보면, 마이크로 벤치마크를 실시한것으로 인스턴스 4개만 실시한것을 비교한것입니다. ( 인스턴스 4개를 합쳐준것을 cluster A라고 부릅니다) iteraion 횟수가 점점 늘어날수록 일정한값에 도달함을 알수 있습니다. 또 iteraion 횟수가 점점 늘어날수록 4개 인스턴스 값의 배치 처리시간이 거의 같아져서 straggler 문제가 해결됨을 확인할수 있습니다
cpu에서도 살펴봅니다. 여기선 table B 와 같이 인스턴스들을 합친 cluster-B를 만들어 살펴봅니다.
figure 9 는 cluaster B 에서 서로 다른방식으로 SVM 과 ResNet-32를 훈련할떄의 평균반복시간을 보여줍니다. LB-BSP가 가장 짧은 시간으로 최고의 효율성을 이끌어낼수있음을 확인할수 있습니다.
FIgure 10은 NARX 모델을 사용했을떄의 예측성능을 추가로 평가해준것입니다. 클러스터 B에서 m4.2xlarge 인스턴스 하나에 대한 resnet-32 훈련 프로세스에서 무작위로 iteration을 골라 살펴본것입니다. 이를 통해 NARX가 기존의 방법 뿐만아니라 프로세싱 속도 예측도 잘한다는 추가적인 기능도 확인할수 있습니다.
+)
NARX 그래프에 대한 내용에서 accuracy 라고 잘못 설명했던 부분을 정정합니다.
→ 그래프의 내용은 m4.2xlarge 스턴스 하나에 대한 ResNet-32 훈련 프로세스에서 iteration을 무작위로 선택한 구간으로, LP-BSP의 성능을 나타내기위한 지표라기보다 , NARX의 성능을 더 보여주기위해 추가적으로 진행해준 실험에 대한 표였습니다. (cluster-B 를 사용해서 prediction을 실시해준 결과를 나타낸준것 )
19p Figure 4 그래퍼에서 xo 가 의미하는것은 최대 배치사이즈 제한값입니다. 메모리 부족문제를 방지하기위해서 배치사이즈크기의 최대값을 지정해준것을 의미합니다
베이지안 관점의 통계에서는 사전확률과같은 경험에 기반한 선험적인,불확실성을 내포하는 수치를 기반을 하고 거기에 추가정보를 바탕으로 사전확률을 갱신한다.(귀납적 추론)
e.g.
질병 A의 발병률은 0.1%.이 질병이 실제로 있을 때 질병이 있다고 검진할 확률(민감도)은 99%, 질병이 없을 때 없다고 실제로 질병이 없다고 검진할 확률(특이도)는 98%라고 하자.
만약 어떤 사람이 질병에 걸렸다고 검진받았을 때, 이 사람이 정말로 질병에 걸렸을 확률은?
한마디로 정의하면 : Random Search와 통계적인 기법 (Gaussian Distribution)을 기반으로 실제 data를 이용하여 surrogate model을 이용하여 실제 model을 찾지 않아도 Maximum value를 도출해낼 수 있다는것.
1. 지금까지 관측된 데이터 D = [(x1, f(x1)), (x2, f(x2)) … (xn, f(xn))]을 통해, Gaussian process prior로 function f(x)를 Estimation한다. (= surrogate model)
** Surrogate model(대체 모델, 근사수학모델)
이란 자동차 충돌 실험과 같이 제한된 계산 비용이 많이 드는 시뮬레이션을 기반으로 복잡한 시스템의 수많은 입출력 특성을 실제 모형과 유사하게 만드는 것
여기서 f(x)는 함수이고, x는 하이퍼 파라미터이다!!!!!!!! (x가 여러개일수도 있음)
그러니까 앞에서 함수의 해당 하이퍼파라미터랑 , 탐색대상 함수를 쌍으로 만든다음, 이것을 대상으로 surrogaate model을 만들어서 평가를 순차적으로 업데이트하여 최적의 하이퍼파라미터조합을 탐색하는 과정
관측치 수(코드에서 나오는데 n_iter로 몇번 반복할지 조정가능함) 가 증가함에 따라 사후 분포가 개선되고 알고리즘은 아래 그림에서 볼 수 있듯이 매개 변수 공간에서 탐색 할 가치가있는 영역과 그렇지 않은 영역이 더 확실해진다.(한마디로 위에 피피티 그림에서 회색부분 공간이 점점 줄어들고 대충 모양이 잡힌다는 뜻임)
(피피티 4개짜리 그래프 설명) 위 피피티에서 4개짜리 그림을 보면, 1번에서 모양이 살짝 바뀌었다. 두번째로는 제일 값이 높아보이는쪽으로 이동한다. 먼가 모양이 좀더 좁아졌다. 세번째로는 variance가 제일 높아보이는데로 이동했다. 이렇게 계속 반복반복하다보면 4번째 그림처럼 되고, 노란색 부분 즉 maximum값을 구할수있다.
→ 이렇게 Exploitation/Exploration 을 반복해주는 매커니즘이
acquisiton function
인것임 (용어는 뒤에....)
2. Function f(x)를 다음으로 관측할 지점 (xn+1, f(xn+1))으로 Acquisition Function(decision rule)으로 선택하여 이동한다.(제일 중요하다)
acquisition functio
n
은 surrogate model이 목적함수(우리가 찾고자하는 함수) 에 대해서 실제 데이터를 기반으로 다음번 조사할 x값을 확률적으로 계산해서 추천해주는 함수
**Exploitation 은 현재까지 조사된 값들의 근방으로 다시 조사를 하는 것이다. 착취를 말한다.
**Exploration 은 현재까지 조사된 값들의 근방으로 조사를 하지 않고, 불확실성이 제일 높은 구간을 조사한다. 탐험을 말한다.
<acquisition function 종류>
EI (Expected Improvement / MEI 라고도함 )는 Exploration 과 Exploitation 방법을 모두 일정 수준 포함하도록 설계된 것이고, 제일 많이 쓰는 Acquistion Function이다.
from bayes_opt import BayesianOptimization
# Bounded region of parameter space
pbounds = {'x': (2, 4), 'y': (-3, 3)} #하이퍼 파라미터 정해줌
optimizer = BayesianOptimization(
f=black_box_function, #앞에서 지정해준 black_box_funciton을 함수를 f에 넣어준다.
pbounds=pbounds, #하이퍼 파라미터 넣어준다.
verbose=2, #verbose = 1 prints only when a maximum is observed, 0일땐 silent ,versbose=2 항상
random_state=1, #seed, 무작위성을 컨트롤 0이면,반복해도 똑같은값 출력함.
)
optimizer.maximize(
init_points=2, # init_points : 수행하려는 임의 탐색 단계 수. 무작위 탐사는 탐사 공간을 다양 화하여 도움을 줌.
n_iter=3, # n_iter :위에서 임의탐색한거 주위에서 찾아봄 (3.4, 3.5, 3.002, 2.7, 2.95 이렇게)
acq='ei', #aacquisition 선택 ( ei / poi / usb ) - 이것에 따라 성능이 갈리기도 한다.
)
# 임의 탐색2번 + 반복3번해서 총 5개 나오는것!











































Uploaded by Notion2Tistory v1.1.0