에러 : botocore.exceptions.ClientError: An error occurred (UnrecognizedClientException) when calling the ListAccounts operation: The security token included in the request is invalid.
-> 위에서 입력한 aws_access_key_id / aws_secret_access_key 이 잘못 입력됬다는 뜻. 제대로 된 값으로 다시 설정해준다
Traceback (most recent call last):
File "/usr/lib/cnf-update-db", line 8, in <module>
from CommandNotFound.db.creator import DbCreator
File "/usr/lib/python3/dist-packages/CommandNotFound/db/creator.py", line 11, in <module>
import apt_pkg
ModuleNotFoundError: No module named 'apt_pkg'
Reading package lists... Done
E: Problem executing scripts APT::Update::Post-Invoke-Success 'if /usr/bin/test -w /var/lib/command-not-found/ -a -e /usr/lib/cnf-update-db; then /usr/lib/cnf-update-db > /dev/null; fi'
E: Sub-process returned an error code
del df['A']
df.drop(["B", "C"], axis=1)
df.drop(columns=["B", "C"],inplace=True)
df.pop("A") # A열만 반환해준다음,df확인해보면 A 빠져있을것
행삭제
df = df.drop(index=0, axis=0)
df = df.drop(index=[0, 1, 2], axis=0)
new_iris = iris.drop([1,2])
df.drop(["B", "C"], axis=0)
# 특정문자(save_fig2리스트에저장) 가 포함된 열 삭제
for i in save_fig2:
print(i)
df2 = df2[df2.columns.drop(list(df2.filter(regex=i)))]
# 확장자가 ipynb인 Jupyter Notebook 파일을 아래 명령어를 이용하여 python 파일로 변환. 아래 명령은 xgboost-wine-quality.ipynb 파일을 step0-xgboost-wine-quality.py 로 변환하는 예시.
jupyter nbconvert xgboost-wine-quality.ipynb --to script --output step0-xgboost-wine-qual
check_models = ['MNIST_CNN','AlexNet','CIFAR10','InceptionV3',
'VGG19','ResNet50','InceptionResNetV2','LeNet5',
'ResNetSmall']
for i in (check_models):
if i in save_name:
model = i
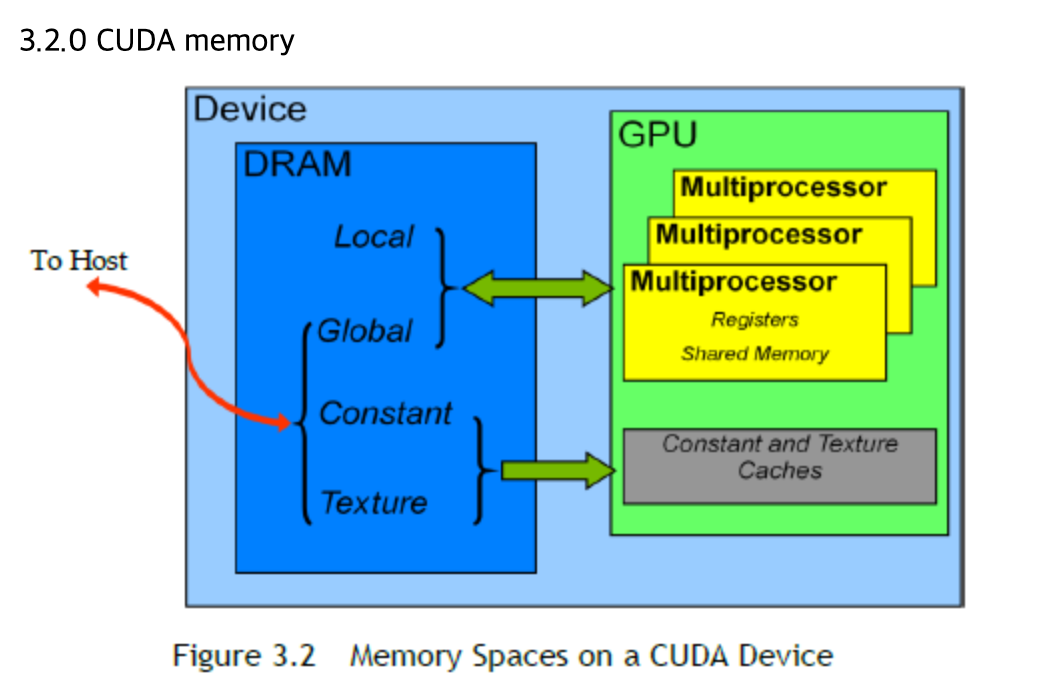
온칩메모리는 GPU 칩 안에 있는 메모리로, 레지스터 메모리 / 로컬 메모리 라고 부릅니다.
레지스터는 GPU 커널 안에 선언되는 변수로, GPU 칩안에 있기 때문에 접근 속도가 빠릅니다.
레지스터 변수는 코어에 할당된 스레드가 분배해서 사용하는데, 커널 안에서 사용해야 할 변수가 많아지면 로컬 메모리에 레지스터 변수를 할당할 수 있습니다.
온칩은 속도가 빠른 대신에 비용 등의 이유로 인해 메모리 사이즈가 비교적 작습니다.
직접 연산수행하는 제일빠른 메모리 (싸인,코싸인 함수계산도 레지스터메모리사용함)
오프칩 : (=글로벌 메모리)
그래픽 카드에 장착한 DRAM으로
CUDA에서는 이 off칩을 글로벌 메모리 / 디바이스 메모리라고 합니다.
메모리를 할당 및 해제하는 방법은 GPU 포인터를 선언 -> cudaMalloc 명령으로 메모리 할당해주기 -> 메모리 해제(cudaFree)
계산에 필요한 입력 데이터는 GPU가 아닌 CPU 메모리 영역에 있기 때문에 PCI-e 인터페이스를 통해서 GPU로 메모리를 전송합니다.
속도는 공유메모리랑 레지스터에 비하면 느린편이지만 cpu 메모리에 비교하면 상당히 빠른편
Shared Memeroy
글로벌 메모리(오프 칩)는 칩 안에 있지 않기 때문에 접근 시간이 많이 걸립니다. 그래서 GPU에서도 CPU처럼 캐시 기능을 사용할 수 있습니다.다른 점은 개발자가 캐시를 직접 제어할 수 있다는 점입니다.
블록 안의 스레드는 shared 메모리를 모두 공유합니다. (큰 메모리 개념)
블록은 블록마다 자신의 shared 메모리를 가집니다.
shared 메모리는 항상 __syncthreads() 함수를 사용해야 합니다. 왜냐면 shared는 global의 데이터를 캐시처럼 shared에 올린 뒤 사용해야 하는데, 각각의 스레드가 shared에 올리는 작업을 수행합니다.이 때 sync를 걸지 않으면, 모두 메모리에 올라오지 않은 상태에서 값을 참조하여 쓰레기값을 가져올수 있기 때문입니다.
Local arrays referenced with indices whose values cannot be determined at compile-time
Large local structures or arrays that would consume too much register space
Any variable that does not fit within the kernel register limit
Constant memory
상수 메모리는 device 메모리에 위치하며 각 SM 의 컨스턴트 캐시에 캐싱된다. (gpu그림에서 c캐시부분)
커널은 상수메모리를 읽을수만 있다.
상수메모리는 워프의 모든 스레드가 동일한 메모리를 읽을때 가장베스트하다고함. 한마디로 각각의 데이터에 대해 동일한 계산을 수행하기위해 동일한 계수를 사용하기 떄문.
추가적으로 GPU 구조 관련해서도 간단히 정리
**커널 함수 : 병렬 함수 및 데이터 구조를 명시하는 키워드들을 확장한 형태로 작성된 코드로서, 디바이스가 실행하는 부분 (병렬 처리가 가능한 부분)
** 스레드 : 최소 명령어 처리단위 , 기본연산(Computation) 하나라를 스레드로 표현한다. (= 멀티프로세서 내에서 작동되는 코어하나에 할당된 명령어를 의미) / 커널함수의 한 인스턴스로써 gpu의 sp에 의해 실행
** 블럭 : 스레드 묶음 (=그리드내의 스레드들을 적절한수의 스레드들로 분할한 단위로 하나의 sm에게 할당한다)
** 그리드 : 블록이 모이면 그리드가 된다. (하나의 병렬 커널에 의해 실행되는 스레드 전체를 의미함)
+)TPC 는 fermi 이전에 있던것
** 멀티프로세서 : GPU를 구성하는 기본요소로 구성된 최소돤위, GPU 는 멀티프로세서내에 여러개의 GPU 코어를 지니고있다.
**GPU는 1개칩안에 최대 15개의 멀티프로세서를 가지고있음. 이 멀티프로세서안에 각각 192개의 코어 (계산유닛)을 가지고있다 그러므로 총 2880개의 코어를 가지고있는셈
** 커널 : GPU에서 병렬실행하는 명령의모음
**Wave(=Wavefront = WARP) : 32개 스레드들을 단위로 묶은것 (갯수는다를수있음), 대부분 엔비디아 gpu 는 32스레드를 1개워프로 치고있다고 한다.
Warp는 SM(Streaming Multi-processor)의 기본 실행 단위(unit of execution). 스레드 블록의 그리드를 실행하면, 그리드의 스레드 블록들은 SM들로 분배됩니다. 스레드 블록이 SM에 스케쥴링되면 스레드 블록의 스레드들은 warp로 파티셔닝됩니다. 32개의 연속된 스레드들로 구성된 하나의 warp는 SIMT(Single Instruction Multiple Thread) 방식으로 실행됩니다. 즉, 모든 스레드는 동일한 명령어를 실행하고, 각 스레드는 할당된 private data에 대해 작업을 수행합니다.
+) GPU DEVICE 에는 4가지 타입의 캐시가 존재
각 SM에는 하나의 L1 캐시가 있고, 모든 SM에서 공유되는 하나의 L2 캐시가 있는데(그림참). L1과 L2 캐시는 모두 local / global 메모리에 데이터를 저장하는데 사용됨. GPU에서는 오직 메모리 load 동작만 캐싱될 수 있고 메모리 store 동작은 캐싱될 수 없다고함. SM 또한 read-only constant 캐시와 read-only texture 캐시가 있는데, 이는 device memory의 각각의 메모리 공간에서 읽기 성능을 향상되는데 사용된다.
cd /usr/local/cuda-11.4/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
4. 결과
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla T4"
CUDA Driver Version / Runtime Version 11.4 / 11.4
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 15110 MBytes (15843721216 bytes)
(040) Multiprocessors, (064) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 5001 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 65536 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 30
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.4, CUDA Runtime Version = 11.4, NumDevs = 1
Result = PASS
텐서 블록에는 3개의 내적 단위가 포함되어 있으며, 각 단위에는 10개의 8×8 승수와 3개의 선택적 누산기(ACC) 가 있음.
** DOT (곱셈) - 벡터끼리의 곱셈을 의미함
** 승수 : 승수란 어떤 수에 다른 수를 나누거나 어떤 식에 다른 식을 곱할 때, 그 나중의 수나 식을 말한다.
** ACC (누산기) : 연산된 결과를 일시적으로 저장해주는 레지스터로 연산의 중심
** 레지스터
레지스터는 비트 패턴을 저장하는 플립플롭 그룹입니다. FPGA의 레지스터에는 클럭, 입력 데이터, 출력 데이터 및 활성화 신호 포트가 있습니다. 클록 주기마다 입력 데이터가 래치되어 내부에 저장되고 출력 데이터가 내부에 저장된 데이터와 일치하도록 업데이트됩니다.
그림 3은 이 모드에서 AI 텐서 블록의 동작을 보여줌
각 주기에 내적 단위를 공급하는 레지스터 뱅크는 점선 상자로 표시됩니다. 3 클럭 사이클 후에 해당 피연산자의 모양과 색상을 사용하여 출력이 생성됩니다.
주황별 :역시 인풋벡터인데 무색 모양은 3개의 내적 단위로 브로드캐스트되는 텐서 블록의 데이터 포트에 대한 입력 벡터입니다.
유색원 : 레지스터 뱅크로 들어온 인풋벡터값
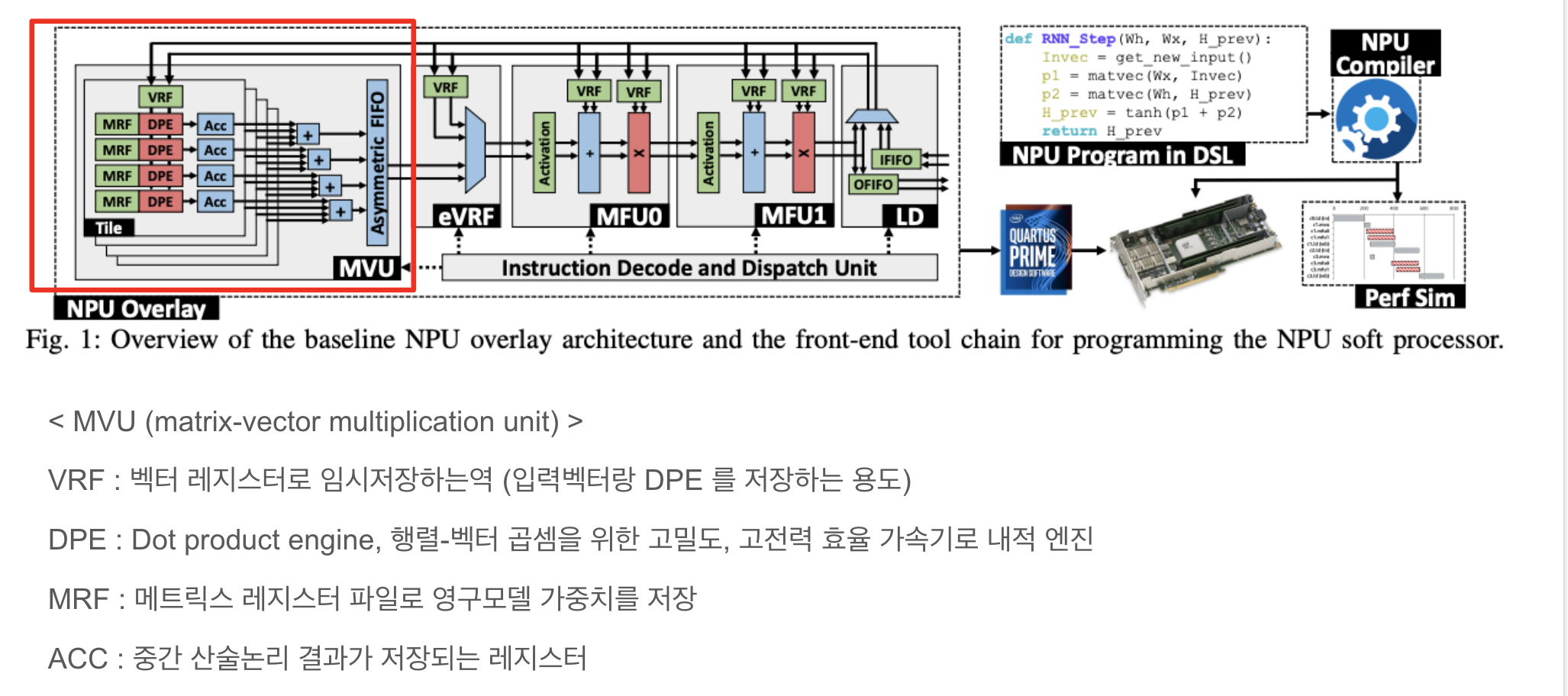
3. baseline 기반으로한 리얼구조
아까 베이스라인 npu 구조 에서 더 발전시킨것이 Stratix 10 NX Npu
** 타일이 왜 두개로 나뉨? (인풋레인이 2개라서)
베이스라인 NPU에서 2개의 타일 및 DPE를 갖는 MVU에 대한 매트릭스-벡터 연산의 매핑을 예제로 들고있다.
DPE는 여러 주기에 걸쳐 입력 벡터의 블록과 행렬 행 블록 간의 내적을 수행
그런 다음 다른 타일에서 해당 DPE의 출력을 줄여 행렬의 다음 행 블록으로 진행하기 전에 최종 결과를 생성
- 대신에 다음그림처럼 여러가지 결과를 저장하기위해 BRAM 기반 누산기(=MVU)를 구현. (BRAM = block ram)
- dual-port RAM. 듀얼 포트 램이므로 한 사이클에 2개의 주소로부터 값을 읽거나 쓰기가 가능
- BRAM 이 여기서 하는일은 기본적으로 스토리지의 역할을 하며 read/write 속도가 매우 빠르다고함/ On-Chip 메모리 ( 메모리가 칩위에 있다는 의미/ 메모리가 칩 위에 있기 때문에 버스(Bus)를 사용하지 않고 바로 메모리에 접근할 수 있다 / BRAM 은 기본적으로 FPGA안에 필요한 정보, data를 저장하는 공간이다 )
*BRAM ? Xilinx FPGA 내부의 SRAM 의 한 종류를 BRAM 이라 부릅니다. (Xilinx FPGA 에는 URAM 도 있습니다.) Intel FPGA 은 BRAM 역할을, Embedded Memory 라고 부르구요.
결과적으로 타일 간 감소를 수행하기 위해 각 타일에서 중앙 가산기 트리로 넓은 버스를 라우팅하면 상당한 라우팅 혼잡이 발생할 수 있습니다
라우팅 혼잡을 완화하기 위해 그림 4c와 같이 각 타일이 이전 타일의 결과를 가져오고 로컬 이진 축소를 수행하고 결과를 다음 타일로 전달하는 데이지 체인 아키텍처를 갖도록 MVU를 재설계합니다. .
이 아키텍처는 각각의 두 개의 연속 타일 사이에 더 짧고 더 지역화된 라우팅을 사용하며 몇 사이클 더 높은 대기 시간을 희생하면서 더 효율적이고 라우팅 친화적인 것으로 밝혀졌다.
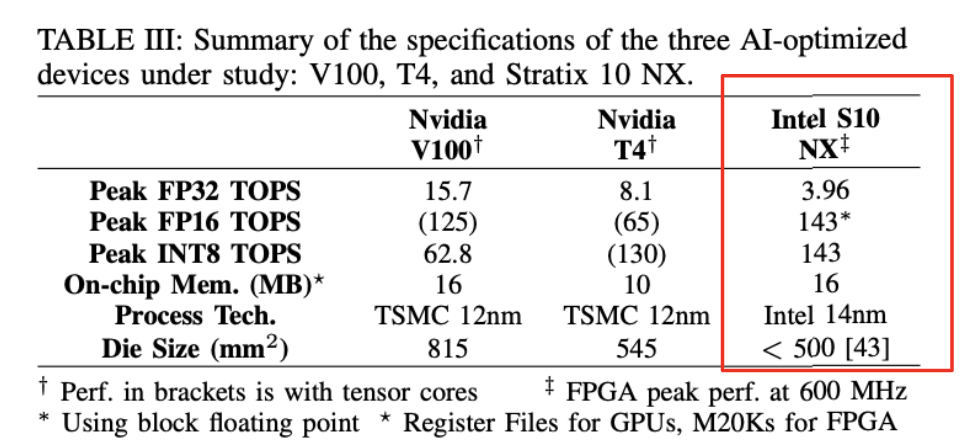
4. 성능비교
** ALM = 해당 제품군의 베이직 빌딩블록
** 빌딩블록 = 컴터를 구성하는 여러가지종류의 기본 회로들을 지칭함
** TOPS = 초당 1조 연산속도 (15TOPS = 1초에 15조번 연산)
**PEAK TOPS 는 MVU 에서만 국한지음
** GEMV = 일반 행렬곱
** GEOMEAN = 기하평균 ( n개 양수값을 모두 곱한다음 n제곱근을 구함)
** 1개의 배치로부터 loss를 계산한 후 Weight와 Bias를 1회 업데이트하는 것을 1 Step이라고 한다.